
Bright Data MCP Server for AI Agents: A 2026 Practical Guide
Connect Bright Data's MCP server to Claude or Mastra and let your AI agents scrape the open web with built-in bot bypass, observability, and cost guardrails.

This article contains affiliate links (advertising).
You want Claude or Cursor to scrape the open web for you, bot bypass included. The fastest way to get there in 2026 is the Bright Data MCP server. This guide walks through the protocol, the Bright Data MCP architecture, how to plug it into Claude Code and Mastra, and the cost and compliance pitfalls we have hit while running Bright Data in production. By the end you'll know whether MCP belongs in your stack.
1. MCP and Bright Data in 60 Seconds
The Model Context Protocol (MCP) is the open standard Anthropic released in late 2024 to wire LLMs to external tools. Claude Code, Claude Desktop, and Cursor act as reference clients and can talk to MCP servers for Slack, GitHub, Postgres, file systems, and crucially, web scraping. Bright Data rode that wave and shipped the Bright Data MCP server, exposing its proxy network, Web Unlocker, and SERP API as agent tools.
To the agent, calling search_engine or scrape_as_markdown looks like a normal function call. Under the hood, Bright Data picks proxies, bypasses CAPTCHAs, and renders JavaScript on your behalf. The internals are the same ones we covered in our Bright Data Web Unlocker Practical Guide 2026.
1.1 Why Bright Data Specifically
Built-in LLM web search and lightweight proxies hit predictable walls in production:
- High request rates from a single IP trigger 403 or 429 responses within minutes, especially on price-sensitive e-commerce domains
- JavaScript-heavy product pages and SERPs return empty payloads because lightweight HTTP clients cannot execute the page's render pipeline
- CAPTCHA, Cloudflare, or PerimeterX defenses interrupt collection at exactly the moment a price changes or a new product drops
- Geo-restricted content silently switches to a different version, leaving the agent with stale or misleading data
The Bright Data MCP server absorbs these problems with a 150M+ Residential IP pool, Web Unlocker, and geo-targeted exit nodes, letting agent code stay simple. That's the core value: the agent stops worrying about transport quality and focuses on extracting meaning.
1.2 Typical Use Cases
- Continuous price monitoring, review aggregation, job and real-estate signals collected on a schedule, then summarized by the agent
- "Research analyst" agents that sweep a new market in one shot, pulling SERP results, news, and competitor product pages into a single brief
- RAG pipelines that augment internal knowledge bots with fresh public web context — release notes, regulatory updates, or product launches
- Sneaker, ticket, and limited-stock monitoring loops where bot defenses are aggressive and uptime matters
- Internal copilots that need to verify a claim against a primary source before answering a customer ticket
2. Inside the Bright Data MCP Server
The Bright Data MCP server is open source on Node.js and ships via npx @brightdata/mcp. Set API_TOKEN to your Bright Data access token and the agent immediately gains the following tools.
| Tool | Purpose | Underlying Bright Data Product |
|---|---|---|
search_engine | Google / Bing / Yandex results as structured JSON | SERP API |
scrape_as_markdown | Convert any URL to Markdown | Web Unlocker |
scrape_as_html | Return raw HTML for any URL | Web Unlocker |
web_data_* | Site-specific structured extraction (Amazon, LinkedIn, Instagram, etc.) | Dataset / Web Scraper API |
scraping_browser_navigate and friends | Playwright-compatible stealth browser actions | Scraping Browser |
Agents see these as normal callable tools, complete with JSON schemas for arguments and return values. The diagram below shows how a single tool invocation fans out to the right Bright Data product, including the proxy rotation, JS rendering, and CAPTCHA bypass layers that stay hidden from the agent.
