AWS Lambda × Bright Data でサーバーレス スクレイピング基盤を構築する方法 2026
AWS Lambda と Bright Data でサーバーレスなスクレイピング基盤を組む構成・コード・コスト設計を、弊社 Tra-bell の運用知見をもとに 2026 年最新で解説します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
AWS Lambda と Bright Data を組み合わせると、自前でブラウザや IP プールを管理することなくサーバーレスなスクレイピング基盤が組めます。本記事では構成図、Python ベースの最小コード、Secrets Manager や Step Functions との連携、月額数万円規模に収めるコスト設計までを、弊社が運用する Tra-bell の実プロダクション知見をもとに 2026 年版で解説します。
なぜ AWS Lambda × Bright Data がサーバーレス スクレイピングの本命か
スクレイピング基盤を内製すると、ボット検知突破・IP ローテーション・CAPTCHA 解決・ブラウザ運用といった「本業ではない仕事」が積み上がります。Bright Data が肩代わりするのはまさにこの領域で、Lambda はその上に乗る軽量なオーケストレータに専念できます。結果としてコールドスタートが速く、メモリも低く済み、本来書きたい抽出ロジックと正規化処理だけを Lambda に残せるという構造になります。
Lambda 単独だと辛い 4 つの理由
- Chromium バンドルが重い: Playwright や Selenium を Lambda Layer に詰めると 250MB 制限とコールドスタート時間が問題化
- IP がデータセンター: AWS の EIP は EC サイト側で軒並みブロックリストに乗っている
- CAPTCHA 突破ロジックの保守コスト: bot 防御は数か月単位で更新され、追従に専任エンジニアが必要
- 15 分の実行制限: 長時間ブラウザセッションは Lambda 内で完結させにくい
Bright Data の Residential Proxy / Web Unlocker / Scraping Browser のいずれかを差し込むと、これらが一気に外注できます。Lambda 側のコードは「URL を受け取って HTTP リクエストを投げ、レスポンスを正規化して S3 に書く」だけの数十行に収まります。プロキシ選定で悩む場合は Bright Data Residential と ISP プロキシの使い分け実践ガイド を併読すると判断が早まります。
採用が広がる 2025〜2026 年のトレンド
AI エージェント / RAG パイプライン用途で「リアルタイムに Web から構造化データを取りたい」需要が急増しており、Bright Data はそのバックエンドとして採用が広がっています。Mastra のような AI エージェントフレームワークが Bright Data ネイティブ連携を入れ始めているのも 2025 年以降のトレンドです。
「Mastra が Bright Data 連携を正式追加し、Bot 検知を回避しつつ Web 検索できるエージェントを誰でも組めるようになった」(原文: Mastra now ships native Bright Data integration so agents can search the web while bypassing bot detection.)
