
Bright Data SERP API を Python で実装する完全ガイド 2026 - 認証・パラメータ・コスト設計
Bright Data SERP API を Python で叩く実装パターンを、認証・パラメータ・エラーハンドリング・コスト最適化まで実運用目線で整理しました。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
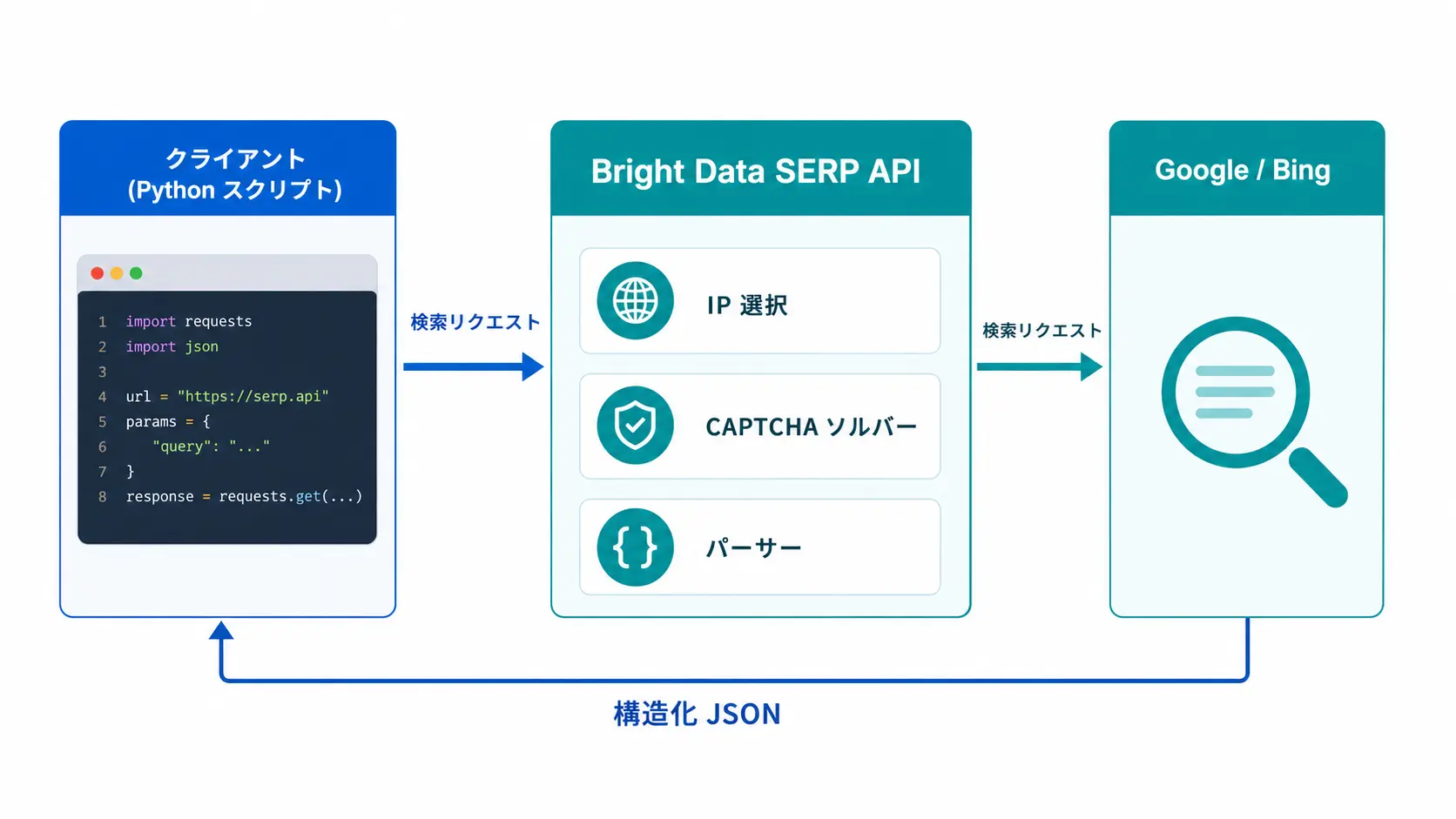
Bright Data SERP API は、Google や Bing の検索結果を構造化 JSON で取得できるエンタープライズ向け API です。本記事では、弊社が Tra-bell を Bright Data 上で運用してきた経験を踏まえ、Python でこの API を叩く実装パターン・認証・パラメータ設計・エラーハンドリング・コスト最適化までを実装目線でまとめました。結論から言えば、SERP API は「SERP 取得に用途を絞って」使うのが最もコスト効率が良く、Residential Proxy や Web Unlocker と組み合わせて多段で運用するのが弊社の標準パターンです。
Bright Data SERP API とは - 通常スクレイパーとの違い
Bright Data SERP API は、検索エンジンの結果ページ (SERP: Search Engine Results Page) を構造化 JSON で返す Bright Data のマネージド API です。リクエスト時にクエリと国・言語・デバイスなどのパラメータを送ると、内部で以下を自動処理してレスポンスを返してくれます。
- 検索エンジンへのアクセス: Google / Bing / Yandex / DuckDuckGo など複数エンジンに対応
- bot 検知の回避: 大規模 IP プールから適切な IP を選定し、検知をくぐる
- CAPTCHA 自動処理: Google reCAPTCHA や Bing の bot ガードを内部でソルブ
- 構造化パース: 検索結果を organic / ads / featured snippet / People Also Ask 等のキーに分けて JSON で返却
- 地域・言語制御: country / language / device / location パラメータで結果を厳密にコントロール
通常の HTTP クライアントで Google SERP を直接スクレイピングする方式は、2025〜2026 年時点ではほぼ実用に耐えません。bot 検知の精度が上がり、Cloudflare 相当の前段が標準装備されたため、自前の requests + BeautifulSoup や Playwright では数百リクエスト目から ブロックされるのが現実です。SERP 取得を本番運用に乗せるなら、SERP 特化 API を使うのがほぼ唯一の現実解です。
主なユースケース
- キーワード順位モニタリング: 自社・競合の検索順位を毎日トラッキング
- 競合 SEO 分析: 競合がどのキーワードで上位に出ているか、organic / ads の構造を分析
- LLM の RAG 前処理: ユーザー質問に対し SERP API で最新情報を取得し、LLM に渡す
- リード生成: 検索結果から候補ドメインを抽出し、後段の LLM で内容要約・パーソナライズ
- 市場調査: 製品名やブランド名の検索結果を地域別に取得し、認知度や訴求文脈を分析
X 上でも Bright Data SERP API を含む構成は B2B リード生成や RAG パイプラインの文脈で言及が増えています。
「Bright Data はプロキシ網・Web Unlocker・構造化 JSON 出力を一体運用できるエンタープライズ級 SERP API で、B2B リード生成や RAG パイプラインでの採用が広がっている」(原文: Bright Data combines its massive proxy network, Web Unlocker, and structured JSON output — used for automated B2B lead generation and real-time RAG pipelines.)
直接スクレイピングが厳しくなった分、SERP 特化 API への移行を検討するチームが増えているのが 2026 年の流れです。
競合ツールとの違い
| ツール | アプローチ | Bright Data SERP API との違い |
|---|---|---|
| SerpApi | SERP 特化 SaaS、Python SDK あり | 開発者体験は SerpApi が上、エンタープライズ SLA は Bright Data |
