
Bright Data vs Zyte 徹底比較 2026 - プロキシ規模と AI 自動抽出で選ぶスクレイピング基盤
Bright Data と Zyte (旧 Scrapinghub) を 2026 年最新情報で比較。プロキシ規模・Web Unlocker・SERP API と、Zyte の Scrapy Cloud・AI 自動抽出を実運用目線で整理し、ユースケース別の選び方と弊社の運用知見を解説します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
「Bright Data と Zyte (旧 Scrapinghub)、結局どちらを選べばいいのか」は、スクレイピング基盤を立てるチームから繰り返し聞かれる質問です。本記事では本記事執筆時点 (2026 年 5 月) の最新情報をもとに、両社の強みを公平に整理します。結論を先に言えば、巨大なプロキシ規模・アンロック・SERP を軸に基盤を組むなら Bright Data、Scrapy エコシステムと AI 自動抽出で実装と保守を減らすなら Zyte が向きます。弊社が Bright Data を本番運用してきた知見もまじえて、机上比較では見えない判断軸まで踏み込みます1。
Bright Data と Zyte の立ち位置
両社ともデータ収集領域の有力プレイヤーですが、得意とする層が少し異なります。Bright Data はプロキシインフラとアンロックの規模で、Zyte はスクレイピング開発の体験と AI 抽出で評価されてきました。
Bright Data の立ち位置
Bright Data (旧 Luminati) は 2014 年創業、イスラエルに本社を置きグローバルに展開する老舗のリーダーです。4 億 IP を超える世界最大級の Residential プールを中心に、Web Unlocker・Scraping Browser・SERP API・Dataset Marketplace まで含む幅広いラインアップが強みで、「とにかく規模と取得の確実性が欲しい」エンタープライズ用途で選ばれます2。
Zyte の立ち位置
Zyte は Scrapy の生みの親が母体となった企業で、旧称 Scrapinghub の頃から開発者フレンドリーなポジションを築いてきました。Scrapy Cloud (Scrapy スパイダーのマネージド実行基盤)、Automatic Extraction (AI による構造化抽出)、Zyte API (スマートプロキシ + レンダリング) を軸に、「コードと保守を最小化したい」開発チームに刺さるプロダクト設計です3。
共通する強み
- 倫理的な IP / データ取得: 両社とも robots.txt 遵守やオプトアウト、GDPR / CCPA / 個人情報保護法対応を公開
- JavaScript レンダリング対応: SPA や動的サイトの取得に両社とも対応
- エンタープライズ向けの体制: SLA・カスタムプラン・デモ対応
- 使用量ベースの課金: 従量課金 + ボリュームディスカウント + 無料/低額トライアル
両社を「同じデータ収集でも軸が違う 2 社」として捉えると、比較がぐっと整理されます。プロキシ専業同士の比較は Bright Data vs Oxylabs 徹底比較 2026 でも扱っているので、純プロキシ視点での見極めはそちらも参考になります。
比較表で見る Bright Data と Zyte の全体像
細かな機能に入る前に、観点ごとの優劣を一覧で押さえておきましょう。下表は本記事執筆時点での整理で、価格はいずれも目安です。
| 観点 | Bright Data | Zyte (旧 Scrapinghub) |
|---|---|---|
