
Bright Data Webhook & Delivery 2026: S3, BigQuery, Snowflake
Bright Data Webhook and native S3 / BigQuery / Snowflake delivery compared by payload, retries, and ownership — a decision framework for production.

This article contains affiliate links (advertising).
If your real question is "how do I get Bright Data scraping output into our systems on a daily basis?", the answer lives in the delivery layer. Webhooks excel when latency matters; native S3, BigQuery, and Snowflake routes win for analytics and warehousing. This guide compares payloads, retry semantics, cost, and operational ownership for both — drawn from running Bright Data in production at Smile Comfort — so you can make a decision you will not have to redo in six months.
1. Why the Delivery Layer Is the Real Bottleneck
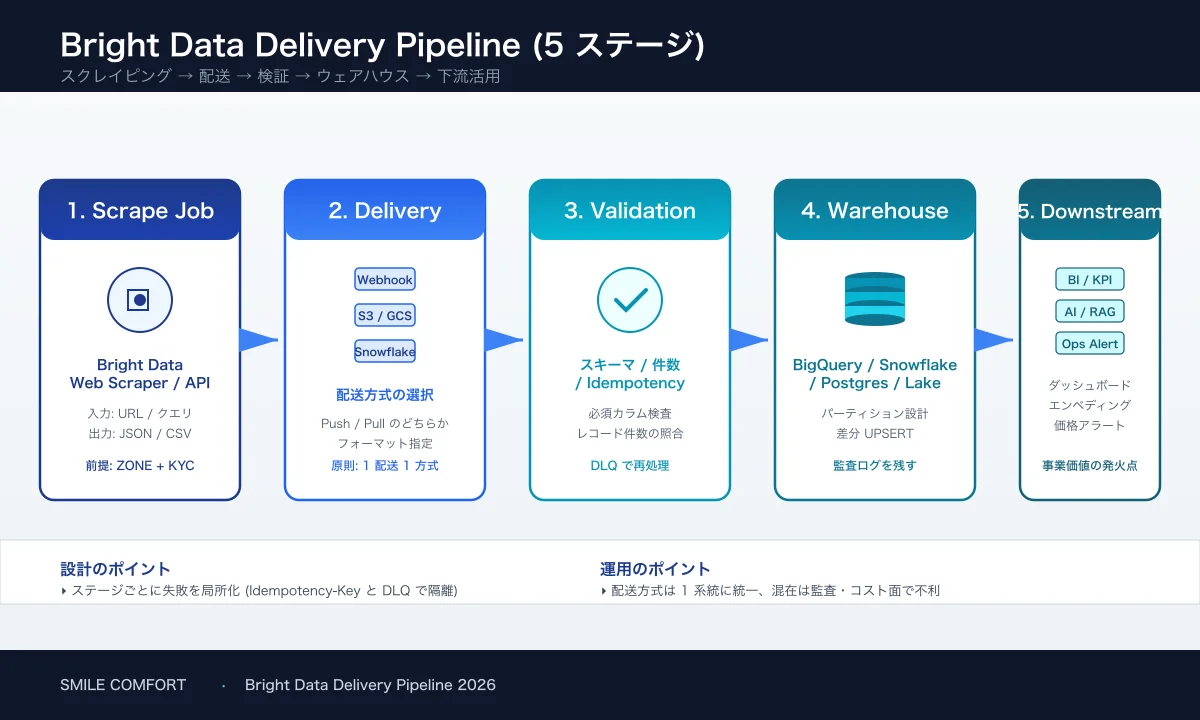
The output of the Bright Data Web Scraper API or Dataset Marketplace is, by default, just "JSON sitting on the dashboard once the job finishes." In production, getting that data into your systems and BI or DWH continuously is what ultimately determines reliability.
1.1 Common Failure Modes in the Delivery Layer
Across our own work and what we see in other teams, three failure modes dominate:
- Pull-only via cron: Hourly cron scripts that "download the latest file" inevitably skip or duplicate when job completion drifts off the cron schedule.
- Webhook overload: Large-payload jobs back up the receiver, which returns 500, which triggers retry storms.
- Schema drift left unmanaged: Key names or types change on the delivered JSON, and downstream tables silently break — analytics stops without anyone noticing.
Bright Data ships Webhooks and native delivery side by side, so all three are solvable architecturally. The flip side is that if you do not pick one upfront and start with "just download JSON," you will rebuild the pipeline within a year.
