
Bright Data MCP サーバーで AI Agent にスクレイピングを任せる実践ガイド 2026
Bright Data MCP サーバーを Claude や Mastra に接続し、Bot 検知突破つきの Web スクレイピングを AI Agent に委ねる構成を実運用視点で解説します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
「Claude や Cursor のようなエージェントに、Bot 検知をかわした Web スクレイピングまで任せたい」——これを最短で実現するのが Bright Data MCP サーバーです。本稿は MCP の基本、Bright Data の MCP サーバー構成、Claude Code / Mastra への接続、運用上の落とし穴までを、弊社の Bright Data 運用経験を踏まえて整理します。
1. MCP と Bright Data の関係を 60 秒で整理する
Model Context Protocol (MCP) は Anthropic が 2024 年末に公開した、LLM と外部ツールを接続するためのオープン通信プロトコルです。Claude Code / Claude Desktop / Cursor がリファレンスクライアントとして対応し、Slack や GitHub、Postgres、ファイルシステムを「ツール」として LLM に渡せます。Bright Data はこの波に乗り、プロキシ・Web Unlocker・SERP API を Bright Data MCP サーバー として公開しました。エージェントは search_engine や scrape_as_markdown といった関数を呼ぶだけで、裏側ではプロキシ選定・CAPTCHA 突破・JS レンダリングが自動処理されます。突破ロジックは Bright Data Web Unlocker 実践活用ガイド 2026 と同じ仕組みです。
1.1 なぜ Bright Data なのか
LLM 内蔵の Web Search や軽量プロキシでは、本番運用で 403 / 429 連発、JS 未レンダリングによる空データ、CAPTCHA / Cloudflare / PerimeterX による取得停止といった壁に当たります。Bright Data MCP サーバーは 1.5 億超の Residential IP プールと Web Unlocker でこれらを吸収し、Agent 側のコードを単純に保てる点が最大の価値です。
1.2 想定ユースケース
- 競合価格モニタリング、レビュー・求人・不動産情報の継続収集
- 新規市場リサーチを Agent で一気に走らせる「研究助手」型ワークフロー
- 社内ナレッジボットに公開 Web の最新一次情報を組み合わせる RAG パイプライン
2. Bright Data MCP サーバーの構成と提供ツール
Bright Data MCP サーバーは Node.js 製の OSS として公開されており、npx @brightdata/mcp で起動できます。API_TOKEN 環境変数に Bright Data のアクセストークンを渡すだけで、以下のツール群がエージェントに公開されます。
| ツール名 | 内容 | 裏側の Bright Data 製品 |
|---|---|---|
