
Bright Data で国内 EC データパイプラインを設計するガイド 2026
Bright Data の Dataset と Web Scraper API で楽天・Amazon・Yahoo! のデータを業務システムに取り込むパイプラインを、スキーマ・差分・コストで整理。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
Bright Data で国内 EC のデータが取れても「商品マスタ取り込み」「差分検知」「コスト調整」で詰まるケースは多いです。Dataset Marketplace と Web Scraper API を組み合わせスキーマ・差分・取得頻度を設計すれば月額数万円規模で 1,000〜10,000 SKU の運用は回せます。本記事は弊社 Tra-bell の運用知見をもとに楽天・Amazon・Yahoo! 向け設計を整理します。
なぜ IP 基盤だけでは国内 EC データ運用は完結しないのか
国内 EC スクレイピング記事は Residential と Web Unlocker から入りがちですが、実運用では「取得後の処理」が工数の 7 割を占めます。
IP より下流で詰まる典型ポイント
- スキーマ不揃い: 楽天
itemPrice・Amazonprice.value・Yahoo!price_intを SoT に正規化しないと差分検知も BI も成立しない - 重複と欠損: 同一商品が複数ショップから出る場合に、どの行を採用するかルールが固まっていない
- 更新頻度のズレ: 楽天は即時、Amazon は数時間遅れで古いデータ事故が起きやすい
- コスト線形性: 全 SKU 毎日全モールだと Web Unlocker コストが直線的に増え、想定の 2〜3 倍に膨らむ
製品選定は Bright Data で楽天・Amazon.co.jp・Yahoo! を安全にスクレイピングする実践ガイド 2026 で整理しています。
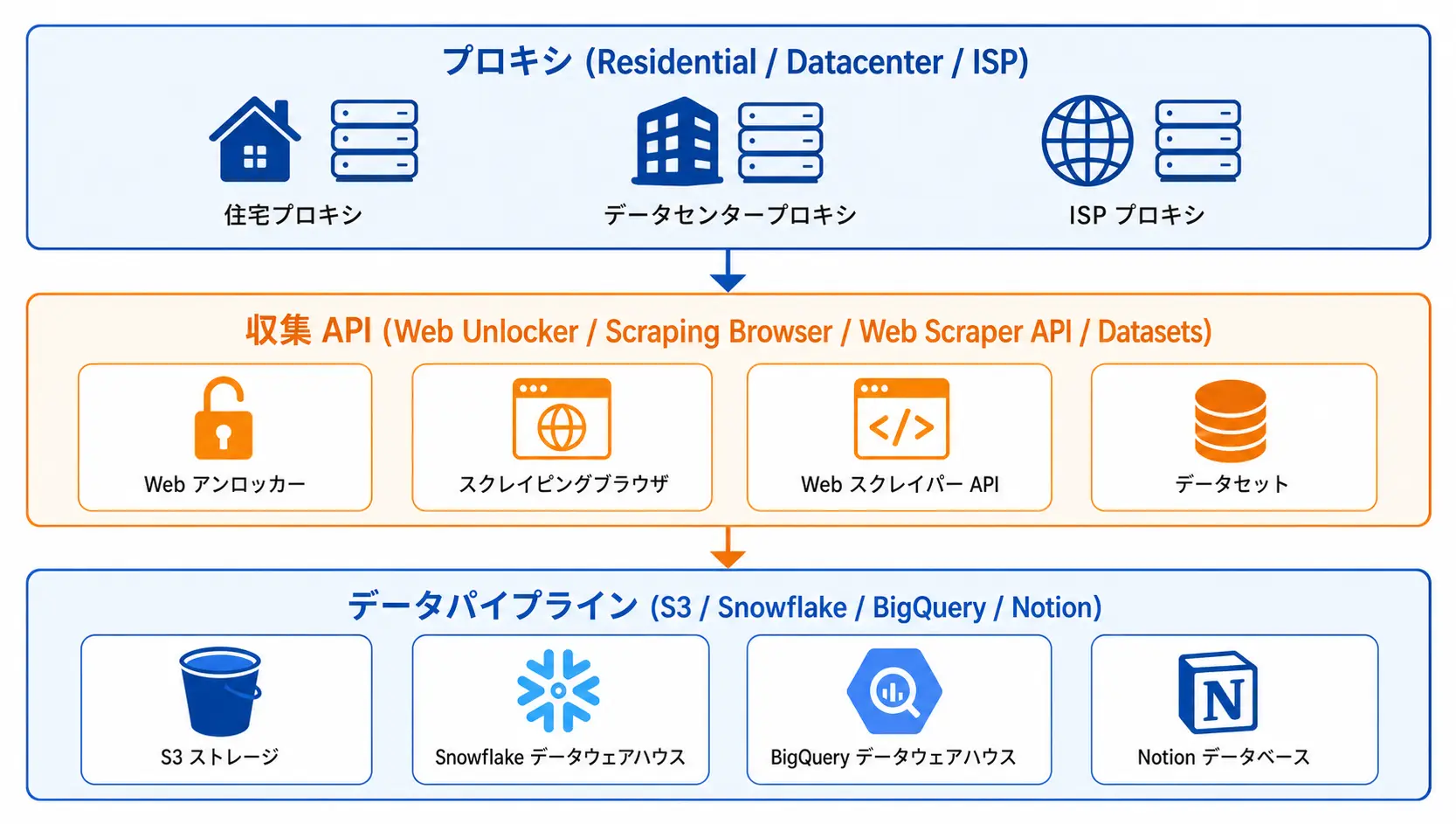
Bright Data の 3 系統の取得手段
| 手段 | 国内 EC での主用途 |
|---|---|
| Proxy | カスタムパーサが必要なケース |
| Web Scraper API / IDE | 楽天・Yahoo! の半構造データに型を当てる |
| Dataset Marketplace | Amazon の広く浅い取得、ベンチマーク |
「取れるものは API / Dataset」「整形は Bright Data に寄せる」「Python は業務系への伝播に専念」の分業がコスト・工数の両面で有利です。
SoT スキーマと商品 ID 設計
各モールの生 JSON は構造がバラバラです。共通キーに揃えるステージング層を必ず挟みます。
モール横断の共通スキーマ例
| 列名 | 説明 |
|---|---|
mall_code | rakuten / amazon-jp / yahoo-shopping |
mall_item_id | 楽天商品コード / ASIN / Yahoo! コード |
sku_global_id | 統合 ID (JAN + ASIN ハッシュ等) |
price / stock_status | 税込価格 (円) / in_stock-low-out |
attributes | 半構造属性 (jsonb で生のまま) |
payload_hash | 主要カラムのハッシュ (差分検知用) |
sku_global_id を別途持つ
