Bright Data で CAPTCHA に遭遇したときの対処レシピ 2026 - 種類別の設定と回避策
Bright Data のスクレイピングで reCAPTCHA・hCaptcha・Cloudflare Turnstile に遭遇したときに、Zone 設定・Web Unlocker・Scraping Browser・3rd party solver をどう組み合わせるかをトラブルシュート目線で整理します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
Bright Data でスクレイピングしていると、ある日突然 reCAPTCHA や Cloudflare のチャレンジが返ってきて取得が止まる、というのはよくある話です。本記事では、CAPTCHA に遭遇した瞬間の切り分けから、種類別 (reCAPTCHA v2/v3、hCaptcha、Cloudflare Turnstile) の対処レシピ、Bright Data の Zone 設定と Scraping Browser / Web Unlocker / 外部ソルバーの組み合わせ判断までを、弊社が Tra-bell の運用で蓄積したノウハウを踏まえて整理します。結論を先に言えば、Scraping Browser または Web Unlocker を主軸にしつつ、抜けない URL だけ 2Captcha などの専用ソルバーへフォールバックする二段構成 が現実解です1。
CAPTCHA に遭遇したときの最初の切り分け
CAPTCHA が出たという事象を見たら、いきなり対策ツールを増やす前に、何が出ているのか・どの層で出ているのかを切り分けます。ここを飛ばすと「Scraping Browser に変えたが今度は別の challenge が出る」という袋小路に入ります。
出ている CAPTCHA の種類を特定する
レスポンス HTML やヘッダを見れば、ほぼ確実に判別できます。主な指紋は次の通りです。
- reCAPTCHA v2:
<script src="https://www.google.com/recaptcha/api.js">やg-recaptchaクラス、画像クリック型 UI - reCAPTCHA v3: 同じ
recaptcha/api.jsだがバッジが右下に出るだけ、UI 操作を要求しない (リスクスコア型) - hCaptcha:
hcaptcha.com/captchaドメイン、h-captchaクラス - Cloudflare Turnstile / Managed Challenge:
challenge-platformパスやcdn-cgi/challenge-platform、__cf_bmクッキー - Akamai Bot Manager:
_abckクッキーとbm-で始まる JS、Sensor Data の POST - PerimeterX (HUMAN):
_pxクッキーとclient.perimeterx.netの参照
検知のトリガーを推定する
CAPTCHA は「アクセス即発火」と「リスクスコア超過時に発火」の 2 系統があります。Residential プロキシで初回アクセスから challenge が出るならアクセス即発火型 (Cloudflare/Akamai が多い)、何百リクエスト目から急に出るならスコア超過型 (reCAPTCHA v3 / hCaptcha Enterprise / PerimeterX) です。前者は IP・TLS 指紋を整える方向、後者はセッション継続性と人間らしい挙動を作る方向で対処方針が変わります2。
「Bright Data の Scraping Browser は住宅プロキシ + 真正なブラウザ指紋偽装で CAPTCHA 触発率自体を下げ、発火時も自動処理してくれるため成功率 99% 超を出せる」(原文: Bright Data's Scraping Browser combines residential proxies with realistic browser fingerprinting to prevent CAPTCHAs from triggering, and auto-handles them when they do — reaching 99%+ success.)
