
Bright Data vs Apify 徹底比較 2026 - プロキシ品質と Actor 柔軟性の見極め方
Bright Data と Apify の差を、料金体系・成功率・運用工数の 3 軸で実運用目線で整理。中小〜大規模どちらに寄せるかの判断軸を提示します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
「Bright Data と Apify、どちらを選ぶべきか」は、スクレイピング基盤を本気で組む企業から繰り返し受ける質問です。結論を先に言うと、Bright Data は IP プールと成功率を売るインフラ、Apify は既製 Actor と柔軟性を売るアプリで、競合というより役割が違います。本記事では料金・成功率・運用工数の 3 軸で違いを整理し、中小規模で始めるか大規模で本気投入するかの判断軸を提示します。
1. 両者の立ち位置を 1 枚で理解する
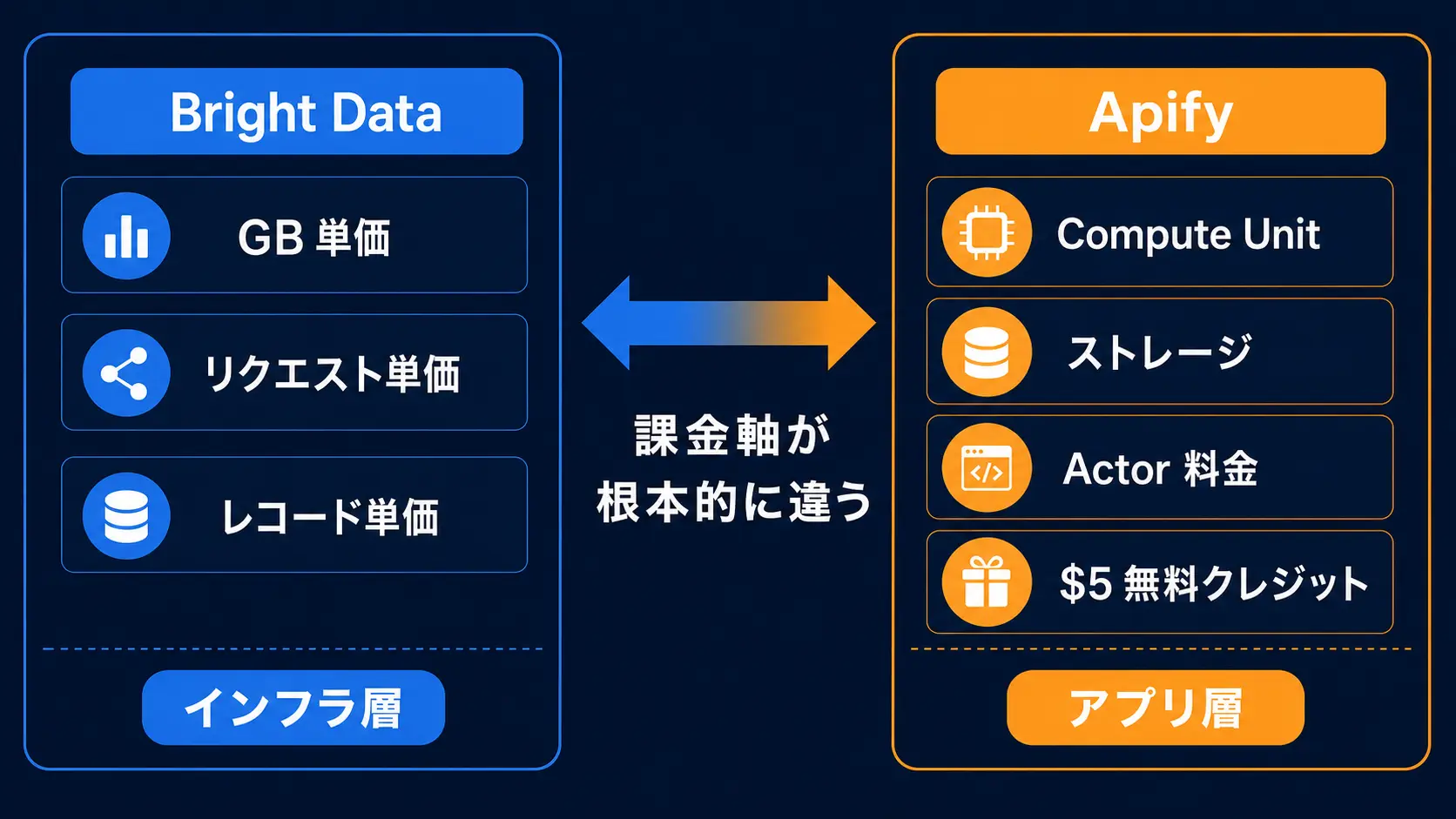
Bright Data はプロキシネットワークを核に Web Unlocker / SERP API / Scraping Browser / Dataset Marketplace まで提供する「インフラ + プラットフォーム」型の製品です。一方の Apify は Actor と呼ばれるクラウド scraper コンテナをホスティングし、Actor Store で第三者製のスクレーパーを購入・実行できる「アプリケーションレイヤー」のサービスです。
1-1. 製品ラインナップの違い
| 軸 | Bright Data | Apify |
|---|---|---|
| 主軸プロダクト | Residential / Datacenter / ISP / Mobile Proxy | Actor (クラウド scraper) と Actor Store |
| ノーコード手段 | Dataset Marketplace (既製データ販売) | Actor Store の Run ボタンで即実行 |
| 高難度サイト対策 | Web Unlocker (CAPTCHA / Cloudflare 自動突破) | Crawlee SDK + プロキシ統合 (自前実装) |
| SERP データ取得 | SERP API (構造化 JSON で返却) | Google Search Actor 等を Actor Store から購入 |
| IP プール規模 | 1.5 億 IP / 195 か国 (公表値) | 自前プロキシ + 外部プロキシ統合 |
Bright Data は IP の品質と量 で勝負し、Apify は Actor の数と開発者体験 で勝負しているという棲み分けです。
1-2. 「どちらが上か」は使い方次第