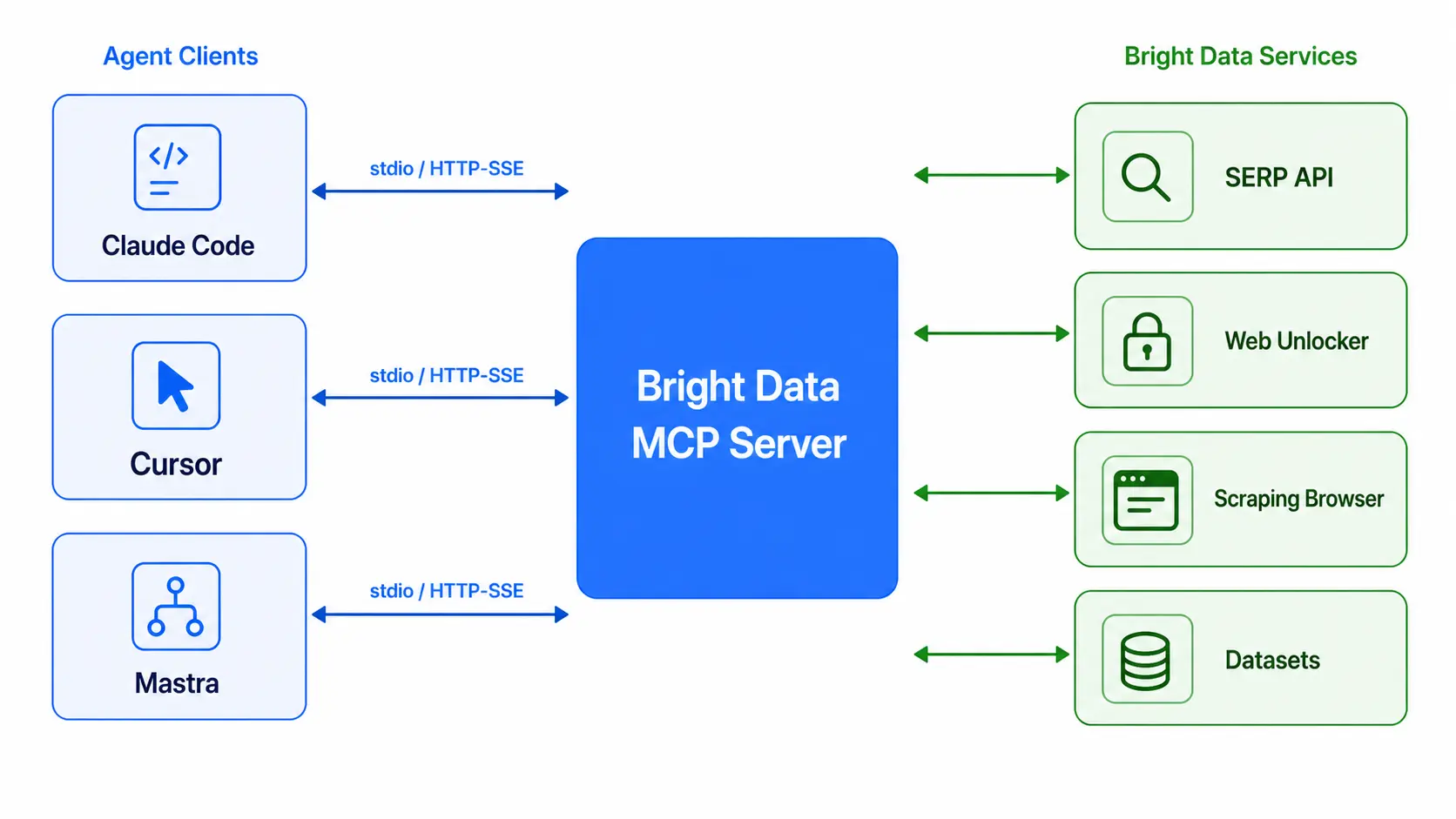
2.1 Transports and Authentication
MCP supports two transports: stdio and HTTP/SSE. Claude Desktop and Claude Code use stdio for local connections, which keeps the server lifecycle tied to the editor. Mastra or a custom backend usually picks HTTP/SSE because the server has to outlive a single chat session and serve multiple clients in parallel. Authentication is a Bright Data API token passed as an environment variable or HTTP header, and per-zone tokens are honored so you can isolate billing and permissions for different agents. Token issuance follows the KYC flow described in our Bright Data Account Setup 2026 guide — usually under 10 minutes after onboarding, assuming KYC documents are at hand.
2.2 Where Mastra Fits In
Mastra is a TypeScript multi-agent framework that added first-class Bright Data tools in May 20261.
"Mastra core v1.33.0 lets agents call Bright Data's anti-bot search and scraping tools directly." (Translated to keep parity with the Japanese version)
The trick is to compose Mastra agents and then expose the whole Mastra app as an MCP server back to Claude Code. You get orchestration, structured logging, retries, and evaluations on the Mastra side, with Bright Data tools tied in cleanly. The same Mastra build can also serve a Slack bot or a custom Next.js front end without touching the agent code, which matters when you want the same scraping logic available to humans through several surfaces.
3. Connect Bright Data MCP From Claude Code in Five Steps
Here's the shortest path to a working Claude Code or Claude Desktop setup.