上記の X 投稿でも触れられているように、Bright Data の Scraping Browser は 予防 (発火させない) と 突破 (発火後の処理) を 1 つの API でまとめている のが他のプロキシ単体製品との大きな違いです。CAPTCHA の種類別の機能比較は Bright Data Web Unlocker 実践活用ガイド 2026 でも整理しているので、製品選定で迷っている方はあわせて確認してみてください。
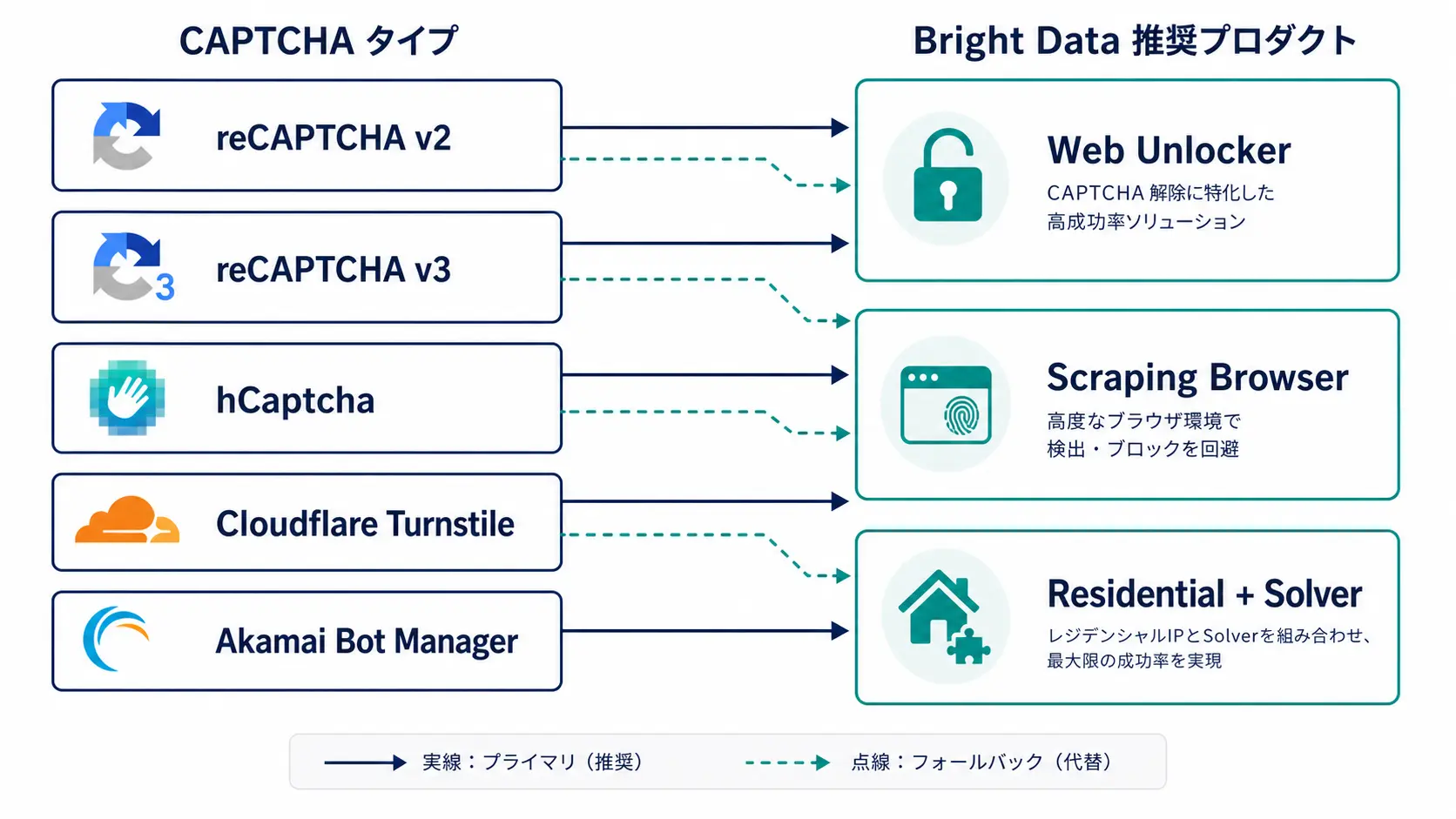
種類別の対処レシピ - 何を選んで何を捨てるか
切り分けが終わったら、種類ごとに「どの Bright Data 製品で受けるか」を決めます。やみくもに Scraping Browser を当てるとコストが急増するため、対象 URL の重要度と通信量で配分を変えるのが定石です。
reCAPTCHA v2 (画像クリック型)
UI 操作の擬似化が必要なので、HTTP ベースのプロキシだけでは抜けません。Scraping Browser に描画させて DOM 操作で reCAPTCHA フレームを処理するか、reCAPTCHA トークンを 2Captcha などのソルバーで取得して g-recaptcha-response に注入する 2 通りが現実解です。Bright Data の Scraping Browser は内部で挑戦を解こうとしますが、解けない場合は 2Captcha API を solve イベントから手動 hook するハイブリッド構成が安定します。
reCAPTCHA v3 (リスクスコア型)
スコア (0.0〜1.0) で判定されるため、突破するのではなく「高スコアを獲得する」設計です。具体的には次の 3 点をすべて満たします。
- Residential プロキシで自然な ASN・国を使う: データセンター IP は減点される
- navigation の間隔を 800ms〜3,000ms にランダム化: 即時遷移は機械判定される
- 同一セッションで cookie を維持し、過去訪問履歴を作る: 初回 → 再訪 → 操作の流れで信頼度が上がる
Scraping Browser の userDataDir をユーザー単位に固定するか、Bright Data のセッション保持機能で 30 分〜数時間の長期セッションを張るのが効きます。
hCaptcha
reCAPTCHA v2 と同様 UI 操作型ですが、画像認識タスクがやや難しめ。Bright Data の Web Unlocker は内部に hCaptcha 解析モジュールを持ち、API 1 本で透過的に解けるケースが多いです。Web Unlocker で抜けない hCaptcha Enterprise / Pro モードに対しては Capsolver や 2Captcha の hCaptcha API を組み込みます。
