
Bright Data Datacenter Proxy 大量並列設計ガイド 2026 - 並列度・帯域・コストの三軸設計
Bright Data Datacenter Proxy で 1 万並列を捌くための Zone 設計・並列度チューニング・コスト管理を、実運用目線で整理します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
Bright Data の Datacenter Proxy は、生の速度・並列度・GB 単価が必要なときの第一選択です。本稿は 1 万並列規模のスクレイピングを Datacenter Proxy で安定運用するための Zone 設計、並列度チューニング、コスト管理を実運用目線で整理します。検知耐性が落ちる弱点をどうフォールバックで補うかまで含めて、料金以上の価値を引き出す設計指針を示します。

Datacenter Proxy が「大量並列」に向く理由
Datacenter Proxy は、クラウド事業者やコロケーション事業者が運用するデータセンター内の IP を経由するプロキシです。出口 IP はサーバー由来のため、Residential のような家庭回線特有の不安定さがなく、ギガビット帯域とミリ秒単位のレイテンシで動作します1。
高いスループットと安定性
家庭回線を経由しないため、1 IP あたりの帯域は数百 Mbps〜1 Gbps クラスを安定的に出せます。スパイク的なバーストリクエストや長時間のクロールでも、回線がドロップするリスクは Residential より大幅に小さくなります。
Bright Data の Datacenter プランでは、共有 IP プールに加えて専用 IP (Dedicated) を選択でき、IP の鮮度・隔離レベル・スループット要件に合わせて使い分け可能です。
並列接続数の上限が緩い
Residential プロキシは「同時にアクティブな peer 数」が暗黙の上限になり、急激な並列増は IP プールを枯渇させます。Datacenter Proxy は IP がサーバー側で常時稼働しているため、Zone 単位で 1 万を超える同時接続も現実的です。アカウント全体の帯域上限と IP 数で決まる構造のため、設計時にこの 2 つを軸に並列度を割り出せます。X 上では Datakazkn 氏が「Enterprise 級のスクレイピングは 1M+ items/月でも予測可能な SLA で運用できる」と述べており、月間 100 万件超でも Zone 設計を整えれば予測可能な SLA で回せることが示唆されています。
「Bright Data の Datacenter は大量並列に強く、1 か月で 100 万件超のスクレイピングを予測可能な SLA で回せる」(関連投稿の趣旨: Bright Data datacenter proxies handle high concurrency well, with predictable SLAs even at 1M+ items per month.)
実運用では、Zone 当たり 500〜2,000 RPS (Requests Per Second) が現実的なレンジです。これ以上の並列を 1 Zone に集中させると Rate Limit や bot 検知に引っかかりやすくなるため、用途別の Zone 分割で水平展開します。
GB 単価がボトムレンジ
Datacenter Proxy の GB 単価は $0.5/GB 前後からスタートし、Residential の概ね 1/6〜1/9 程度に抑えられます2。データ量が大きく、検知耐性をそこまで重視しないユースケース (社内データ、軽い EC サイト、メディア記事の本文取得など) では、コストパフォーマンスを大きく引き出せます。
具体的な料金体系・契約形態・ボリュームディスカウントは Bright Data 料金プラン早見表 2026 で整理していますので、コスト試算時に合わせて確認してください。
1 万並列を捌く Zone 設計
並列度を稼ぐためには、Zone を「ターゲットサイトのカテゴリ × プロキシタイプ × IP プールサイズ」の組み合わせで分割するのが定石です。1 つの Zone に何でも詰め込むと、ブロック影響と Rate Limit が全体に波及します。
用途別 Zone 分割の指針
| Zone の役割 | 推奨プロキシタイプ | IP プールサイズ | 想定 RPS |
|---|---|---|---|
| 低検知サイト (内部 / 軽 EC) | Datacenter (共有) | 100〜500 | 1,000〜2,000 |
| 中検知サイト (一般 EC / ニュース) | Datacenter (専用) | 500〜2,000 | 500〜1,000 |
