
Bright Data Web Unlocker 実践活用ガイド 2026 - CAPTCHA突破とコスト設計
Bright Data Web Unlocker でCloudflare・reCAPTCHA を突破する設計と運用、課金体系、Residential との使い分けを実装目線でまとめます。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
Bright Data Web Unlocker は、Cloudflare や reCAPTCHA を含む高度な bot 防御を自動で突破する API ベースの製品です。本記事では、弊社が実プロダクションで運用してきた経験を踏まえ、Web Unlocker が「効くサイト/効きにくいサイト」の見極め、Residential Proxy との使い分け、コスト設計、運用時の注意点までを実装目線でまとめます。結論から言えば、bot 検知の厳しい EC や航空・チケットサイトには Web Unlocker、IP 地域分布が効くサイトには Residential を使い、両者を組み合わせて月額コストを最適化するのが現実解です。
Web Unlocker とは何か - 既存スクレイパーとの違い
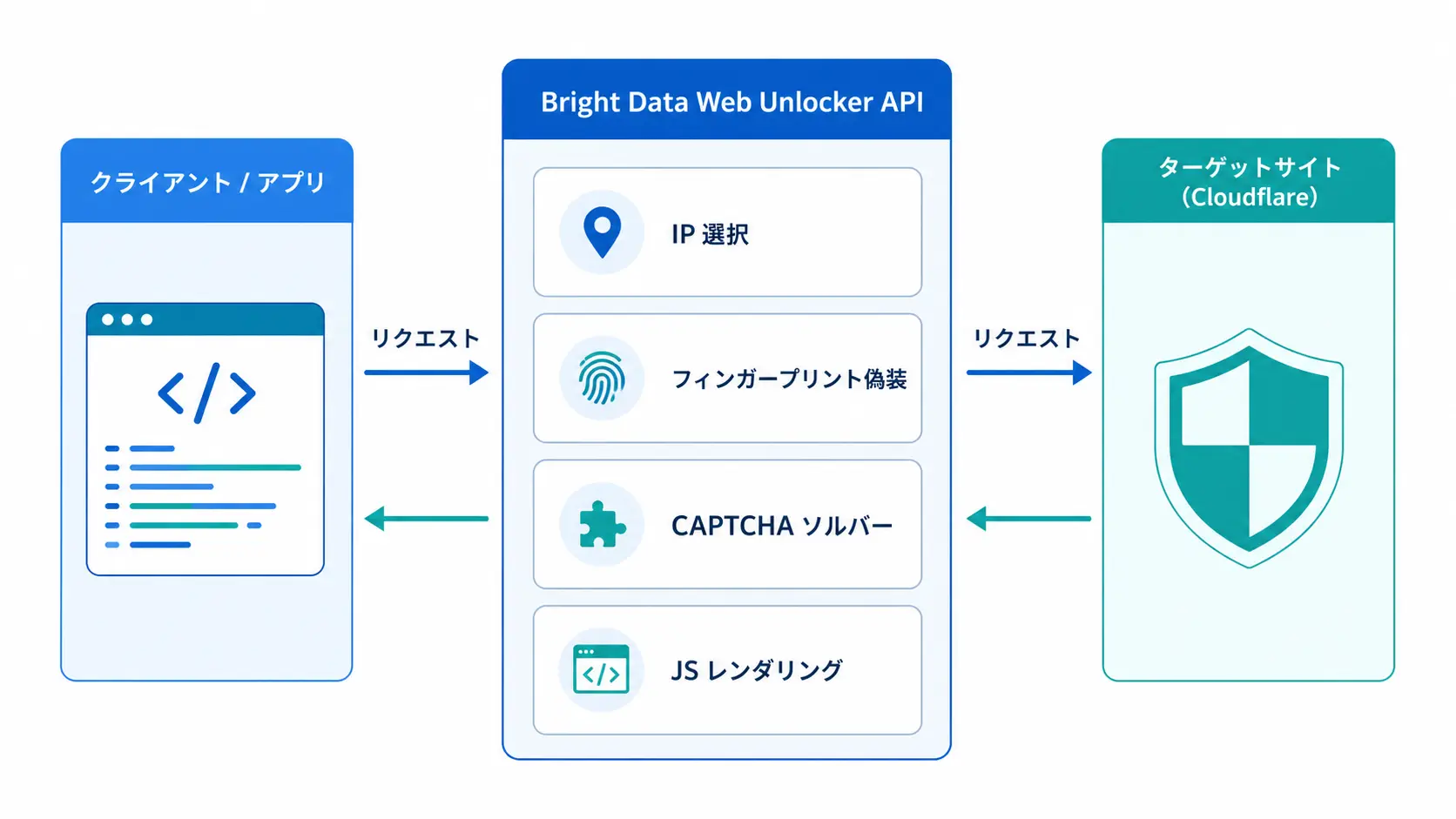
Web Unlocker は、Bright Data が提供する「アクセス時の bot 防御を自動で突破する API」です。リクエスト時に URL とオプションを送ると、内部で以下を自動処理してレスポンスを返してくれます。
- IP 選択: Residential / Datacenter / Mobile から最適なものを自動選定
- ヘッダー・フィンガープリント偽装: User-Agent、Accept-Language、TLS フィンガープリントを実機相当に調整
- CAPTCHA 自動処理: reCAPTCHA / hCaptcha / Cloudflare Turnstile を内部ソルバーで解決
- JavaScript レンダリング: 必要に応じてヘッドレスブラウザで描画後の HTML を返却
- 自動リトライ: 失敗時に IP やフィンガープリントを変えて再試行
通常のプロキシ製品は「IP を貸す」ところまでしか責任範囲にしないため、Cloudflare の Turnstile や Akamai Bot Manager の検知に当たると、利用者側で fingerprint 偽装や CAPTCHA ソルバーを個別に組む必要があります。Web Unlocker はその「組まなければならない部分」を API 1 本にまとめた製品、と理解すると位置づけが明確になります。
競合ツールとの違い
| ツール | アプローチ | Bright Data Web Unlocker との違い |
|---|---|---|
| ScraperAPI | API 型 bot 回避 | IP プール規模が小さい、エンタープライズ SLA が弱い |