X 上の比較発言を 2026 年 5 月時点で追うと、対象サイトと用途によって優劣が大きく入れ替わります。たとえば SNS のユーザープロフィールや投稿データの取得では Apify の Actor が Bright Data 直接利用より優位という報告があります。
「ユーザープロフィールや投稿データの取得では、Apify の Actor の方が Bright Data より明らかに優れている」(原文: Apify's Actors outperform Bright Data for user profile and post data scraping.)
これは Apify が当該サイト向けにチューニングされた Actor を持っているからで、IP 品質だけでは埋まらない差です。Bright Data の料金体系を先に押さえたい方は Bright Data 料金プラン早見表 2026 も参照してください。
2. 料金体系の根本的な違い
両者とも従量課金ですが、課金単位が違うため単純比較が難しいのが実情です。
2-1. Bright Data の課金軸
- Residential Proxy: $15/GB から開始、月間ボリュームで段階的に割引
- Datacenter Proxy: $0.5/GB から、IP 静的契約も可能
- Web Unlocker: $3/1,000 リクエストから、成功課金 (失敗は課金されない)
- SERP API: $3/1,000 リクエストから、検索結果を構造化 JSON で返却
- Dataset: レコード単価制 (高ボリュームで $0.001/レコードまで下がる)
ボリュームディスカウントが強く、月 50 万レコードを超える大規模利用では実効単価が大きく下がります。
2-2. Apify の課金軸
- Compute Unit (CU): Actor 実行時間 + メモリ消費に応じて課金
- データセット保存量: GB 単位で保存料金
- Proxy 帯域: Apify Proxy 利用時の帯域課金
- Actor 利用料: Actor Store の有償 Actor は作者が単価を設定 (月額型・実行型・レコード型)
- 無料枠: 新規ユーザーに $5 のクレジット付与
Compute Unit は実行マシンの規模で消費量が変わるため、コードの効率が直接コストに跳ね返ります。
2-3. 大規模利用ではレコード単価で逆転する
X では「月 50 万レコード超になると Bright Data の方が単価で勝つ」という指摘が複数見られます。
「月 50 万件を超える大規模利用では、Bright Data の $0.001/レコードという課金が割安になり、出力フォーマットの統一性とスケール面でも有利」(原文: At >500K records/month, Bright Data's $0.001/record pricing wins, with better output consistency and scalability.)