- Issue an access token in the Bright Data console (Account Settings → API Tokens)
- Create one zone each for Web Unlocker and SERP API under
Manage Zones - Add the MCP server definition to
~/.config/claude-code/mcp.json(orclaude_desktop_config.jsonfor Desktop) - Restart Claude Code and verify the server and tools via
/mcp - Ask the agent to fetch a price or summary from any page using the new tools
A minimal config looks like this:
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "BRD_TOKEN_xxxxxxxx",
"WEB_UNLOCKER_ZONE": "unlocker_zone",
"BROWSER_ZONE": "scraping_browser_zone"
}
}
}
}
3.1 Troubleshooting the First Connection
The most common failures we see on day one:
- The API token is missing zone permissions — assign zones in the console
- A corporate firewall blocks
brightdata.comtraffic - Node.js is older than v20, so
npxcannot resolve the ESM bundle
When the agent surfaces a vague tool error, run npx @brightdata/mcp in a terminal directly. The standalone logs almost always reveal the root cause within the first few lines — missing zone permissions and DNS failures stand out immediately. If logs look fine but the agent still times out, check whether the agent's tool timeout is shorter than Bright Data's typical 20–30 second response on stubborn pages.
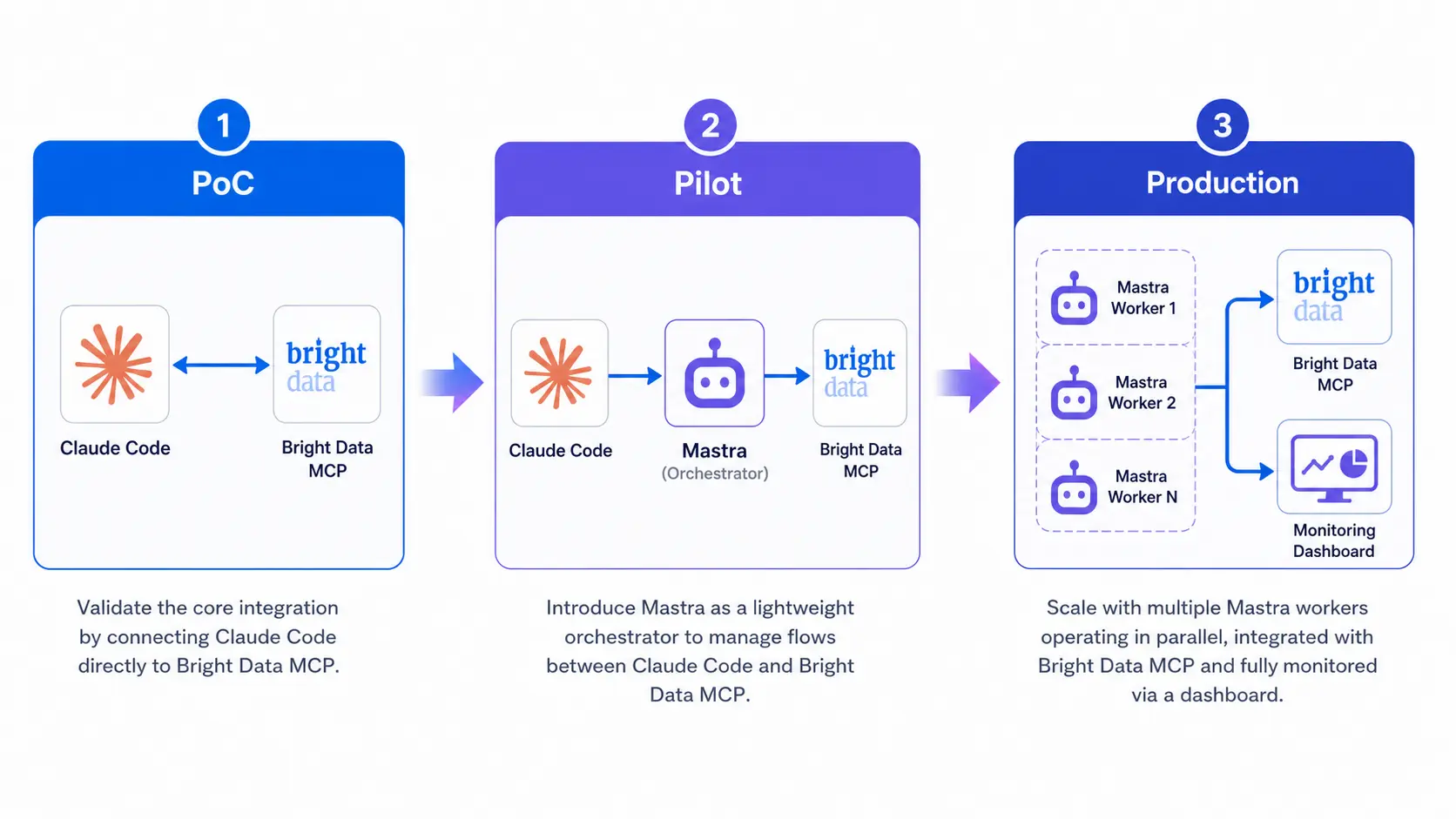
3.2 Our PoC Experience
We run Bright Data in production at Smile Comfort, and our own product Tra-bell uses Bright Data Residential and Web Unlocker behind the scenes. MCP shines for proof-of-concept and ad-hoc research — our analysts now drive SERP collection and article scraping in natural language, which has shrunk one-off research turnarounds from days to hours. For scheduled serverless workflows we still prefer the direct API or the architecture in AWS Lambda x Bright Data: Serverless Scraping Pipeline 2026, which scales more predictably than a chat-driven agent and gives the cost team a clear unit economic story. In practice we recommend starting with MCP for exploration, then graduating mature jobs to scheduled pipelines once query patterns stabilize.