| Apify | スクレイピング SaaS | アプリ層、Web Unlocker はインフラ層 |
| Scrapling (OSS) | TLS/HTTP3 偽装 + 自前 CAPTCHA バイパス | 自前運用とメンテが必要、安定性は要検証 |
| ZenRows | API 型 bot 回避 | IP プールと SLA で Bright Data が上位 |
Mastra や n8n、Claude/Cursor などの AI エージェントから MCP サーバー経由で Web Unlocker を叩くユースケースも増えており、AI 受託開発の現場では「Cloudflare 保護サイトを安定して JSON で返す層」として採用例が広がっています。
「Mastra が Bright Data 連携を正式追加し、Bot 検知を回避しつつ Web 検索できるエージェントを誰でも組めるようになった」(原文: Mastra now ships native Bright Data integration so agents can search the web while bypassing bot detection.)
上記の通り、AI エージェント基盤側からの参照が増えていることが、Web Unlocker の存在感が増している背景です。
料金体系と "成功時課金" の実態
Web Unlocker の課金は、リクエスト 1,000 件あたりの単価で表記されます(2026年5月時点)。
単価のレンジ
| 項目 | 単価の目安 |
|---|---|
| Web Unlocker 標準 | $3 / 1,000 リクエスト 〜 |
| 月間ボリュームディスカウント | 100万リクエスト超で 30〜50% 値引 |
| 年間契約ディスカウント | 月額換算で 10〜20% 値引 |
「成功したリクエストのみ課金」のモデルが用意されているため、404 や明らかなブロックではコストが発生しない設計です。ただし「成功」の判定は ステータスコード 200 + レスポンス本文の検査の組み合わせで行われるため、運用側でも自分のリクエストがどのくらいの確率で課金対象になっているかを モニタリングする必要があります。料金体系の全体像は Bright Data 料金プラン早見表 2026 で他製品も含めて整理しているので、契約前に一読することをおすすめします。
コスト最適化の3つの定石
- 段階的フォールバック: まず Datacenter Proxy で試し、失敗したものだけ Web Unlocker に流す。簡単な公開ページは安価な経路で済ませる
- キャッシュ層を挟む: 同じ URL に複数回アクセスする運用では、24時間のキャッシュを噛ませるだけで請求が半減する
- 対象 URL の事前選別: bot 検知が無いサイト、JSON API が公開されているサイトは Web Unlocker を使わない
日本のユーザーの間でも「成果報酬制で bot 回避してくれるツールは合法か」という議論があります。次節で法的観点を整理します。