| Scrapingdog | 汎用スクレイピング API、SERP モジュールあり | 価格は Scrapingdog が安め、IP プール規模は Bright Data |
| Oxylabs SERP Scraper API | エンタープライズ向け、Bright Data の直接競合 | 機能はほぼ同等、IP プールは Bright Data 優位 |
| 自前 Playwright + Residential | 全てのレイヤーを自分で組む | 工数大、SERP 専用最適化なし |
SERP API はインフラ層を Bright Data が持つアプリ層 API という位置づけで、自前運用と比べて開発・保守工数を 5 分の 1 程度に圧縮できるケースが多いです。料金体系の詳細は Bright Data 料金プラン早見表 2026 で SERP API を含めた製品横断で整理しています。
課金体系と単価の現実
SERP API の課金は、リクエスト 1,000 件あたりの単価で表記されます (2026 年 5 月時点)。
単価のレンジ
| 項目 | 単価の目安 |
|---|---|
| SERP API 標準 | $3 / 1,000 リクエスト 〜 (≒¥450 / 1k) |
| 月間ボリュームディスカウント | 100 万リクエスト超で 30〜50% 値引 |
| 年間契約ディスカウント | 月額換算で 10〜20% 値引 |
| 失敗リクエスト | 課金対象外 (成功時のみ課金モデル) |
成功時のみ課金されるため、検索結果ページが返ってこなかった場合 (例: クエリが極端に長い、country 指定がエンジンに対応していない等) は請求が発生しません。ただし「成功」の判定はステータスコードとパース結果の組み合わせで行われるため、運用側でも自分のリクエストがどのくらいの確率で課金対象になっているかを継続的にモニタリングする必要があります。
コスト最適化の 3 つの定石
- キャッシュ層を必ず挟む: 同じクエリ + 同じ country/language なら 24 時間キャッシュで請求が半減する。Redis や DynamoDB の TTL 設定で十分
- クエリの正規化: 大文字小文字・全角半角・余分なスペースを正規化してから API に送ると、キャッシュヒット率が大きく上がる
- 取得粒度を絞る: top 10 で十分なら num_results を 10 に設定。「念のため 100 件」は無駄な転送料・パース時間を生む
月額予算別の構成例
| 用途 | 月間リクエスト | 月額目安 |
|---|---|---|
| 自社 SEO 順位監視 (500 KW × 日次) | 約 15,000 | $50 前後 |
| 競合 SEO 分析 (5,000 KW × 週次) | 約 100,000 | $250 前後 |
| LLM RAG パイプライン (中規模 SaaS) | 約 500,000 | $1,000 前後 (コミットメント契約で半額に圧縮可) |
| エンタープライズ B2B リード生成 | 約 5,000,000 | $7,000 前後 (要見積もり) |
「SERP 取得サービスは Oxylabs・Scrapingdog・HasData・SerpBase など代替が増えており、価格と機能のレンジが広がっている」(原文: Other strong alternatives mentioned in the community: Oxylabs, Scrapingdog, HasData, and newer cheaper options like SerpBase.)
代替サービスも複数登場していますが、IP プール規模と SLA を含めて比較すると、本番運用では Bright Data に落ち着くケースが多いのが弊社の観測です。
Python での実装 - 認証からレスポンス処理まで
Python から SERP API を叩く際の最小構成と、本番運用で必要な拡張ポイントを順に整理します。
認証とエンドポイント
SERP API は Bearer トークン認証 (API キー) を使います。ダッシュボード上で SERP API のゾーンを作成し、発行されたトークンを環境変数に格納するのが基本構成です。
# .env (例)
BRIGHT_DATA_API_TOKEN=your_api_token_here
BRIGHT_DATA_SERP_ZONE=serp_api_zone_name
最小実装 (requests ベース)
シングルクエリで organic 検索結果を取得する最小コードは次のようになります。
import os
import requests
def fetch_serp(query: str, country: str = "jp", language: str = "ja") -> dict:
"""Bright Data SERP API で Google 検索結果を取得する"""