4. Production Architecture With Mastra
Past PoC, calling Bright Data MCP straight from Claude Code lacks observability, cost guardrails, and reproducibility. A Mastra middleware layer lets you keep agent logic in TypeScript and route Bright Data tools through a controlled interface.
4.1 Recommended Architecture
- Front end: Claude Code, Claude Desktop, internal Slack bot
- Middleware: Mastra agents and workflows exposed as an MCP server
- Tool layer: Bright Data MCP, internal APIs, Postgres MCP, Slack MCP, and so on
- Data layer: BigQuery / Snowflake / R2
From the Claude Code side everything looks like a single server, while Mastra fans out to multiple Bright Data products and internal APIs. A community user ran a public demo where this pattern manages a restaurant business via chat2; the same idea maps cleanly to e-commerce ops, market research, support automation, or sales intelligence. The orchestrator agent inside Mastra can decide whether a question needs the Bright Data Web Unlocker, the SERP API, an internal Postgres query, or a combination, and stitch the answer back into a single response for the user.
4.2 Observability and Cost Guardrails
Agent-driven tool calls add up quickly. Wire these in from the start:
- Log tool invocations, byte counts, and target domains via Mastra middleware, so an audit trail exists per agent run
- Pipe the Bright Data Usage API into BigQuery, Snowflake, or your warehouse of choice on a daily schedule and join it with agent metadata
- Trigger Slack alerts when daily or weekly consumption exceeds a configurable threshold, with separate caps per zone
- Score agent outputs with LLM-as-a-judge or rule-based linters to cut redundant calls; agents often re-fetch the same URL within a session if not guarded
- Cache idempotent scrape results in Redis or R2 for the typical TTL of the source data — many e-commerce pages stay stable for hours
For deeper cost techniques across plan tiers and bandwidth optimization, see our Bright Data Cost Optimization 2026 guide.
5. Compliance Still Lives With You
MCP does not change the legal layer. Agents act autonomously, so guardrails must live on the human side.
"Bright Data MCP makes agents incredibly capable on the open web — but you still own the responsibility of what you scrape."
Key practical checks:
- Review the target site's terms of service and robots.txt; restrict allowed domains in the agent's system prompt and reinforce them with a Bright Data zone-level allowlist
- Avoid sites that can return personal or sensitive data, even through Web Unlocker; if you must touch them, route the result through a redaction step before it lands in your data warehouse
- Comply with GDPR, APPI, CCPA, or other applicable regulations (see our Bright Data and GDPR / APPI Compliance 2026 for a deeper dive)
- Retain agent execution logs, including the prompt, tool calls, and outputs, for 90+ days so you can audit every query if a regulator or partner asks
- Set up a simple incident playbook for "agent scraped something it shouldn't have" so the response is faster than the news cycle
We operate Tra-bell, a hotel price tracker built on Bright Data, and we routinely help teams design zones, model costs, and review compliance before MCP-driven scraping goes live. That hands-on experience extends to mapping query patterns onto the right Bright Data product (Residential, Web Unlocker, or SERP API) so the agent stays both cost-efficient and within legal limits.
6. Wrap-Up
The Bright Data MCP server is the practical way to hand AI agents the open web. PoC starts in minutes by wiring MCP into Claude Code; production needs a Mastra-style middleware that adds observability, cost control, and reproducibility. Pair that with Bright Data's proxy depth and bot-bypass quality, and MCP becomes a strong default for AI-driven scraping in 2026. Start small, prove value on a single workflow, then graduate the proven jobs into a managed Mastra app — and revisit the architecture every quarter as both the MCP spec and Bright Data product lineup keep evolving.
Information current as of 2026-05-21. Please check the official sites for the latest updates.
This article contains affiliate links.
Footnotes
-
Mastra official X account, "Bright Data integration in @mastra/core" (2026-05): https://x.com/mastra/status/2055015396093354375 ↩
-
rfscheidt's Mastra → MCP → Claude demo post (2026-05): https://x.com/rfscheidt/status/2056030193672708434 ↩
Frequently asked questions
Related articles

Bright Data Web Unlocker Practical Guide 2026: CAPTCHA Bypass and Cost Design

AWS Lambda x Bright Data: Serverless Scraping Pipeline 2026