| 高検知サイト (大手 EC / SaaS) | Residential / Web Unlocker | 動的 | 100〜500 |
| ログイン後セッション | ISP / Sticky Residential | 100〜300 | 50〜200 |
低検知サイトは Datacenter の共有 IP で大量並列を走らせ、検知が上がってきたら専用 IP に切り替え、それでもブロックされる場合は Residential / Web Unlocker にフォールバックさせる 3 段構成です。Residential / ISP の使い分けは別記事 Bright Data Residential と ISP プロキシの使い分け実践ガイド 2026 で具体的な閾値と切り替え基準を示しているので、フォールバック設計の参考にしてください。
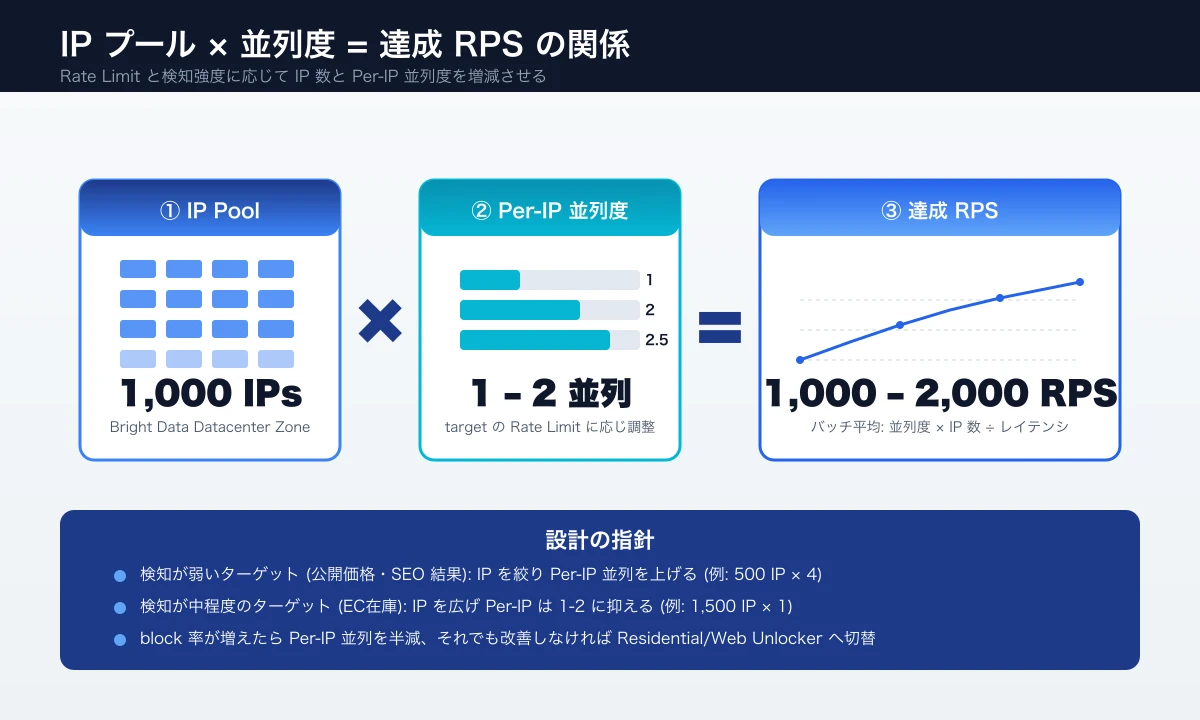
IP プールサイズと並列度の関係
「IP プール 1,000、RPS 2,000」を狙う場合、IP 当たり 2 並列が平均値です。実際にはサイト側の Rate Limit (例: IP 当たり 60 RPS) に達しないように、IP 当たり 0.5〜2 並列 で設計するのが安全圏です。並列度を上げたい場合は IP 数を増やすのが正攻法で、IP 当たりの並列度を引き上げるのは検知強化サイトでブロックリスクを高めます。
Proxy Manager で並列度を制御する
Bright Data の Proxy Manager を使うと、Zone ごとに最大同時接続数・リトライ・タイムアウト・ローテーション間隔を集中制御できます。自前の HTTP クライアントで実装する場合と比べて、エラーハンドリングの一貫性とログ可視化の手間が格段に減ります。
具体的な Zone 設計手順は Bright Data Proxy Zone の設計と作成完全ガイド 2026 でステップごとに整理しています。新規 Zone 作成・認証設定・Zone 別ログ分離まで含めて手順化したい方は併せて参照してください。
並列度を引き上げる運用テクニック
Zone 設計だけでは引き上げきれない並列度を、実装層で稼ぐためのテクニックを整理します。
Step 1. リクエストレイヤーで非同期化する
Python なら asyncio + httpx、Node.js なら Promise.all + axios で並列化します。同期 IO で 1 万並列を狙うとスレッド数が爆発するため、非同期 IO で 1 プロセス内に並列ジョブを集約するのが基本です。
- リトライ・タイムアウトを
asyncio.timeoutやhttpx.AsyncClient(timeout=...)で必ず設定する - プロキシ認証情報は環境変数で渡す (
session-idを用途別に分離する) - 失敗ステータス (HTTP 403/429, CAPTCHA HTML) を検知したら Residential Zone へ自動フォールバック
Step 2. キューと Worker を分離する
リクエストを発行する Worker と、結果をパースして DB / S3 に書き込む Consumer を分離すると、I/O 待ちで Worker が止まりません。Redis / SQS / Cloud Tasks を中間に置き、Worker 側は Pull 型で並列度を制御します。
- キューに URL とメタデータを Enqueue
- Worker (例: 200 並列) が Pull → リクエスト → 結果をキューに戻す
- Consumer が結果をパース → BigQuery / Snowflake / S3 に書き込み
この構成にしておくと、Worker のオートスケール (例: Kubernetes HPA) も自然に組み込めます。
Step 3. バックオフ付きリトライと SLO 管理
エラー率を SLO (例: 成功率 95% 以上) として監視し、SLO を下回ったら自動的に並列度を絞るフィードバックループを組みます。Datacenter Proxy の場合、IP プールの一部が一時的にブラックリスト入りするケースがあり、急激なエラー率上昇は IP 単位ではなく Zone 単位で起こります。
適用判断と AI エージェント連携でのコスト管理
X 上では「Datacenter Proxy は小規模だと過剰投資」という声もありますが、規模次第で判断は変わります。AI エージェント文脈では Datacenter の安さが効いてくる新しいユースケースも増えており、両方をまとめて整理します。
規模で見る向き不向き