api_token = os.environ["BRIGHT_DATA_API_TOKEN"]
zone = os.environ["BRIGHT_DATA_SERP_ZONE"]
# エンドポイントはダッシュボードで確認 (ゾーンごとに固有 URL)
url = "https://api.brightdata.com/serp/v1/search"
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = {
"zone": zone,
"engine": "google",
"query": query,
"country": country,
"language": language,
"num_results": 10,
"device": "desktop",
"format": "json",
}
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
return response.json()
if __name__ == "__main__":
result = fetch_serp("プロキシ おすすめ 2026", country="jp", language="ja")
for item in result.get("organic_results", []):
print(f"{item['position']}. {item['title']}")
print(f" {item['link']}")
エンドポイントの正確な URL はダッシュボード上で発行されるため、固定値を信用せず必ず管理画面から取得してください。
レスポンスの主要キー
SERP API のレスポンスは構造化された JSON で、用途別に分かれたキー構造を持ちます。
organic_results: 通常の検索結果。position/title/link/snippet/displayed_link等を含むads: 検索広告。タイトル・リンク・出稿者ドメインなどfeatured_snippet: 強調スニペット。ハイライト表示される回答ブロックpeople_also_ask: 「他の人はこちらも質問」のクエリ群related_searches: 関連検索クエリknowledge_graph: ナレッジパネル (人名・企業名等で表示)search_metadata: 取得日時・処理時間・該当ヒット数のメタ情報
すべてのキーが常に返るわけではなく、クエリやエンジンによって出現有無が変わります。コード側では .get(key, default) で安全に取り出す前提で書きましょう。
非同期で大量リクエストを捌く
LLM RAG や順位モニタリングで 1 日数千〜数万リクエストを投げる場合、同期 requests では遅すぎます。httpx + asyncio を使った非同期実装に切り替えると、5〜10 倍のスループットが出ます。
import asyncio
import os
from typing import Iterable
import httpx
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(3), wait=wait_exponential(min=1, max=10))
async def fetch_one(client: httpx.AsyncClient, query: str, country: str = "jp") -> dict:
payload = {
"zone": os.environ["BRIGHT_DATA_SERP_ZONE"],
"engine": "google",
"query": query,
"country": country,
"language": "ja",
"num_results": 10,
"format": "json",
}
headers = {
"Authorization": f"Bearer {os.environ['BRIGHT_DATA_API_TOKEN']}",
"Content-Type": "application/json",
}
response = await client.post(
"https://api.brightdata.com/serp/v1/search",
headers=headers,
json=payload,
timeout=30,
)
response.raise_for_status()
return response.json()
async def fetch_many(queries: Iterable[str], concurrency: int = 10) -> list[dict]:
limits = httpx.Limits(max_connections=concurrency)