search_engine | Google / Bing / Yandex などの検索結果を構造化 JSON で返す | SERP API |
scrape_as_markdown | 任意の URL を Markdown 化して返す | Web Unlocker |
scrape_as_html | 任意の URL の HTML をそのまま返す | Web Unlocker |
web_data_* | Amazon / LinkedIn / Instagram など、サイト別の構造化抽出 | Dataset / Web Scraper API |
scraping_browser_navigate ほか | Playwright 互換の Stealth ブラウザ操作 | Scraping Browser |
エージェント側はこれらのツールを通常の関数として認識します。次の図は、エージェントからのツール呼び出しが Bright Data の各製品に振り分けられる流れです。
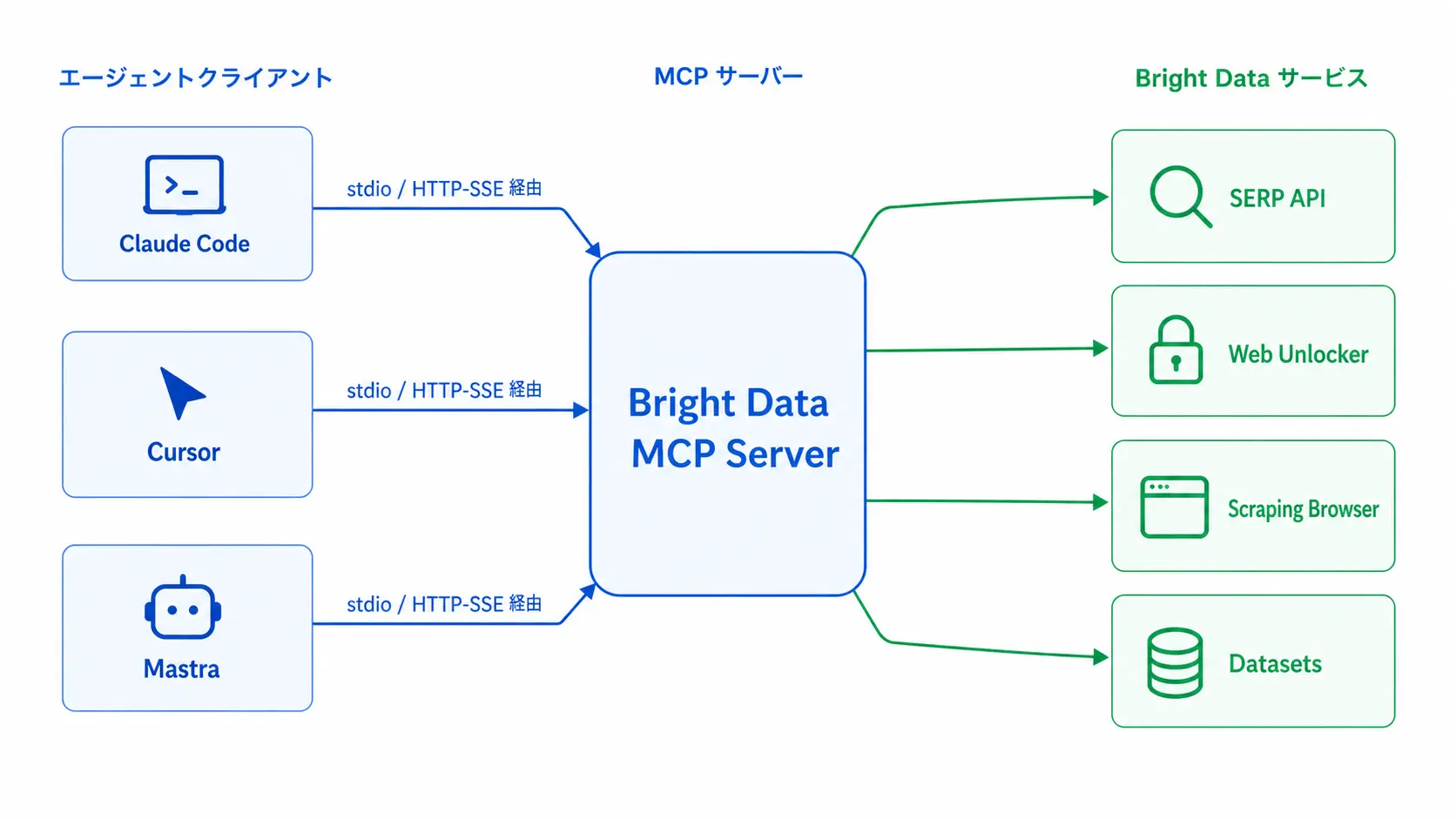
2.1 トランスポートと認証
MCP には stdio と HTTP/SSE の 2 種類のトランスポートがあり、Claude Desktop / Claude Code のローカル接続では stdio、Mastra や独自バックエンドから呼ぶ場合は HTTP/SSE を選ぶのが基本です。認証は Bright Data API Token をヘッダまたは環境変数で渡す方式で、Zone 単位のトークン分離もそのまま使えます。トークンの取得は Bright Data アカウント作成と初期設定ガイド 2026 の流れで KYC 審査を済ませておけば 10 分程度で完了します。
2.2 Mastra との関係
Mastra は TypeScript 製のマルチエージェントフレームワークで、2026 年 5 月に Bright Data ツールをファーストクラスサポートしました1。
Mastra コア v1.33.0 で Bright Data のアンチ Bot 検索・スクレイピングツールをエージェントから直接呼び出せるようになりました。(原文意訳)
Mastra で構成した Agent 群をそのまま MCP サーバーとして Claude Code から呼べるため、オーケストレーション・ログ・テストが Mastra 側で揃う本格運用に向いています。
3. Claude Code から Bright Data MCP を接続する 5 ステップ
実際に Claude Code から Bright Data MCP サーバーへ接続するまでの最短手順を整理します。Claude Code / Claude Desktop どちらでも基本同じです。
- Bright Data 管理画面でアクセストークンを発行する (Account Settings → API Tokens)
- Web Unlocker と SERP API の Zone を 1 つずつ作成する (
Manage Zones) ~/.config/claude-code/mcp.json(Claude Desktop はclaude_desktop_config.json) に MCP サーバー定義を追加する- Claude Code を再起動し、
/mcpでサーバー一覧と利用可能なツールを確認する - 任意のチャットで「ツールを使ってこのページの価格を取ってきて」と頼んでみる