| プロキシ網の規模 | 4 億 IP 超、195 か国、都市/ASN/キャリア指定 | Zyte API 内蔵のスマートプロキシ (単体大規模プールの販売は控えめ) |
| アンロック | Web Unlocker (Cloudflare/Akamai/DataDome を自動突破) | Zyte API にローテーション/レンダリング統合 |
| AI 自動抽出 | Web Scraper IDE + AI 補助 (柔軟だが実装寄り) | Automatic Extraction が一歩リード (コードレス構造化) |
| Scrapy 連携 | Python 対応だが Scrapy 専用基盤は無し | Scrapy Cloud が本領 (デプロイ/スケジュール/監視) |
| SERP API | 専用 SERP API が成熟 (Google/Bing 等) | 専用 SERP API は無し (汎用 API で代替) |
| 既製データ | Dataset Marketplace で購入可 | 既製データセット販売は限定的 |
| 課金単位 | GB (プロキシ) / リクエスト (Unlocker・SERP) | リクエスト/コンピュートユニット (API) / 稼働時間 (Scrapy Cloud) |
| 向いている層 | データベンダー・大規模収集・AI エージェント基盤 | Python/Scrapy チーム・構造化データ重視 |
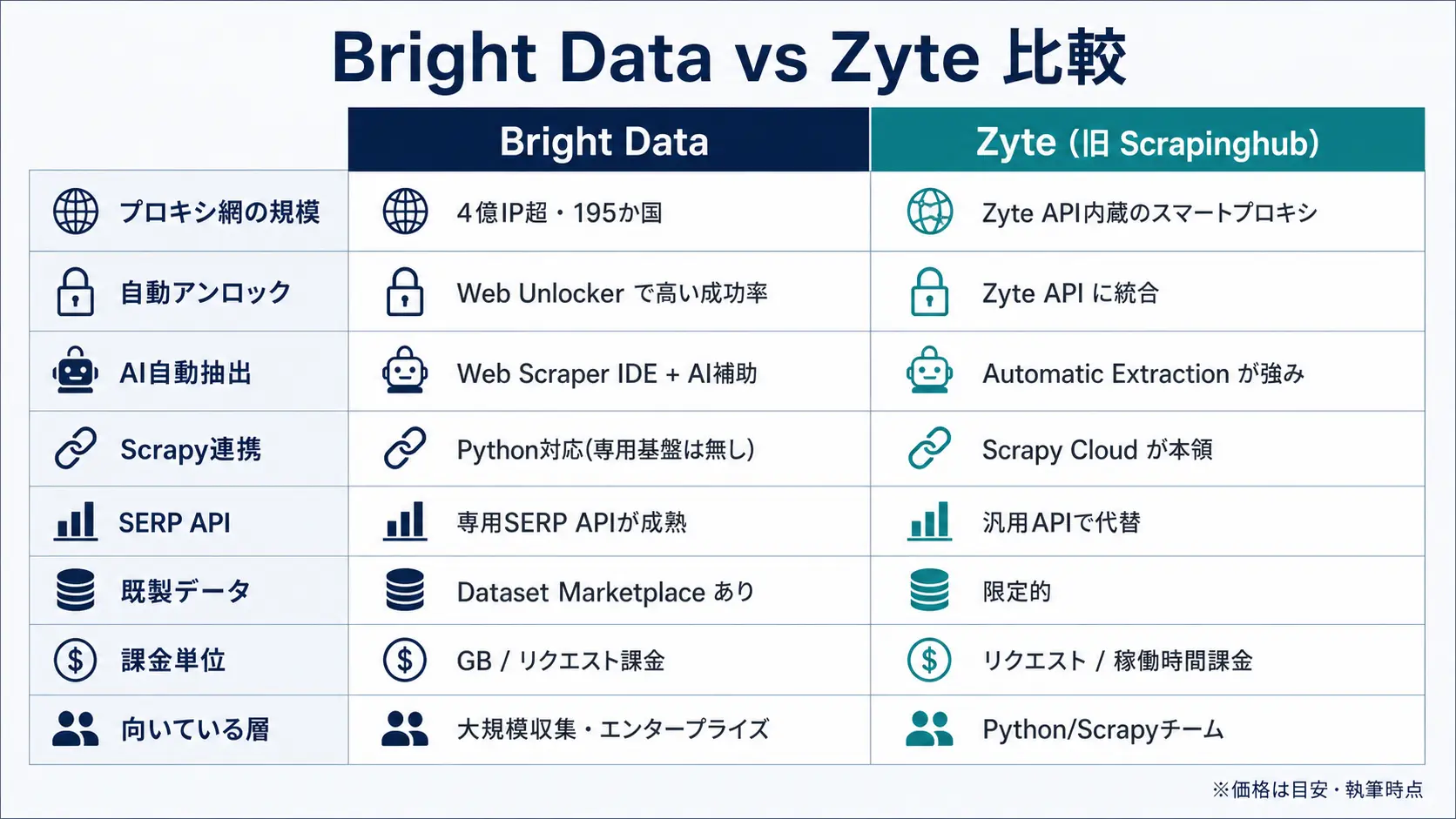
ざっくり言えば、Bright Data は「取得インフラの広さと確実性」、Zyte は「整形済みデータと Scrapy 運用の手離れ」で勝負しています。料金体系の細部は別記事の Bright Data 料金プラン早見表 2026 で製品別に整理しているので、Bright Data 側の単価詳細はそちらも合わせてご確認ください。
プロキシ・アンロック・SERP は Bright Data が優位
「検知の厳しいサイトを、止まらずに、大規模に取得する」要件では Bright Data が頭一つ抜けています。ここは Zyte が主戦場にしていない領域です。
プロキシ網の規模と地理カバレッジ
Bright Data の Residential プールは 4 億 IP を超える規模で、国・都市・ASN・キャリア単位の細かいターゲティングができます。Zyte もスマートプロキシを Zyte API に内蔵していますが、単体の巨大プールを「生のプロキシ」として売る姿勢は控えめで、あくまで統合スクレイピングソリューションの一部という位置づけです。住宅 IP の出所多様性とローテーション設計の幅では Bright Data が優位です。
Web Unlocker による自動アンロック
Bright Data の Web Unlocker は、プロキシ選択・フィンガープリント・ヘッダー・リトライを自動で組み合わせ、Cloudflare・Akamai・DataDome といった高度なアンチボットを突破する API です。X 上でも「AI エージェントや Cloudflare 保護サイトに対して信頼でき、きれいな構造化 JSON が返る」という実体験が共有されています4。
「Bright Data の Web Unlocker は AI エージェント用途で信頼でき、Cloudflare 保護サイトでもきれいな構造化 JSON を返してくれる」(原文: Bright Data's Web Unlocker is reliable for AI agents and Cloudflare-protected sites, often returning clean structured JSON.)