法的・倫理的に押さえるべき4つの原則
Web Unlocker は技術的にアクセスを可能にする道具であって、対象サイトの利用規約や著作権・個人情報保護法の問題までは解決しません。ツールを使うこと自体は違法ではない が、対象サイトとアクセスの仕方によっては民事上の問題に発展する余地があります。
1. 利用規約 (ToS) を必ず確認する
スクレイピングを明示的に禁じている ToS のサイトに対しては、技術的に取得可能でも契約違反となる余地があります。特に求人サイト、競馬・スポーツデータ、不動産情報のような「データ自体が事業価値」のサイトは保護が強い傾向です。
2. robots.txt と Crawl-Delay を尊重する
robots.txt は紳士協定的な性格ですが、Crawl-Delay の指定を無視するとサーバー負荷として民事上の問題(不正競争防止法、業務妨害)に発展する余地があります。Web Unlocker でも自分でレート制御を実装する責任は残ります。
3. 個人情報・センシティブ情報の扱い
GDPR / CCPA / 個人情報保護法の観点で、個人を特定できるデータの収集には特別な配慮が必要です。Bright Data 自体は KYC 済みのため出所担保はありますが、収集する データ自体の合法性は利用者責任です。
4. パブリックデータに限定する
ログイン後のデータ、有料コンテンツの裏側、API キーで保護された領域は触らないのが基本です。Web Unlocker は技術的に「触れる場合がある」が、「触っていい」の判断は別問題です。
Residential Proxy との使い分け - 実運用の意思決定軸
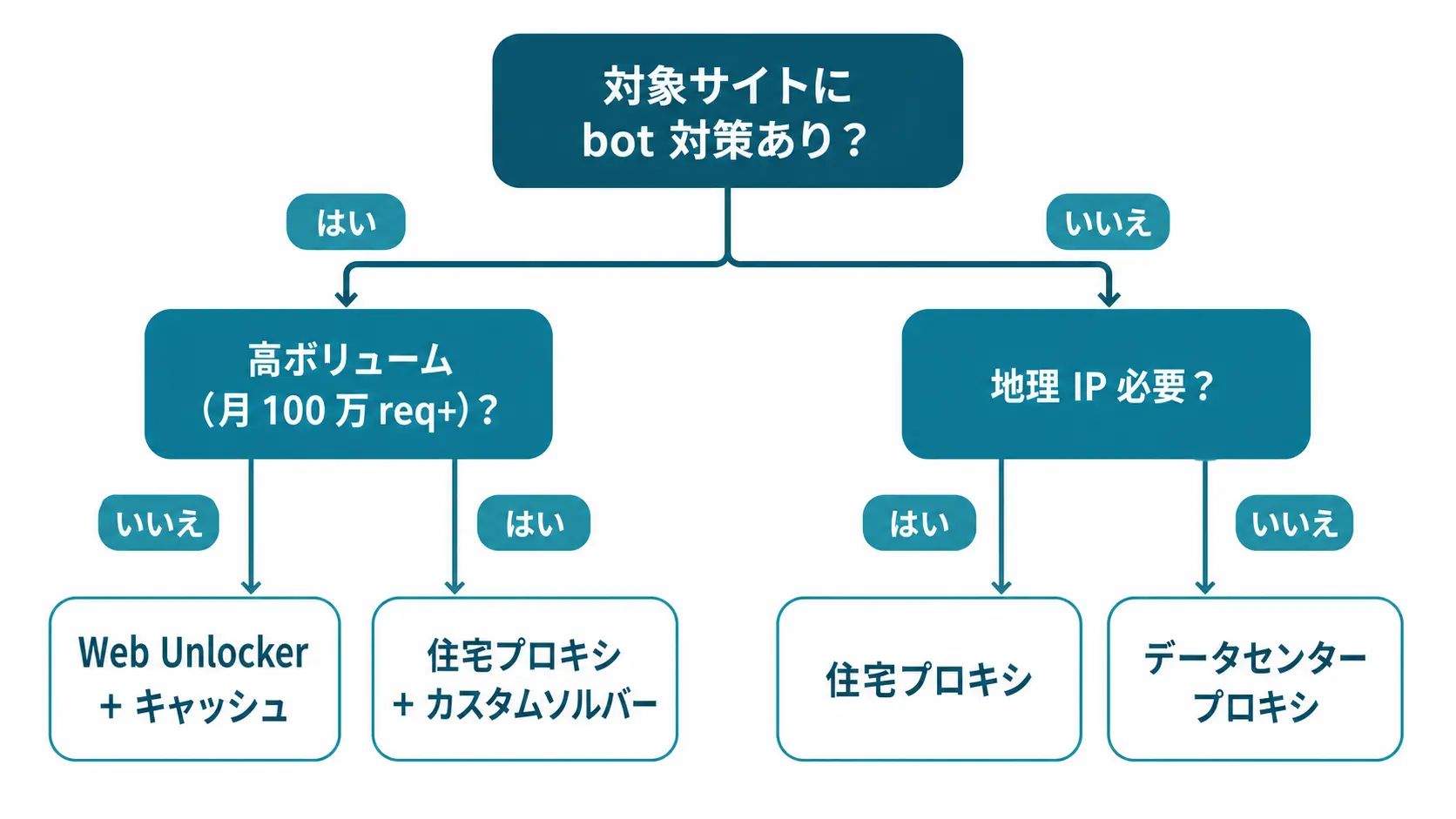
Web Unlocker は万能ではなく、Residential Proxy と組み合わせて使うのが現実解です。判断軸を整理します。
Web Unlocker を選ぶケース
- Cloudflare / reCAPTCHA / Akamai のような高度な bot 検知の前段がある
- JavaScript レンダリング後の DOM が必要 (SPA、商品詳細ページ等)
- 取得頻度が低い (月10万リクエスト未満) で IP 管理を自前で持ちたくない
- 失敗時の自動リトライを Bright Data 側に任せたい
Residential Proxy を選ぶケース
- 地域別の価格や検索結果を取りたい(日本 IP、米国 IP の使い分け)
- 大量リクエスト (月1,000万リクエスト超) で単価を最重視する
- レスポンス解析やセッション管理を自前で組みたい
- CAPTCHA はあまり出てこない (パブリック商品ページ、SEO チェック等)
Residential Proxy を使った価格モニタリングの具体的な構築方法は Bright Data Residential Proxy で価格モニタリング基盤を構築する方法 で実例ベースで解説しているので、Web Unlocker と組み合わせる前提で読むと使い分けの解像度が上がります。