「Bot 検知を回避しながら Web 検索する」のような機能を Lambda 内で実装したい場合、Bright Data の API を Mastra / LangChain / 自前エージェント越しに叩く構成が現実的です。
サーバーレス スクレイピング基盤の標準アーキテクチャ
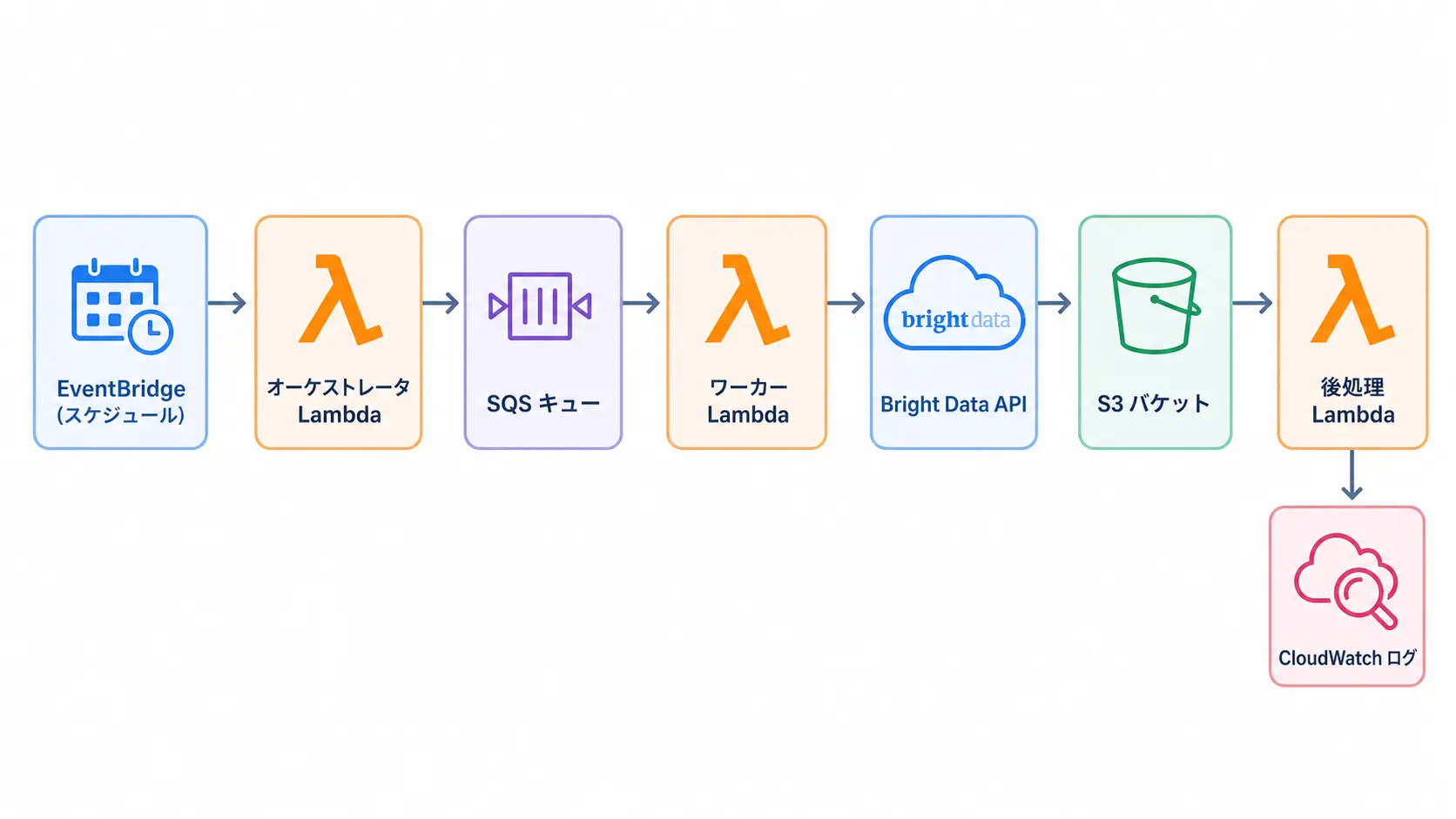
弊社 Tra-bell で 1 年以上回している構成をベースに、最小コストで動かせる 5 コンポーネント構成を示します。トリガー → オーケストレータ Lambda → ワーカー Lambda → Bright Data → S3 という流れです。
5 コンポーネントの責務
- トリガー: EventBridge スケジュール / SQS / API Gateway / S3 イベントのいずれか。1 日 1〜数回が典型
- オーケストレータ Lambda: 対象 URL リストを生成、SQS にエンキュー。DynamoDB で実行状態を保存
- ワーカー Lambda (並列): SQS から URL を取り出し、Bright Data 経由で HTTP リクエスト。抽出結果を S3 に JSON / Parquet で書き出し
- 後処理: S3 イベントで別 Lambda / Glue ETL / Step Functions を起動。クレンジング・名寄せ・DWH へのロード
- 配信・通知: Bright Data からのウェブフック → EventBridge → 通知 Lambda。CloudWatch + X-Ray で監視
使う AWS サービスを最小に絞る指針
- 状態管理は DynamoDB ではなく S3 + SQS で済むケースが多い: 「URL のキューと結果の保存」だけなら DynamoDB は過剰
- Step Functions は条件分岐が複雑な時のみ: 1 段スクレイピング → 1 段正規化なら EventBridge と Lambda の組み合わせで十分
- Secrets Manager は必須: Bright Data の zone 認証情報を環境変数で持たない。後述
Python サンプル: Web Unlocker 経由でページ取得
import os
import json
import httpx
import boto3
from botocore.exceptions import ClientError
SECRET_ID = os.environ["BD_SECRET_ID"]
S3_BUCKET = os.environ["S3_BUCKET"]
_cached = {}
def get_proxy() -> str:
if "proxy" in _cached:
return _cached["proxy"]
sm = boto3.client("secretsmanager")
secret = json.loads(sm.get_secret_value(SecretId=SECRET_ID)["SecretString"])
_cached["proxy"] = (
f"http://{secret['user']}:{secret['pass']}"
f"@brd.superproxy.io:33335"
)
return _cached["proxy"]
def handler(event, _ctx):
s3 = boto3.client("s3")
proxy = get_proxy()
for record in event["Records"]:
url = record["body"]
with httpx.Client(
proxies={"http://": proxy, "https://": proxy},
timeout=30.0,