アンチボットの更新追従の速さは、長期運用するスクレイパーの「止まらなさ」に直結します。ここは Zyte の Zyte API も健闘しますが、専用プロダクトとして磨き込んだ Bright Data に分があります。
SERP API とデータマーケットプレイス
Google / Bing 等の検索結果を構造化 JSON で取得する専用 SERP API は Bright Data の成熟領域で、AI エージェントのワークフローでも Web Unlocker と並んで好評です5。Zyte には旗艦としての専用 SERP API が無く、汎用 API で組む必要があるぶん手間がかかります。加えて Bright Data は Dataset Marketplace で既製データを購入できるため、自前スクレイパーの保守を丸ごと外せる選択肢もあります。SERP 自動化の実装手順は Bright Data vs Smartproxy 徹底比較 2026 でも周辺機能に触れています。
Zyte の強み: Scrapy Cloud と AI 自動抽出
公平に見て、Zyte には Bright Data が持たない明確な強みがあります。ここを見落とすと「プロキシは強いのに開発が重い」という判断ミスにつながります。
Automatic Extraction (AI 構造化抽出)
Zyte の Automatic Extraction は、機械学習モデルで商品・価格・レビュー・記事・求人といった定番ページから構造化データを取り出す機能です。カスタムパーサーをほぼ書かずに高い初期精度が出て、サイト構造が変わっても壊れにくいのが最大の利点です。「パーサー保守に毎月工数を取られている」チームには、ここが効きます。Bright Data の Web Scraper IDE や AI 補助でも構造化はできますが、実装と後処理がやや多めになる傾向があります。
Scrapy Cloud
Scrapy Cloud は Scrapy スパイダーのデプロイ・スケジュール・スケール・監視・データ保存をまるごと面倒見てくれるマネージド SaaS です。Git 連携、オートスケール、ダッシュボード、データパイプライン、エクスポートが揃い、無料/開発ティアもあります。Python と Scrapy を主軸にするチームにとっては、これに相当する基盤を Bright Data 側に求めても見つからないため、Zyte の独壇場です。
料金面でのバランス
Zyte API はリクエスト/コンピュートユニット課金で、自動抽出が無駄な帯域を削るため「整形済みデータ単位」では効率的になりやすい構造です。一方 Bright Data はスケールやアンロック価値が高い場面でコスト効率が出ますが、用途によっては割高と評する声もあります6。
「Bright Data は特定用途だと割高に感じるが、大規模運用やアンロック価値が高い場面ではコスト効率が良い。最良単価には最低利用額や契約が必要なこともある」(原文: Bright Data is pricey for some use cases, but cost-effective at high scale or when unblocking value is high; minimum spends or commitments may apply.)