mcp.json の例は次の通りです。
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "BRD_TOKEN_xxxxxxxx",
"WEB_UNLOCKER_ZONE": "unlocker_zone",
"BROWSER_ZONE": "scraping_browser_zone"
}
}
}
}
3.1 接続が通らないときの初期チェック
最初の起動で詰まりやすいのは次の 3 点です。
- API Token に Zone へのアクセス権が無い → 管理画面で Zone を割り当て直す
- ファイアウォール / 企業ネットワーク経由で
brightdata.comがブロックされる - Node.js のバージョンが古く
npxが ESM を解釈できない (Node.js 20 以上を推奨)
エージェント側で tool error のような曖昧なメッセージが出るときは、npx @brightdata/mcp を単体起動してログを確認すると原因が一発で分かります。
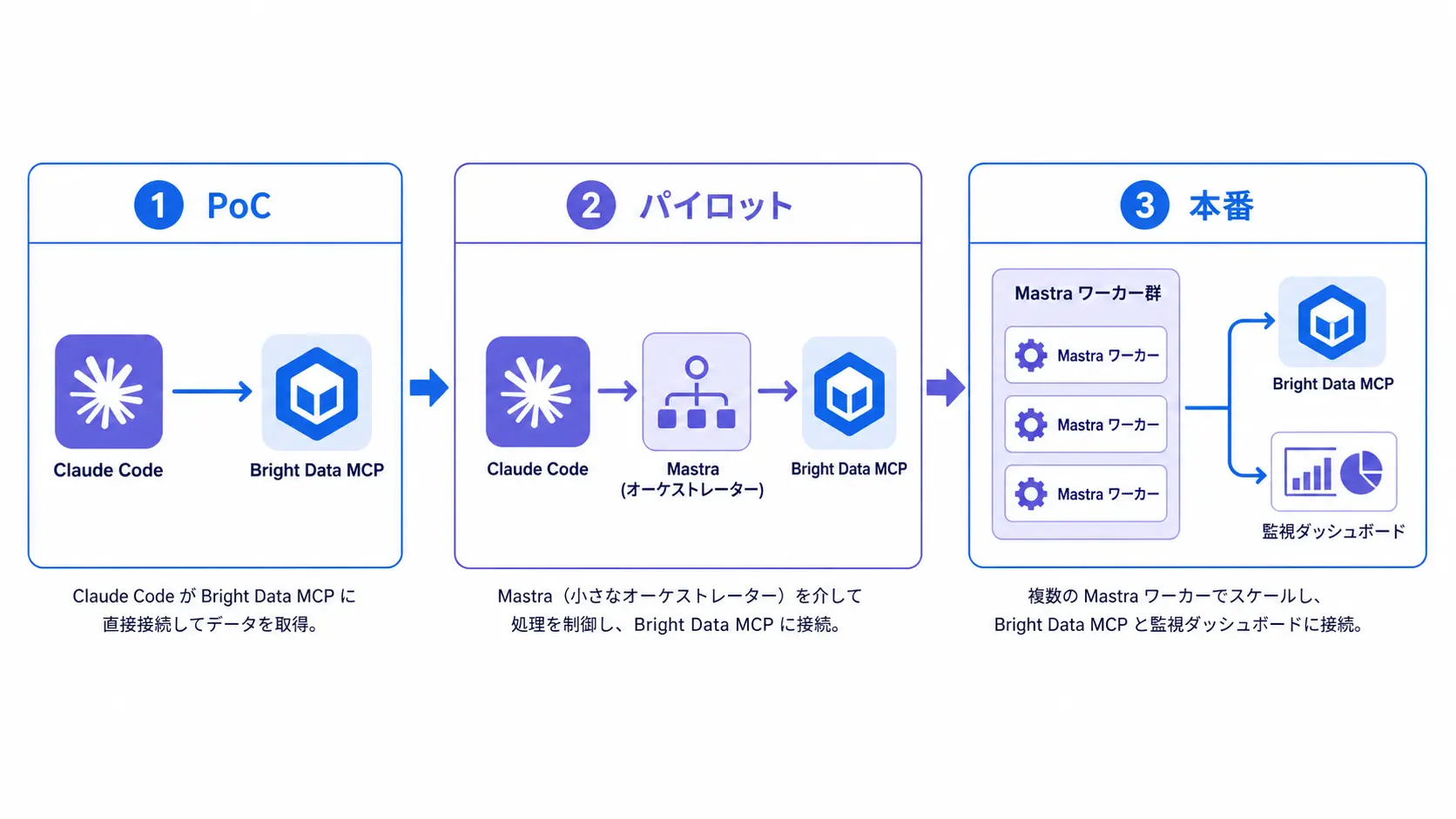
3.2 弊社 PoC の所感
弊社では Bright Data を本番運用しており、自社プロダクト Tra-bell も Residential / Web Unlocker 上で稼働しています。MCP は PoC や調査用 Agent として相性が良く、リサーチ担当者が自然言語で SERP 取得や記事収集を回せるようになりました。サーバーレスの定期実行ワークフローは AWS Lambda × Bright Data でサーバーレス スクレイピング基盤を構築する方法 2026 の構成が運用しやすい、というのが現状の使い分けです。
4. Mastra で本格運用する場合のアーキテクチャ
Claude Code から MCP を直接叩く構成では監視・コスト管理・テストが手薄になります。Mastra を中間レイヤとして挟むと、エージェントロジックを TypeScript で書きながら Bright Data を含む各種ツールを統制された形で呼べます。
4.1 推奨アーキテクチャ
- フロント: Claude Code / Claude Desktop / 社内 Slack ボット
- 中間レイヤ: Mastra ベースの Agent + Workflow (MCP サーバーとして公開)
- ツール層: Bright Data MCP、社内 API、Postgres MCP、Slack MCP など
- データ層: BigQuery / Snowflake / R2 など
Mastra Agent を MCP サーバーとして公開すれば、Claude Code 側からは単一サーバーに見えつつ、裏では複数 Bright Data 製品と社内 API を組み合わせたフローを回せます。レストラン経営をチャットで管理するデモも公開されており2、同じ発想を EC 運営やマーケットリサーチに応用できます。
「Mastra で組んだエージェント群を MCP サーバーとして公開し、Claude からチャットでレストラン業務を丸ごと管理するデモを動かしている」(原文: "12 specialized agents + orchestrator exposed as an MCP server, plugged into Claude — running a whole restaurant via chat.")