headers={"User-Agent": "Mozilla/5.0"},
) as client:
r = client.get(url)
r.raise_for_status()
key = f"raw/{url.replace('://', '_').replace('/', '_')}.html"
s3.put_object(Bucket=S3_BUCKET, Key=key, Body=r.content)
return {"ok": True}
このコードは SQS トリガー想定で、1 メッセージ = 1 URL の最小実装です。Bright Data の Web Unlocker を使うと CAPTCHA / Cloudflare / Akamai 等の bot 防御が自動で突破されるため、ワーカー側はリトライ・ヘッダ偽装などを自前で実装する必要がほぼなくなります。Bright Data API の応用パターンを掘り下げたい場合は Bright Data Web Unlocker 実践活用ガイド も参考にしてください。
本番運用で踏みやすい 5 つの落とし穴
PoC は動いたのに本番で詰まる、というケースには共通パターンがあります。Tra-bell でも初期に同じ轍を踏みました。
1. 認証情報のハードコード
環境変数や Lambda の Layer に直接 zone のユーザー名・パスワードを置くと、コードリポジトリのコミット履歴やコンテナイメージから漏洩します。AWS Secrets Manager にローテーション可能な形で保存し、Lambda 起動時に取得 → 同一コンテナで再利用するパターンが基本です。
2. リトライ戦略の暴走
Web Unlocker が 5xx を返した時に無限リトライを仕込むと、Bright Data 側の従量課金が爆発します。最大 3 回 + 指数バックオフを基本とし、5xx 連続時はサーキットブレーカで一時停止する設計にします。
3. タイムアウトの過小設定
httpx のデフォルトタイムアウトは 5 秒ですが、Web Unlocker は CAPTCHA 突破処理を挟むため 20〜30 秒かかることがあります。Lambda のタイムアウトより 5 秒短い httpx タイムアウトに揃えておくと、Lambda 自体が強制終了する前にきれいに例外を投げてくれます。
4. 監視と請求アラートの欠落
CloudWatch でワーカーの成功率・実行時間を、Bright Data ダッシュボードで日次帯域・リクエスト数を監視します。両方に閾値アラートを入れておかないと、想定外のスパイクで月末請求が 3 倍になることがあります。
「Bright Data は AI エージェントが信頼できる Web データを取りに行くときの現実的なバックエンドで、運用負荷を抑えて使える」(原文: Bright Data is the practical backend for AI agents that need reliable web data without maintenance headaches.)
公式ドキュメントだけでなく実運用ユーザーの体験談も参考にすると、思わぬ落とし穴を回避できます。AI エージェント文脈での Bright Data 活用は X 上で活発に議論されています。
5. 利用規約とコンプライアンスの軽視
スクレイピング対象サイトの利用規約・robots.txt・Crawl-Delay を必ず確認します。Bright Data 側も KYC を経て利用目的を申告する仕組みになっており、対象が個人情報を含むサイトや明示的に禁止しているサイトの場合はゾーン承認が下りないケースがあります。