つまり「生 GB を大量に処理するか」「整形済みデータを少ない実装で得たいか」で、コストの有利不利が入れ替わります。
ユースケース別の選び方
実務でよくある 4 つのケースで「どちらを軸にするか」を整理します。下の意思決定フローも合わせてご覧ください。

ケース 1: 検知の厳しいサイトを大規模取得
- 推奨: Bright Data (Residential + Web Unlocker)
- Cloudflare / Akamai / DataDome 突破と IP プール規模が活きる
- 既存スクレイパーを Web Unlocker 化すればコード追加が最小
- Apify のような Actor 型 SaaS との比較は Bright Data vs Apify 徹底比較 2026 も参照
ケース 2: Python / Scrapy チームの定常運用
- 推奨: Zyte (Scrapy Cloud + Automatic Extraction)
- スパイダーのデプロイ・監視・スケールを SaaS に任せられる
- 定番ページの構造化をコードレスで回せる
- 検知の厳しいサイトだけ Bright Data のプロキシに逃がす併用も有効
ケース 3: SERP / 検索結果の継続監視
- 推奨: Bright Data SERP API
- 専用 API で構造化 JSON が安定、開発工数が小さい
- Zyte は汎用 API で組む必要があり手間が増える
ケース 4: 既製データを買いたい / AI 学習データ収集
- 推奨: Bright Data (Dataset Marketplace)
- 検証済みの既製データセットを購入でき、法務リスクも低い
- 大規模な Web データ収集の文脈でも Bright Data が挙がりやすい
併用時の注意点と運用設計
「どちらかに決め切る」必要はありませんが、併用には運用負荷が伴います。設計の勘所を押さえておきましょう。
役割分担の考え方
- 取得 (アクセス): 検知の厳しいサイトは Bright Data の Web Unlocker / Residential
- 構造化 (抽出): 定番ページは Zyte の Automatic Extraction
- オーケストレーション: Scrapy 主体なら Scrapy Cloud、汎用基盤なら自前の Lambda / Cloud Run
弊社の運用知見と支援メニュー
弊社では Bright Data を 2 年以上本番運用してきており、Zyte を含む主要サービスの比較検証も複数案件で行ってきました。「プロキシで確実に取れる構成にしたら保守が軽くなった」「抽出だけ別ツールに分けてコスト最適化した」など、机上比較では見えない地雷と勝ち筋を蓄積しています。
提供メニューの一例:
- 用途別の Proxy Zone 設計 (価格モニタリング / SERP 監視 / SNS 分析 などの組み合わせ)
- Bright Data ↔ Zyte の比較トライアル設計と成功率測定
- スクレイピング基盤の構築 (AWS Lambda / Cloud Run + Bright Data + S3 + Snowflake)
- データ分析基盤への接続 (BigQuery / Snowflake / dbt パイプライン)
- コスト最適化 (Residential / Datacenter / Web Unlocker の組み合わせ最適化)
- コンプライアンス整備 (robots.txt 遵守、レート制御、利用規約レビュー)
弊社では、Bright Data の Residential プロキシと Web Unlocker を使ったホテル価格追跡サービス Tra-bell を自社で運用しています。Zyte を含む競合の検証経験もあるので、PoC 段階からの設計相談も対応可能です。
まとめ
Bright Data と Zyte は「同じデータ収集」でも軸が異なる 2 社です。Bright Data は 4 億 IP 超のプロキシ規模・Web Unlocker・SERP API・Dataset Marketplace を強みに、取得の確実性とスケールでリードします。Zyte は Scrapy Cloud と Automatic Extraction を武器に、構造化データの取得と保守の手離れで優位に立ちます。検知突破とスケールが要件なら Bright Data、Python/Scrapy 主体で整形済みデータを最短で得たいなら Zyte、というのが基本線です。両社を役割分担で併用するハイブリッド構成も実務でよく選ばれており、本契約前のトライアル実測は欠かせません。Zyte 公式も「常に利用規約・robots.txt・各国法令を尊重すべき」と発信しており、合法的な公開データ収集を前提に設計するのが両社共通の作法です7。
「Web スクレイピングでは、対象サイトの利用規約・robots.txt・適用法令を常に尊重すべきだ」(原文: With web scraping, always respect terms of service, robots.txt, and applicable laws.)
※情報は 2026-05-31 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
Footnotes
-
Bright Data 公式 — https://brightdata.com/ ↩
-
Bright Data 製品ラインアップ — https://brightdata.com/proxy-types ↩
-
Zyte 公式 — https://www.zyte.com/ ↩
-
Web Unlocker のユーザー実体験 (X) — https://x.com/chriskrim2002/status/2059591971652407695 ↩
-
SERP API の評価 (X) — https://x.com/YaronBeen/status/2042863522669842757 ↩
-
Bright Data の価格に関するユーザー所感 (X) — https://x.com/_aurumX/status/2060312892885684677 ↩
-
Zyte 公式アカウントのコンプライアンス言及 (X) — https://x.com/zytedata/status/2046499235558830539 ↩
よくある質問
関連記事