Cloudflare Turnstile / Managed Challenge
Web Unlocker の最も得意な領域です。JavaScript challenge を内部で処理して __cf_bm クッキーを取得した状態で HTML を返してくれます。直接 Residential で叩いても challenge ページしか返らないので、Cloudflare 保護サイトは原則 Web Unlocker か Scraping Browser に寄せます。なお、Cloudflare の Managed Challenge は数か月単位でアルゴリズム更新があるため、運用には成功率モニタリングが必須です。
Zone とリクエストパラメータの実装ポイント
Bright Data の Zone は、製品 (Residential / Web Unlocker / Scraping Browser) ごとに作る単位ですが、同じ製品でも用途別に Zone を分けるのが運用上のセオリー です。CAPTCHA 対策に直結する設定を整理します。
Web Unlocker の Zone で押さえる項目
ダッシュボードで Web Unlocker Zone を作る際、最低限見るべき項目は以下です。
| 項目 | 推奨値 | 理由 |
|---|---|---|
| Country | 対象サイトの主要利用国 | 例: jp.amazon.co.jp なら JP |
| Render JavaScript | On | SPA / Cloudflare 保護サイトに必須 |
| Reject responses by HTTP status | 403, 429, 503 | 失敗を成功扱いされない |
| Async API | 必要に応じて | 長時間描画ページで利用 |
Reject 設定をしないと CAPTCHA ページの HTML を「成功」として課金されることがあります。コスト最適化 = 課金される成功条件を厳密に定義 という観点で必ず入れます。
Scraping Browser の接続パラメータ
Playwright や Puppeteer で connect_over_cdp する WebSocket エンドポイントは、Zone のユーザー名と国・セッション ID で URL が変わります。代表的な接続例:
from playwright.sync_api import sync_playwright
BD_USER = "brd-customer-XXXX-zone-scraping_browser1"
BD_PASS = "your_password"
BD_HOST = "brd.superproxy.io:9222"