Apify は無料枠と中量域では魅力的ですが、ボリュームが膨らんで Compute Unit の消費が増えると割高に転じます。中規模までは Apify、大規模に振るタイミングで Bright Data という移行戦略は理にかなっています。
3. 成功率と運用工数で見る実用評価
「安いほうを選ぶ」は短期では正しいですが、失敗率が高いとリトライで結局コストが膨らむ ため、実効単価で比較する必要があります。弊社が PoC でよく取るアプローチを書きます。
3-1. 同一タスクで両者を 1,000 件ずつ叩いて比較する
- 同じ URL リスト (例: 商品詳細ページ 1,000 件) を用意する
- Apify は対象サイト向け Actor を選ぶか、Crawlee で自前実装する
- Bright Data は Web Unlocker を直接叩く構成にする
- 成功率・所要時間・実コストを記録する
- 実効単価 = 課金額 ÷ 成功件数で比較
弊社のホテル価格追跡サービス Tra-bell でも、新規ターゲットを追加する際は必ずこのフォーマットで判断しています。実運用感では、Akamai / Cloudflare が立っているサイトでは Bright Data の Web Unlocker、ロングテール EC では Apify Actor の方が立ち上がりが速い傾向です。
3-2. 運用フェーズの違い
| 観点 | Bright Data | Apify |
|---|---|---|
| 立ち上げまでの工数 | プロキシ設定・成功率チューニングが必要 | 既製 Actor なら数分で開始可能 |
| 出力フォーマットの統一性 | API レスポンス統一、扱いやすい | Actor ごとにスキーマが違いやすい |
| 障害時の切り分け | プロキシ層と自前コードで分担明確 | Actor 内部の不具合は外から見えにくい |
| 法務・コンプライアンス | KYC 済み IP / GDPR / CCPA 公式対応 | Actor 開発者ごとに対応がバラバラ |
| 公開ターゲットの追加 | 自前実装が必要 | Actor Store にあれば即対応 |
3-3. ハイブリッド構成という第三の選択肢
実は X でも 2026 年に入ってから「両方使う」という運用報告が増えています。Apify Actor のプロキシ設定欄に Bright Data のエンドポイントを差し込むだけで、Actor の手軽さと Residential の成功率を両取り できます。
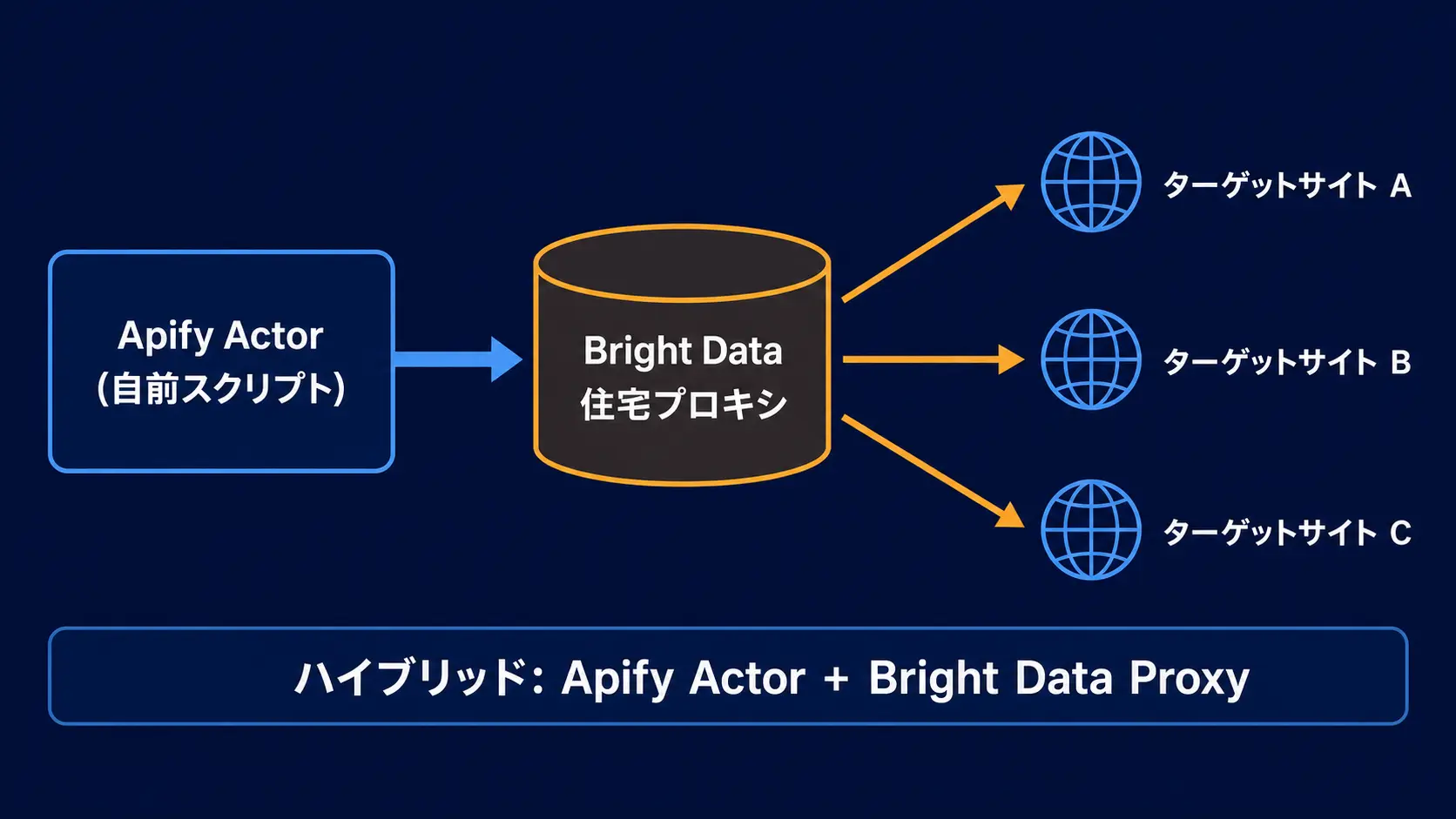
弊社の現場でも「最初は Apify Actor、規模が見えてきたら Bright Data に寄せる」というステップアップ移行を顧客に提案することが多いです。詳細な競合比較は Bright Data vs Oxylabs 徹底比較 2026 でも整理しています。
4. 用途別おすすめ早見表
実プロジェクトでよく出てくる 5 つの用途で、どちらに寄せると合理的かを整理します。
| 用途 | 推奨 | 理由 |
|---|---|---|
| EC 価格モニタリング (月数十万件以上) | Bright Data | Web Unlocker + Residential で成功率高、レコード単価も低下 |
| Google SERP 監視 | Bright Data | SERP API が構造化 JSON で返却、保守工数が小さい |