「Bright Data は 1 万ページ規模の小プロジェクトには過剰でコスト高。Crawlee / Stagehand / Camoufox / FlareSolverr / Scrapling で十分なケースが多い」(関連投稿の趣旨: Bright Data is overkill and expensive for small projects like 10k pages. Open-source tools like Crawlee, Stagehand, Camoufox, FlareSolverr, or Scrapling are popular.)
| プロジェクト規模 | 月間ページ数 | 推奨スタック |
|---|---|---|
| 小規模 (PoC・個人) | 〜10 万 | OSS + 軽量プロキシ (Smartproxy / Decodo 等) |
| 中規模 (社内・スタートアップ) | 10 万〜100 万 | Datacenter Proxy + Residential フォールバック |
| 大規模 (エンタープライズ) | 100 万〜 | Bright Data 統合 (Datacenter + Residential + Web Unlocker + MCP) |
中規模以上では、IP プール規模・コンプライアンス (KYC)・SLA の 3 点で Bright Data の Datacenter Proxy を主役にする経済合理性が残ります。
LLM エージェントから動的に発火するスクレイピング
2026 年は LLM エージェント (AutoGen, LangGraph, Claude Code 等) から動的にスクレイピングを発火させるユースケースが急増しており、コスト予測性のために Datacenter を主軸に据える設計が現実的です。
「Bright Data の MCP サーバーは LLM エージェント向けにプロキシを自動ローテーションし、検知や CAPTCHA を自動処理する」(関連投稿の趣旨: Bright Data's MCP server automatically rotates proxies and handles challenges for LLM-powered agents.)
Bright Data の MCP サーバーは、LLM エージェントから呼び出された際にサイトの検知強度を内部判定し、Datacenter / Residential / Web Unlocker を含む適切なプロキシタイプを内部で選択する仕組みを備えています。低検知ターゲットの大半は Datacenter にルーティングされる構造のため、コスト予測性が上がります。詳細は MCP サーバーで AI Agent にスクレイピングを任せる実践ガイド 2026 を参照してください。
弊社の運用知見と支援メニュー
弊社では、Bright Data の Datacenter / Residential / Web Unlocker を組み合わせた本番スクレイピング基盤を複数案件で運用してきました。自社運用プロダクト Tra-bell では、Datacenter を主役に据えてホテル価格モニタリングを月間数千万リクエスト規模で稼働させています。
新規導入時の Zone 設計・並列度チューニング・コスト最適化・PoC から本番への移行支援を承っています。AWS / GCP 上のスケーラブルなスクレイピング基盤、BigQuery / Snowflake へのパイプライン構築まで一括でご相談ください。コスト面では コスト最適化テクニック 2026 で具体的な削減手順を整理しています。
まとめ
Bright Data の Datacenter Proxy は、「速度・並列度・GB 単価」を必要とする大量スクレイピングの主役です。Zone を用途別に分割し、IP プールサイズと並列度を設計したうえで、検知が強くなったら Residential / Web Unlocker にフォールバックさせる構成にすると、月額コストを抑えつつ 1 万並列規模を安定運用できます。まずは小さなターゲットサイトで RPS と成功率を計測し、Zone 設計を固めてから本番ロードに乗せてください。
※情報は 2026-05-24 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
Footnotes
-
Bright Data 公式 - Datacenter Proxy: https://brightdata.com/proxy-types/datacenter-proxies ↩
-
Bright Data 公式 - 料金プラン (Datacenter $0.42-$0.60/GB、Residential $2.50-$4.00/GB の最低価格比較): https://brightdata.com/pricing ↩
よくある質問
関連記事