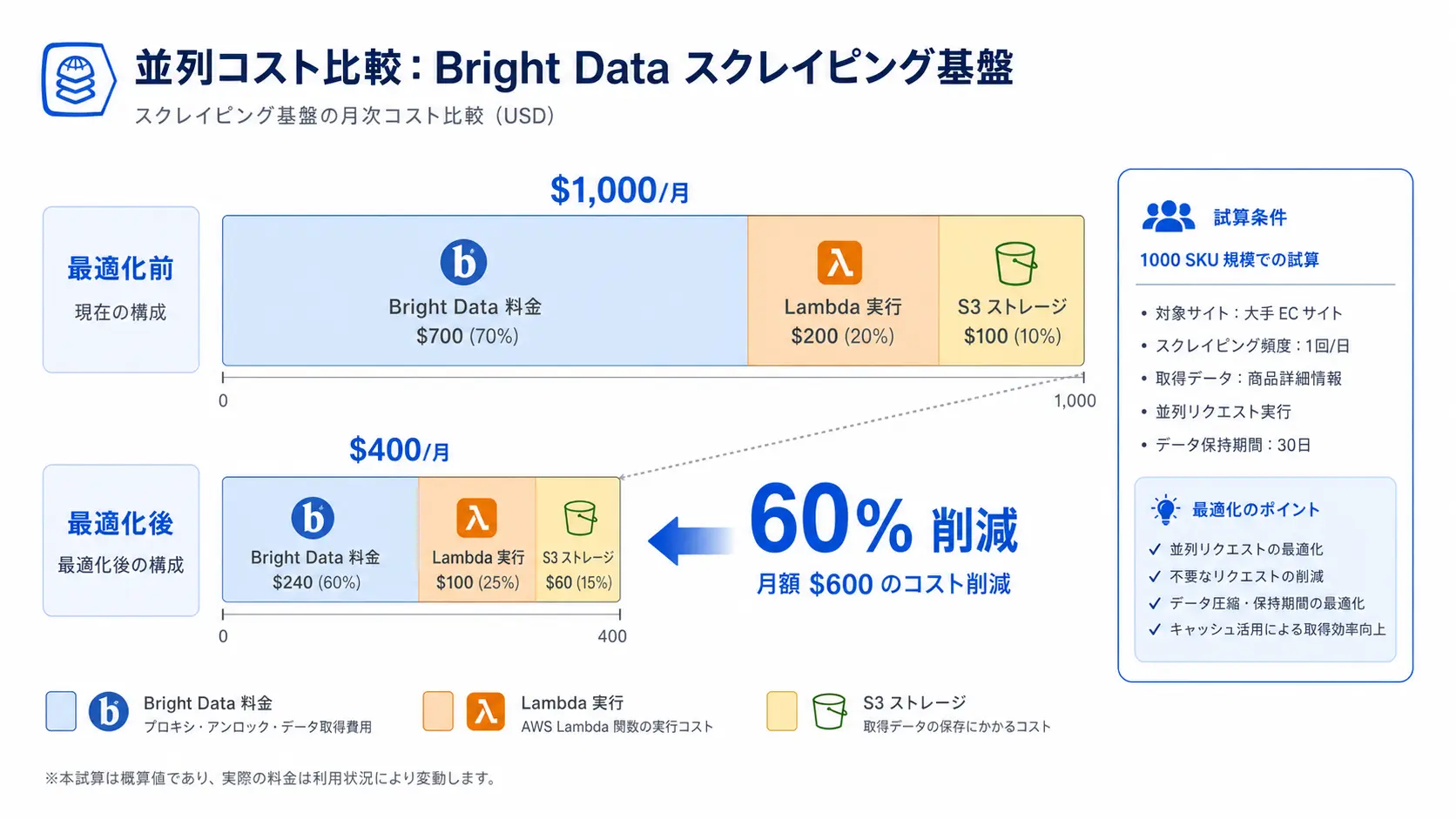
コストを最小化する 5 つの設計パターン
Bright Data の従量課金は Web Unlocker や Scraping Browser を雑に使うと膨らみます。Lambda 側は安いので、コストは基本的に Bright Data 側で決まります。1,000 SKU を 1 日 1 回監視する規模で、月額 $200 を $60 程度まで圧縮するパターンを 5 つにまとめました。詳細な単価早見表は Bright Data 料金プラン早見表 2026 も参照してください。
- 段階的フォールバック: まず Residential 単体で取得、403 / CAPTCHA で詰まった URL のみ Web Unlocker に回す
- 長寿命セッション: 同一 IP を 30 分〜数時間使い回し、ハンドシェイク帯域を削減 (Residential で 20〜40% 削減効果)
- 差分監視: 価格・在庫が変化した SKU のみを翌日深掘り取得。全件再取得を避ける
- 静的アセット除外: 画像・CSS・分析タグはリクエストしない。帯域 50〜70% カット可
- 時間帯分散: 深夜帯はサイト負荷も低く成功率が上がる。リトライ回数の削減効果が大きい
「Bright Data はパワフルだが、Browserbase や Scrapling など他の選択肢と比べてコストと運用負荷のバランスを見極めて選ぶべき」(原文: Bright Data is powerful, but weigh cost and ops effort against Browserbase, Scrapling and other emerging options before committing.)
「Bright Data は強力だがコスト管理が肝」というのは X 上でも繰り返し言及される論点で、スクレイピング基盤の品質はインフラ選定よりも設計品質で決まります。
設計を一度で正解させたいときの選択肢
スクレイピング基盤は「PoC 1 週間 + 安定化 1〜2 か月」が標準的な工期です。社内に Python / インフラ / Bright Data 運用の専任が居ない場合、Bright Data の契約形態・ゾーン設計・コスト最適化までを伴走するパートナーを置くと立ち上げ期間を半分以下に短縮できる傾向があります。
弊社では、Bright Data の Residential / Web Unlocker を使ったホテル価格追跡サービス Tra-bell を AWS Lambda 上で運用しており、Lambda の並列度設計・SQS のバッチサイズ・Secrets Manager のキャッシュ戦略・S3 → Athena / BigQuery への接続まで実プロダクトで踏んできた知見を提供できます。
まとめ
AWS Lambda × Bright Data の組み合わせは、Chromium 同梱もブロック対応も自前で抱えずに、最小の運用コストでスクレイピング基盤を組める現実的な解です。EventBridge → SQS → Lambda → Bright Data → S3 という 5 コンポーネントを軸に、Secrets Manager とリトライ戦略、コスト監視を最初から組み込めば、月額数万円規模で 1,000 URL クラスの安定運用が見えてきます。PoC は 100 URL から始め、フォールバック設計と差分監視を入れた段階で本番に拡張するのが最短ルートです。
※情報は 2026-05-21 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
よくある質問
関連記事