async with httpx.AsyncClient(limits=limits) as client:
tasks = [fetch_one(client, q) for q in queries]
return await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
queries = ["プロキシ 比較", "SERP API Python", "Bright Data 料金"]
results = asyncio.run(fetch_many(queries, concurrency=5))
for q, r in zip(queries, results):
if isinstance(r, Exception):
print(f"FAIL: {q} -> {r}")
else:
print(f"OK: {q} -> {len(r.get('organic_results', []))} hits")
max_connections を 5〜10 程度に抑えるのが弊社の運用感です。並列度を上げすぎると Bright Data 側のレート制限に当たることがあるため、まず低めから始めて段階的に上げるのが安全です。
パラメータ設計 - country / language / device の使い分け
SERP API は柔軟なパラメータを持ちますが、設計を誤ると同じクエリでも結果が大きくブレます。本番運用で必須となるパラメータを整理します。
必須パラメータ
| パラメータ | 用途 | 推奨値の例 |
|---|---|---|
engine | 検索エンジンの指定 | google (デフォルト)、bing、yandex、duckduckgo |
query | 検索クエリ | 正規化された文字列 (前後スペース除去、全角・半角統一) |
country | 検索先の国 (IP 由来の判定を上書き) | jp / us / gb / de 等の ISO コード |
language | 言語 (hl 相当) | ja / en / de |
num_results | 取得件数 | 通常 10、SEO 分析で深掘りなら 50〜100 |
device | デバイスタイプ | desktop / mobile、目的に合わせて固定 |
よくある設計ミス
- country を指定しない: IP 由来の地域判定で結果がブレる。日本ユーザー向け検索結果が取りたいのに、米国向け結果が混ざる原因になる
- language を country と揃えない: 例: country=jp + language=en は実際の検索行動とずれる。原則は country と language を同地域で揃える
- device を毎回変える: mobile と desktop で順位が異なるサイトは多い。順位モニタリングでは device を固定する
- num_results を 100 で固定: 不要な転送料が発生。top 10 で十分な用途なら 10 に絞る
Location パラメータの活用
国レベルではなく市区町村レベルで結果を取りたい場合、location パラメータで "Tokyo, Japan" のように指定できます。地域 SEO や店舗集客分析では、location 指定の有無で結果が大きく変わるため、対象キーワードがローカル要素を含むなら必須です。

エラーハンドリング・リトライ・コスト最適化
本番運用で必ず必要になるのが、エラー時の挙動制御と請求コントロールです。
典型的なエラーと対処
- 429 Too Many Requests: レート制限に到達。並列度を下げ、指数バックオフでリトライ
- 5xx 系: Bright Data 側の一時的な問題。3〜5 回までリトライ、それでもダメなら別ゾーンや別エンジンにフォールバック
organic_resultsが空配列: クエリが対象エンジンで結果ゼロ、もしくはパース失敗。クエリ正規化を再確認- タイムアウト (30 秒超): location や num_results が大きすぎる可能性。パラメータを見直す
リトライ戦略
tenacity ライブラリを使った指数バックオフが弊社の標準です。
from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception_type
import httpx
@retry(
stop=stop_after_attempt(5),
wait=wait_exponential(multiplier=1, min=2, max=30),
retry=retry_if_exception_type((httpx.HTTPStatusError, httpx.TimeoutException)),
)
async def safe_fetch(client, query):