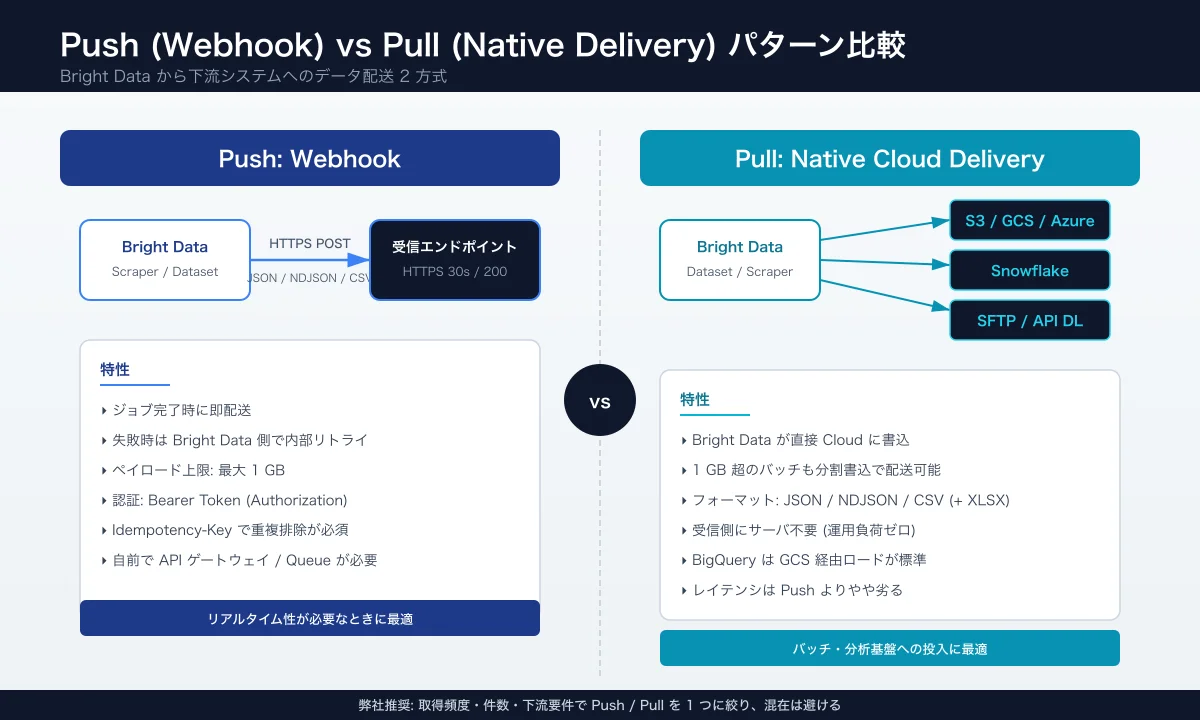
1.2 Push (Webhook) vs Pull (Native Delivery)
The division is "who owns the responsibility to deliver the data?":
| Aspect | Webhook (Push) | Native Delivery (S3 / Snowflake / GCS) |
|---|---|---|
| Direction | Bright Data → your endpoint | Bright Data → cloud storage / DWH |
| Real time | Excellent (on job completion or threshold) | Moderate (batched, minutes to hours) |
| Receiver burden | High (uptime, auth, idempotency) | Medium (only permissions and target) |
| Payload | JSON / JSONL / CSV / NDJSON, up to 1 GB1 | JSON / CSV / NDJSON / Parquet |
| Use cases | Price alerts, agent triggers, immediate ops | Analytics, DWH loads, RAG vectorization |
| Retries | Yes, until HTTP 200 returned within 30 seconds1 | Yes, internal to Bright Data |
For how this fits inside an end-to-end scraping platform, see AWS Lambda x Bright Data: Serverless Scraping Pipeline 2026, which puts the delivery layer in a broader infrastructure context.
2. Designing Webhook Delivery and Real-Time Use Cases
Webhooks let Bright Data POST to an HTTPS endpoint you provide, fired on job completion or when a record-count threshold is hit. They are the default option whenever you want to react to data the moment it arrives.