SESSION_ID = "session_001" # 長期セッションで再利用
endpoint = (
f"wss://{BD_USER}-session-{SESSION_ID}:{BD_PASS}@{BD_HOST}"
)
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp(endpoint)
context = browser.new_context()
page = context.new_page()
page.goto("https://example.com/login", wait_until="domcontentloaded")
page.wait_for_timeout(2500) # スコア型対策で揺らぎを入れる
html = page.content()
SESSION_ID を固定すると同一 IP / 同一ブラウザ指紋を再利用できるため、リスクスコア型 (reCAPTCHA v3 / PerimeterX) で重要です。逆に IP ローテーションが必要なケースでは session を毎回切り替えます。
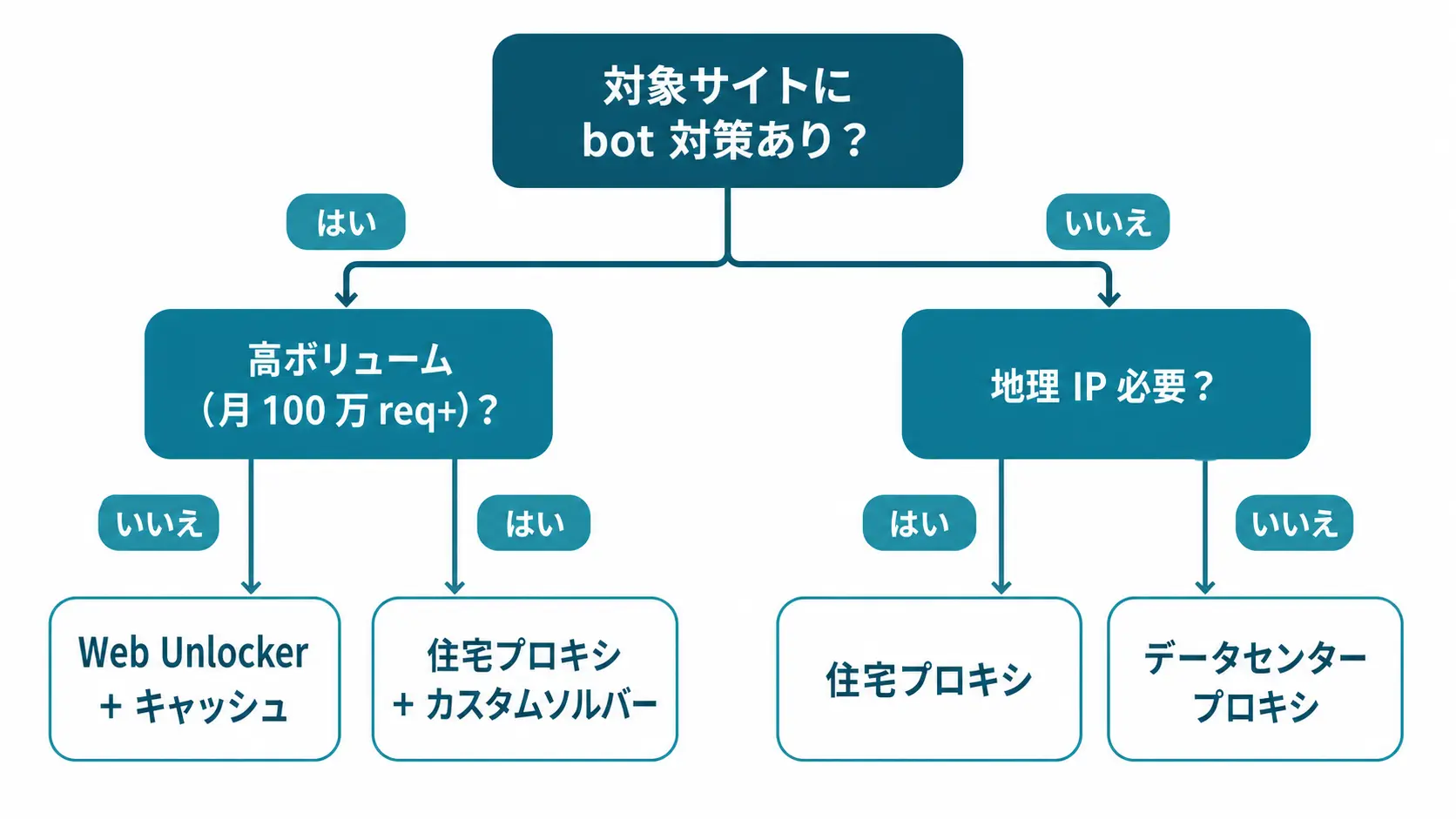
外部ソルバーとのハイブリッド構成
Bright Data 単体で抜けない URL に出会った場合、Scraping Browser から CAPTCHA フレームの sitekey を抽出し、2Captcha / Capsolver の API に投げてトークンを取得、戻ってきた g-recaptcha-response を DOM に注入してフォームを送信する流れになります。Bright Data 公式の Auto Solve も同じ仕組みを内部で持っていますが、Auto Solve で抜けない難関サイトはユーザー側で sitekey ベースのフォールバックを書くのが安全策です。Residential と ISP の使い分け基準は Bright Data Residential と ISP プロキシの使い分け実践ガイド 2026 で詳しく整理しているので、Zone 設計で迷う場合は参考にしてください。
「大規模スクレイピングで bot 対策を抜けるには Bright Data のような企業級プロキシと CAPTCHA solver を組み合わせるのが現実解で、単一ツールでは大手サイトの保護を突破しきれない」(原文: For serious scraping you need to combine an enterprise proxy like Bright Data with a CAPTCHA solver — no single tool reliably breaks through large-site protections on its own.)