mall_item_id だけでは Amazon (ASIN) と楽天 (商品コード) の紐付けができません。sku_global_id を持つと業務マスタ更新やランキング集計が楽になります。JAN があれば JAN を主、なければ「正規化タイトル + 属性ハッシュ」で代用します。
楽天・Yahoo! のカテゴリマッピングの機械補完は、自社プロダクト CataMap のような AI 補完アプローチが選択肢になります。
Web Scraper API を使った取得層の組み方
Web Scraper API は Collector を Bright Data 側で実行し JSON を返します。トリガーとフェッチが分離されており、キュー設計と相性が良い構造です。
取得フロー (擬似コード)
import os, time, httpx
BD_TOKEN = os.environ["BD_TOKEN"]
COLLECTOR_ID = "<collector_id>"
def trigger_collect(items: list[dict]) -> str:
res = httpx.post(
f"https://api.brightdata.com/dca/trigger?collector={COLLECTOR_ID}",
headers={"Authorization": f"Bearer {BD_TOKEN}"},
json=items, timeout=30.0,
)
res.raise_for_status()
return res.json()["snapshot_id"]
def fetch_result(snapshot_id: str) -> list[dict]:
for _ in range(60):
s = httpx.get(
f"https://api.brightdata.com/dca/snapshot/{snapshot_id}?format=json",
headers={"Authorization": f"Bearer {BD_TOKEN}"}, timeout=30.0,
)
if s.status_code == 200:
return s.json()
time.sleep(10)
raise TimeoutError("snapshot not ready")
サーバーレス構成は AWS Lambda × Bright Data でサーバーレス スクレイピング基盤を構築する方法 2026 で扱います。
モール別の Collector 設計ポイント
- 楽天市場: 公式 Collector が限定的、IDE でセレクタを組む。Rakuten Web Service の範囲は API 優先
- Amazon.co.jp: 公式 Collector が豊富。ASIN を投げれば JSON、カスタムパーサ不要
- Yahoo! ショッピング: IDE で自前定義することが多い。PayPay モール商品と混在するので
store_idで切り分け
DifyJapan は Bright Data Web Scraper を Dify に統合した事例を X で発信しています。
「Dify と Bright Data Web Scraper を組み合わせて Amazon の商品データを安定取得する手順を Qiita で公開」(原文: Stable Amazon scraping with Dify + Bright Data Web Scraper — full walkthrough on Qiita)
「n8n と Bright Data を使えば、ローコードで Amazon の商品データを継続的に集められる」(原文: Built an Amazon product scraper with n8n and Bright Data — surprisingly low maintenance)