# ...
pass
3〜5 回までリトライする設定にして、それでも失敗するクエリは別途キューに退避し、後から手動レビューする運用が現実的です。
コスト最適化のチェックリスト
- キャッシュ層を必ず挟む: 同じ (query, country, language) で 24 時間キャッシュ。Redis の TTL で実装
- クエリ正規化: トリム・大文字小文字統一・全半角統一でキャッシュヒット率を上げる
- num_results を最小限に: top 10 で足りるなら 10 に固定
- 失敗クエリのリトライ上限: 5 回までで打ち切り、無限ループを防止
- モニタリング: 成功率・平均レイテンシ・課金リクエスト数を Datadog や Grafana で可視化
CAPTCHA に頻繁に遭遇するサイトを SERP API 経由でアクセスする際の細かい設定は、Bright Data Web Unlocker 実践活用ガイド 2026 と組み合わせて読むと、検知耐性の高い構成設計の解像度が上がります。
弊社運用事例とまとめ - SERP API は "用途を絞って" 使う
弊社では、Bright Data の Residential プロキシ・Web Unlocker・SERP API を組み合わせたホテル価格追跡サービス Tra-bell を自社で運用しています。Tra-bell では、競合 OTA のキーワード順位や検索 UI 変化を SERP API で日次トラッキングし、得られたシグナルを Bright Data Residential 経由の本体スクレイピングと連動させてアラート化する構成を組んでいます。
実運用してきた経験から言える「SERP API を導入して良かった点」と「導入後に必要になった工夫」を端的にまとめると次の通りです。
- 良かった点: 自前 Playwright でやっていた SERP 取得を SERP API に置き換えたところ、保守工数が月 15 時間→2 時間に圧縮できた。bot 検知の運用ストレスから解放された
- 工夫が必要だった点: 初期のクエリ正規化が甘く、同じ意味のクエリでキャッシュヒットしない問題が発生。トリム + 大文字小文字統一 + 全角半角正規化を入れて 40% コスト削減
- 判断ミスだった点: num_results を 100 で固定していた時期があり、転送料が無駄に発生。実際は top 20 で十分だったケースが大半だったので 20 に絞った
同様の SERP 取得基盤の設計・PoC・運用までは要件次第でご相談可能です。
Bright Data 上に構築した Tra-bell の構成や、SERP API + Residential を組み合わせたスクレイピング基盤のリファレンス構成は下記から確認できます。
結論
Bright Data SERP API は、Google や Bing の検索結果を構造化 JSON で取得できる SERP 特化 API です。Python から叩く際は、認証は Bearer トークン、最小実装は requests + JSON ペイロード、大量リクエストには httpx + asyncio + tenacity という構成が定石でした。コスト最適化はキャッシュ層・クエリ正規化・num_results 最小化の 3 点で大半が達成できます。法的観点では「検索結果は公開情報だが、二次利用は別問題」を念頭に、本番投入前に法務レビューを 1 回挟むことを強くお勧めします。同じカテゴリの上位プレイヤーを横並びで見たい場合は Bright Data vs Oxylabs 徹底比較 2026 も併せて確認するとプラットフォーム選定の意思決定が早まります。
※情報は 2026-05-21 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
よくある質問
関連記事


Bright Data Web Unlocker 実践活用ガイド 2026 - CAPTCHA突破とコスト設計