| LinkedIn / Instagram のプロフィール収集 | Apify | 対象サイト向けの Actor が成熟、即時起動できる |
| 新規サイトの PoC スクレイピング | Apify | 無料枠 $5 と Actor Store で立ち上がりが早い |
| 大規模 AI 学習データ収集 | Bright Data + Apify ハイブリッド | コストと網羅性のバランスが取れる |
CAPTCHA 突破まわりの設計は Bright Data Web Unlocker 実践活用ガイド 2026 を併せて読むと判断が早いです。
5. 集中型サービスへの依存リスクと向き合う
両社とも 2026 年も成長を続けていますが、X では「集中型サービスの料金高騰や単一障害点リスク」を懸念する声も増えています。
「Bright Data や Apify のような集中型サービスは規模が大きくなると料金が高騰し、単一障害点リスクも抱える。そこで分散型の代替案を探す動きが出てきている」(原文: Centralized services like Bright Data and Apify get expensive at scale and have single-point-of-failure risks; decentralized alternatives are emerging.)
分散型・去中央化のスクレイピング基盤はまだ実用段階に達していませんが、ベンダーロックインの観点では現実的なリスクです。弊社では以下のような設計指針を顧客に提案しています。
- プロキシレイヤーは抽象化して Bright Data / Apify / 自前のいずれも差し替え可能にする
- データ層 (BigQuery / Snowflake) は自社管理で残す
- リトライ・ジョブキューは自前 (AWS SQS / Lambda 等) で持ち、ツール側に閉じ込めない
こうした設計の組み立てや、Bright Data の Residential Proxy を実プロダクションで使ったベストプラクティスは、要件次第で弊社からご支援可能です。詳しくは Bright Data Residential Proxy で価格モニタリング基盤を構築する方法 でも触れています。
6. 自社事例: Tra-bell の Bright Data 採用理由
弊社では、Bright Data の Residential Proxy と Web Unlocker を使ったホテル価格追跡サービス Tra-bell を自社で運用しています。Apify との比較検討も初期に行いましたが、毎日数十万 URL を高成功率で叩く必要があり、Bright Data の IP 規模とコンプライアンス文書の整備度合いが決め手になりました。
同様の本番運用基盤の設計・PoC・コスト最適化は、規模感と要件次第で弊社からご相談可能です。
7. まとめ - 規模と対象サイトで切り分ける
Bright Data と Apify はライバルというより役割が違うサービスです。中小規模・PoC・対象サイト向け Actor がある場合は Apify、大規模・高成功率要求・SERP / EC の継続監視では Bright Data が定石です。両方を併用するハイブリッド構成も実運用では有力で、規模が育つにつれて自然に移行する企業が増えています。料金単価だけでなく「成功率を加味した実効単価」で判断するのが鉄則です。
※情報は 2026-05-21 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
よくある質問
関連記事