cron トリガーで Web Scraper API を呼び、結果を Google Sheets や Postgres に流し込む n8n 構成が広く使われています。
差分検知と更新サイクルの設計
パイプラインの真価は「変化した分だけ伝播させる」点にあります。これで下流の API コール・DB 書き込み・通知量が桁で減ります。
ハッシュベースの差分検知
import hashlib, json
def payload_hash(item: dict) -> str:
sig = {
"price": item["price"],
"stock_status": item["stock_status"],
"ranking": item.get("ranking"),
"title": item["title"],
}
payload = json.dumps(sig, sort_keys=True, ensure_ascii=False)
return hashlib.sha256(payload.encode("utf-8")).hexdigest()
前回行とハッシュ一致なら「変化なし」として下流に流さない、というシンプル実装で運用には十分です。
取得頻度の階層化
| 対象 | 推奨頻度 |
|---|---|
| 高頻度 SKU (50〜200) | 1 日 4〜8 回 |
| 通常 SKU (500〜2,000) | 1 日 1 回 |
| ロングテール (5,000〜数万) | 1 週間 1 回 |
| カテゴリ・ランキング | 1 日 1〜2 回 |
「全 SKU 毎日 1 回」から階層化に切り替えるだけで Bright Data のリクエスト量は 40〜60% 落ちます。階層は売上 ABC 分析で割り当てるのが安定します。
コスト最適化と弊社の伴走支援
パイプラインのコストは「取得層 + 処理層 + 保存層」の合計で、Bright Data の比率が大きくなりがちです。
月額を抑える 5 つの実践
- 階層化頻度: 全 SKU 毎日から脱却し、重要 SKU と通常 SKU を分ける
- Collector 共有: 同一カテゴリは 1 つの Collector を再利用、差分はパラメータで吸収
- Web Unlocker は限定: 構造化データは Web Scraper API 優先、Web Unlocker は失敗時 fallback に限定
- S3 アーカイブ: Snapshot を 30 日後にコールド化し、再取得で再課金しない
- 平日朝のスパイク回避: 深夜帯にずらすと成功率が上がりリトライコストが減る
料金体系全般は Bright Data 料金プラン早見表 2026 で扱っています。
弊社では Bright Data の Residential / Web Unlocker / Web Scraper API を使った Tra-bell (ホテル価格追跡) を自社運用しており、正規化・差分検知・業務連携を一気通貫で設計しています。
まとめ
国内 EC データパイプラインは IP 基盤よりも「取得後の正規化と差分検知」で品質と運用コストが決まります。Dataset Marketplace と Web Scraper API を主軸に、SoT スキーマ + ハッシュ差分 + 階層化頻度を組めば、月額数万円規模で 1,000〜10,000 SKU の運用は現実的です。
※情報は 2026-05-21 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
よくある質問
関連記事

Bright Data で楽天・Amazon.co.jp・Yahoo! を安全にスクレイピングする実践ガイド 2026