2.1 Webhook Payload, Format, and Auth
Payloads arrive as JSON (one object per record) or JSONL (newline-delimited). Bright Data lets you control:
- Format: JSON, JSONL, CSV, NDJSON (Parquet is reserved for Marketplace native delivery)
- Auth: Bearer token via the
Authorizationheader (configured aswebhook_header_Authorization=Bearer+TOKENat Webhook setup) 1 - Trigger: On job completion, or chunked by record count 1
- Retries: Success requires HTTP 200 within 30 seconds; otherwise the request will be retried internally by Bright Data1
- Payload limit: Up to 1 GB per delivery. For larger or steadier flows, chunk by record count on the job side or switch to S3 delivery1
- Metadata: Job ID, dataset ID, record count, timestamps
On the receiver side, keep an idempotency key (job ID + batch ID) so retries cannot double-process records. At Smile Comfort we use DynamoDB or Redis as the idempotency store — if the same key arrives we return 200 and discard.
2.2 Receiver Implementation Patterns
Serverless dominates. The combinations we ship most often:
- AWS Lambda + API Gateway: Default for AWS shops. Lambda concurrency caps load naturally.
- Cloud Run / Cloud Functions: First choice on GCP. Cold starts are reasonable.
- Vercel Functions / Next.js API Routes: Quick to stand up, watch the payload limits.
- EC2 / Cloud Run on VPC: When you need direct VPC database access.
In practice, when payloads risk pushing Lambda's 15-minute ceiling, we route API Gateway → Lambda → SQS for buffering → worker Lambda for processing. That two-stage layout has saved us during traffic spikes more than once.
Smile Comfort summary: Some developers feel Bright Data's webhook and polling implementation is messier than simpler instant-response API alternatives — worth checking during vendor selection. (日本語訳: 「Bright Data の Webhook / ポーリング実装は競合より煩雑に感じる開発者もいる。シンプルな API レスポンスで完結できるかは選定時にチェックすべき」)
Adding a Webhook path does add receiver build-and-operate work. For short PoCs, native S3 delivery is often faster. "Is real-time actually a requirement?" is the cheapest question you can ask before designing the receiver.
2.3 Where Webhooks Shine
- Price alerts: Push competitor price drops or stockouts to Slack or email within five minutes.
- AI agent integrations: Stream scraped output into agent context the moment it arrives — fits well with MCP patterns covered in Bright Data MCP Server: A Practical Guide to Letting AI Agents Scrape for You 2026.
- Event-driven ops: Detect new reviews → run sentiment analysis → refresh a dashboard.
When the requirement is "daily batch into the DWH is fine," Webhooks are overkill. The next section moves to native delivery.
3. Native Delivery to S3, BigQuery, and Snowflake
Bright Data's Data Delivery feature writes results directly into cloud storage or your warehouse. You skip the receiver entirely, which collapses operational overhead.
3.1 Supported Targets and Credentials
As of May 2026, the targets listed on the official Marketplace data delivery / Datasets delivery options pages are23:
| Target | Auth | Primary use |
|---|---|---|
| Amazon S3 | IAM access key or AssumeRole | Data lake, backups |
| Google Cloud Storage | Service-account JSON | Data lake (GCP) |
| Google Cloud Pub/Sub | Service-account JSON | Real-time streaming |
| Microsoft Azure (Blob) | SAS or account key | Data lake (Azure) |
| Snowflake | Dedicated user / role / internal named stage3 | Analytics DWH |
| SFTP | Password or public key | Existing file-server ingestion |
| Webhook | (Custom auth header) | Real-time HTTPS POST |
| API download | API key | Small / ad-hoc usage |
| Email / download | None | Small or one-off uses |
BigQuery and Redshift are not listed as direct delivery targets as of May 20262. Because Bright Data does not officially offer direct delivery to BigQuery, we recommend a pattern where Bright Data writes to GCS or S3 and BigQuery loads via external tables, Dataflow, or BigQuery Data Transfer4. Treat the article's "BigQuery as the analytics destination" framing as "GCS-mediated load," not "direct delivery."
Configuration is a target plus credentials on the dashboard. Bright Data writes on whichever schedule you choose — on demand, on completion, daily, or hourly.
3.2 Output Format and Schema
You can pick JSON, NDJSON, CSV, XLSX, or Parquet (Parquet and XLSX are reserved for Marketplace native delivery into S3, GCS, or Snowflake-style destinations) 2. Parquet loads fastest into Snowflake and BigQuery (via GCS) and ships schema inference for free, so it is our default in production. XLSX is convenient when analysts want to inspect results directly in Excel or Google Sheets.