上記の X 投稿でも、CAPTCHA を含む bot 対策は単一ツールで解決しきれず、複数ツールのオーケストレーションが現実解だと触れられています。
失敗パターンと運用上の注意点
ここまでの設計で多くのケースは抜けますが、運用で繰り返し遭遇する地雷を共有します。
よくある失敗
- 同一 IP で連続アクセスを続けて急にブロックされる: ISP プロキシや短時間セッションで起きやすい。アクセス頻度の自動調整 (Token Bucket) を入れる
- Web Unlocker の "成功" 判定で CAPTCHA HTML が課金された: Reject 設定と本文の検査 (
captcha文字列の有無など) を組み合わせる - Scraping Browser でメモリ使用量が伸びる: 長期セッションの DOM 蓄積が原因。一定リクエストごとにブラウザを再起動する
- 2Captcha のレスポンス時間に引きずられて全体スループットが落ちる: 並列度を上げるか、ソルバー使用率を下げる方向で再設計
- CSS 変更だけで sitekey 抽出が壊れる: 抽出ロジックは DOM 構造に依存しすぎないよう attribute ベースに
成功率をモニタリングする
CAPTCHA 対策は「設計して終わり」ではなく、サイト側の更新で月単位に成功率が変動します。最低限のメトリクスとして、1 時間ごとの URL 別成功率、月次の Zone 別コスト、失敗時の HTTP ステータス分布 をダッシュボード化しておくと、Cloudflare のアルゴリズム更新で成功率が急落しても 24 時間以内に気付けます。
弊社のスクレイピング支援と Tra-bell の事例
スマイルコンフォートは Bright Data の Residential / Web Unlocker / Scraping Browser を業務として運用してきた経験があり、CAPTCHA 対応の設計・PoC・本番投入の伴走を提供しています。自社運用プロダクトの Tra-bell (ホテル価格追跡サービス) も Bright Data の Residential と Web Unlocker を組み合わせたスクレイピング基盤の上で動いており、Cloudflare / reCAPTCHA / 独自 bot 検知に遭遇する大手 OTA を含めて月次の成功率を維持する仕組みを実装・運用しています。
CAPTCHA で詰まっている案件、コストが想定より膨らんでいる案件は、Zone 配分と Scraping Browser + 外部ソルバーのハイブリッド設計を見直すだけで成功率と単価が両方改善するケースが多いです。
まとめ
CAPTCHA に遭遇したときの動きは、(1) 種類とトリガーの切り分け、(2) Bright Data 製品の配分決定 (Web Unlocker / Scraping Browser / Residential)、(3) 抜けない URL に対する外部ソルバーのフォールバック、の 3 ステップに収束します。reCAPTCHA v3 や Cloudflare Turnstile のように年々アルゴリズムが進化する領域は、単一の銀の弾丸ではなく、Zone 設計とモニタリングで成功率を維持し続けることが重要です。Bright Data の Scraping Browser を起点にしつつ、必要に応じて 2Captcha / Capsolver と組み合わせる二段構成を、まずは PoC でコストと成功率の損益分岐を測ってから本番に乗せましょう。
※情報は 2026-05-21 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
Footnotes
-
Bright Data Scraping Browser overview — https://brightdata.com/products/scraping-browser ↩
-
Bright Data Web Unlocker documentation — https://docs.brightdata.com/scraping-automation/web-unlocker ↩
よくある質問
関連記事

Bright Data Web Unlocker 実践活用ガイド 2026 - CAPTCHA突破とコスト設計