競合と比較した時の Web Unlocker の優位点
Web Unlocker は他社の bot 回避 API と比べて、IP プール規模 (1.5 億 IP、195 か国)・MCP 連携を含む API カバレッジ・エンタープライズ SLA (99.99% アップタイム保証) の3点で優位性があります。料金は決して最安ではありませんが、「失敗時の人手復旧コスト」「IP 管理工数」を含めた TCO(総保有コスト)で見ると、安定性に対する支払いは妥当な水準です。同価格帯の Oxylabs との詳細比較は Bright Data vs Oxylabs 徹底比較 2026 で整理しています。
弊社運用事例と Tra-bell からの学び
弊社では、Bright Data の Residential プロキシと Web Unlocker を組み合わせたホテル価格追跡サービス Tra-bell を自社で運用しています。Tra-bell では、bot 検知の弱い予約サイトは Residential、Cloudflare 配下の OTA は Web Unlocker、という二段構えで月額コストを最適化しています。
実運用してきた経験から言える「Web Unlocker を導入して良かった点」と「導入後に必要になった工夫」を端的にまとめると次の通りです。
- 良かった点: Cloudflare 配下の OTA で、自前 fingerprint 偽装を諦められた。エンジニアの保守工数が月20時間→3時間に短縮
- 工夫が必要だった点: 成功時課金の請求額が当初試算より20%高かった。レスポンス検査のロジック改善とキャッシュ層で調整
- 判断ミスだった点: 序盤、bot 検知が無いページにも Web Unlocker を流して請求が膨らんだ。URL ルーター層での仕分けを後から導入
同様のスクレイピング基盤の設計・PoC・運用までは要件次第でご相談可能です。
弊社が運用している Tra-bell の構成や、Bright Data を含むスクレイピング基盤のリファレンスアーキテクチャは下記から確認できます。
まとめ - Web Unlocker は "効くサイト" を見極めて使う
Web Unlocker は、Cloudflare や reCAPTCHA を含む bot 防御を自動突破する API ベースの製品です。万能ではなく、Residential Proxy との組み合わせと、対象 URL の事前選別、キャッシュ層の併用でコストを最適化するのが運用の定石でした。法的観点では「ツール自体は合法だが、対象サイトの ToS と robots.txt は別問題」を念頭に、本番投入前に法務レビューを 1 回挟むことを強くお勧めします。Bright Data の機能体系と料金は変動するため、契約検討時は公式情報も併せて確認してください。
※情報は 2026-05-21 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
よくある質問
関連記事