Bright Data provides UI for column selection, renaming, and type coercion on the delivery side. We still recommend a strict policy of not editing fields in Bright Data and absorbing all transforms in the application layer — that keeps downstream contracts honest.
3.3 Where Native Delivery Wins
- BI dashboards: BigQuery or Snowflake → Looker Studio, Tableau, Metabase.
- RAG and LLM training: Park Parquet in S3 / GCS → run embeddings (also discussed in Bright Data for LLM RAG Data Sources 2026: Designing Live and Batch RAG Pipelines).
- Catalog unification: Drop Amazon, Rakuten, and Yahoo! data from Dataset Marketplace into S3, then unify the master catalog (combine with Bright Data Dataset Marketplace 2026: Buy Ready-Made Data, Drop the Scraper Backlog).
- dbt pipelines: Load to DWH → transform with dbt → feed BI or ML.
Smile Comfort summary: Bright Data markets "hands-off data delivery" as one of its core selling points — the scraping plus delivery integration is itself a reason for selection. (日本語訳: 「Bright Data は『データ配送までハンズオフ』を訴求点にしており、スクレイピング + 配送が一体化している点が選定理由になっている」)
"Hands-off delivery" is an underrated Bright Data advantage. Apify or ScraperAPI sell the scraping mechanism; Bright Data also takes responsibility for the data landing in your chosen destination.
4. Payload Design and Idempotency on Failure
Whether you go Webhook or native, downstream quality eventually hinges on two properties: do not process the same record twice, and let any record be re-sent later.
4.1 Designing the Idempotency Key
Combine the following for a robust idempotency layer:
- Hash of
dataset_id + batch_id + record_idas a unique constraint - Stored 24 hours to 30 days in DynamoDB, Redis, or a Postgres unique index
- On duplicate: return 200 and drop (suppresses retry storms)
- Use upsert (merge) on the DWH side; avoid raw inserts
4.2 Retry Design
4.3 Our Production Pattern
The standard Smile Comfort Bright Data delivery design we run in production:
- Webhook → SQS (return 200 immediately).
- Same data → S3 via native delivery (backup and audit).
- SQS worker Lambda runs idempotency check → writes to DynamoDB; for BigQuery, loads land via GCS as Parquet.
- dbt normalizes the BigQuery tables → downstream BI, RAG, analytics.
- On failure, replay from S3 into the worker (insurance against lost Webhook payloads).
This setup buys real-time responsiveness and batch consistency simultaneously, plus a replayable trail. We tried Webhook-only and native-only first; each had operational pain points, and we now run them side by side. We can stand up similar infrastructure with you for production-scale work.
5. Conclusion
Bright Data's Webhook and native delivery features close the "last mile" between scraping infrastructure and your production systems. Webhook owns real-time use cases; native delivery owns analytics and warehousing. In production, the right answer is usually both — running in parallel, with idempotency keys and replay-ability baked in. Decide payload format and schema evolution policy upfront, and you will save yourself a six-month rebuild down the line.
The pattern we keep returning to is straightforward: treat Webhook as the signal and native delivery as the source of truth. Once you internalize that split, picking storage targets, retry policies, and DWH layouts becomes a matter of mechanical execution rather than open-ended design debate, and onboarding new pipelines drops from weeks to days. We use the same Bright Data + Webhook + Native Delivery combination on Tra-bell, our hotel price tracker that runs in production on Bright Data, where the parallel-delivery operational know-how continues to accumulate.
Information current as of 2026-05-24. Please check the official sites for the latest updates.
This article contains affiliate links.
Footnotes
-
Bright Data official docs - Webhooks delivery (Web Scraper API): https://docs.brightdata.com/datasets/scrapers/google/data-delivery/webhooks ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Bright Data official docs - Marketplace data delivery and export: https://docs.brightdata.com/datasets/marketplace/data-delivery-and-export ↩ ↩2 ↩3
-
Bright Data official docs - Scrapers library delivery options (Snowflake internal named stage): https://docs.brightdata.com/datasets/scrapers/scrapers-library/delivery-options ↩ ↩2
-
Google Cloud official docs - BigQuery external tables and BigQuery Data Transfer: https://cloud.google.com/bigquery/docs/external-data-cloud-storage ↩
Frequently asked questions
Related articles

Bright Data Dataset Marketplace 2026: Buy Ready-Made Data, Drop the Scraper Backlog

AWS Lambda x Bright Data: Serverless Scraping Pipeline 2026