4.2 オブザーバビリティとコスト管理
Bright Data MCP は本番運用でツール呼び出しが増えがちなので、最初から次を組み込みます。
- ツール呼び出し回数 / バイト数を Mastra ミドルウェアでロギング
- Usage API で日次の消費量を BigQuery / Snowflake に取り込み
- 想定外のコスト増加を検知する Slack アラート
- LLM-as-a-judge でクエリを自動採点し、無駄打ちを削減
コスト最適化は Bright Data のコスト最適化テクニック 2026 に整理しています。
5. 法令とサイト規約への配慮
MCP 経由でも法令面の確認は変わりません。エージェントが自律的に動くからこそ、ガードレールは人間側で設計する必要があります。
"Bright Data MCP makes agents incredibly capable on the open web — but you still own the responsibility of what you scrape." (Bright Data MCP は Web 上でエージェントを強力にするが、何を取得するかの責任は利用者にある)
実務で押さえるべきポイント:
- 対象サイトの利用規約と robots.txt を事前確認し、システムプロンプトで許可ドメインを明示
- 個人情報・センシティブデータを含む可能性のあるサイトは Web Unlocker でも避ける
- GDPR / 個人情報保護法 / CCPA など対象国の法令に配慮 (Bright Data と GDPR / 個人情報保護法 2026 を参照)
- Agent 実行ログを 90 日以上保管し、取得対象とクエリを後追いできる状態にしておく
弊社では Bright Data を使ったホテル価格追跡サービス Tra-bell を自社運用しており、MCP 経由スクレイピングの Zone 設計・コスト試算・コンプライアンスレビューまでまとめてご相談いただけます。
6. まとめ
Bright Data MCP サーバーは「LLM に開かれた Web を渡す」ための実用解です。PoC は Claude Code から MCP に繋ぐだけで始められ、本番運用は Mastra で監視とコスト統制を効かせるのが現状のベストプラクティスです。プロキシ品質と Bot 検知突破の精度、製品ラインの広さを踏まえると、AI Agent によるスクレイピング基盤の第一候補に挙がるサービスといえます。
※情報は 2026-05-21 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
Footnotes
-
Mastra 公式 X アカウント "Bright Data integration in @mastra/core" (2026-05): https://x.com/mastra/status/2055015396093354375 ↩
-
rfscheidt 氏による Mastra → MCP → Claude のデモポスト (2026-05): https://x.com/rfscheidt/status/2056030193672708434 ↩
よくある質問
関連記事

Bright Data Web Unlocker 実践活用ガイド 2026 - CAPTCHA突破とコスト設計



