
Bright Data × Playwright 統合ガイド 2026 - プロキシ設定からスクレイピング実装まで
Playwright で Bright Data の Residential プロキシと Scraping Browser を組み合わせる実装パターンを、Node.js / Python のコードとコスト設計込みで解説します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
Playwright と Bright Data を組み合わせると、Cloudflare や DataDome に守られたサイトでも安定して動くスクレイピング基盤が作れます。本記事では、Residential プロキシ経由の基本設定から、より検知耐性の高い Scraping Browser の CDP 接続パターンまで、Node.js / Python の動くコード付きで解説します。コスト最適化と運用上の落とし穴も合わせて押さえます。
Playwright × Bright Data を選ぶ判断軸
Playwright は Microsoft が開発するブラウザ自動化フレームワークで、Chromium / Firefox / WebKit を統一 API で操作できます。一方、Bright Data は 1.5 億 IP 規模の Residential プロキシを中心に、Scraping Browser や Web Unlocker といったマネージドサービスをラインアップしています。両者を組み合わせる動機は、シンプルに「ブラウザ自動化が必要 + IP の出所を制御したい」という二つの要求が同時に来るケースです。
こんなときに Bright Data + Playwright を選ぶ
- 地理依存のコンテンツ (地域別の商品価格、地域限定キャンペーン) を取りたい
- ログイン後にしか出ない情報を取得し、セッション中は同じ IP を維持したい
- JavaScript レンダリングが必須で
fetch/httpxだけでは不足する - ボット検知 (Cloudflare、DataDome、PerimeterX) を回避しながら大規模に並列実行したい
逆に、HTML が静的で robots.txt が許可する範囲のスクレイピングなら、Playwright を持ち出すのは過剰投資です。Bright Data Web Unlocker や SERP API だけで足りるケースも多く、まずは軽量な構成から始めるのが定石です。プロキシラインアップの比較はResidential と ISP プロキシの使い分け実践ガイド 2026で整理しているので、用途別の選定はそちらが詳しいです。
推奨スタック (2026 年版)
| レイヤ | 推奨技術 | 補足 |
|---|---|---|
| ランタイム | Node.js 20 LTS / Python 3.12 | Playwright は両言語をサポート |
| ブラウザ | Playwright + Chromium | --no-sandbox は Linux コンテナで必要 |
| プロキシ | Bright Data Residential or Scraping Browser | 検知耐性で選ぶ |
| 並列実行 | playwright cluster / asyncio.gather | 同時 5〜10 で開始 |
| キュー | SQS / Redis Queue | 失敗時のリトライを永続化 |
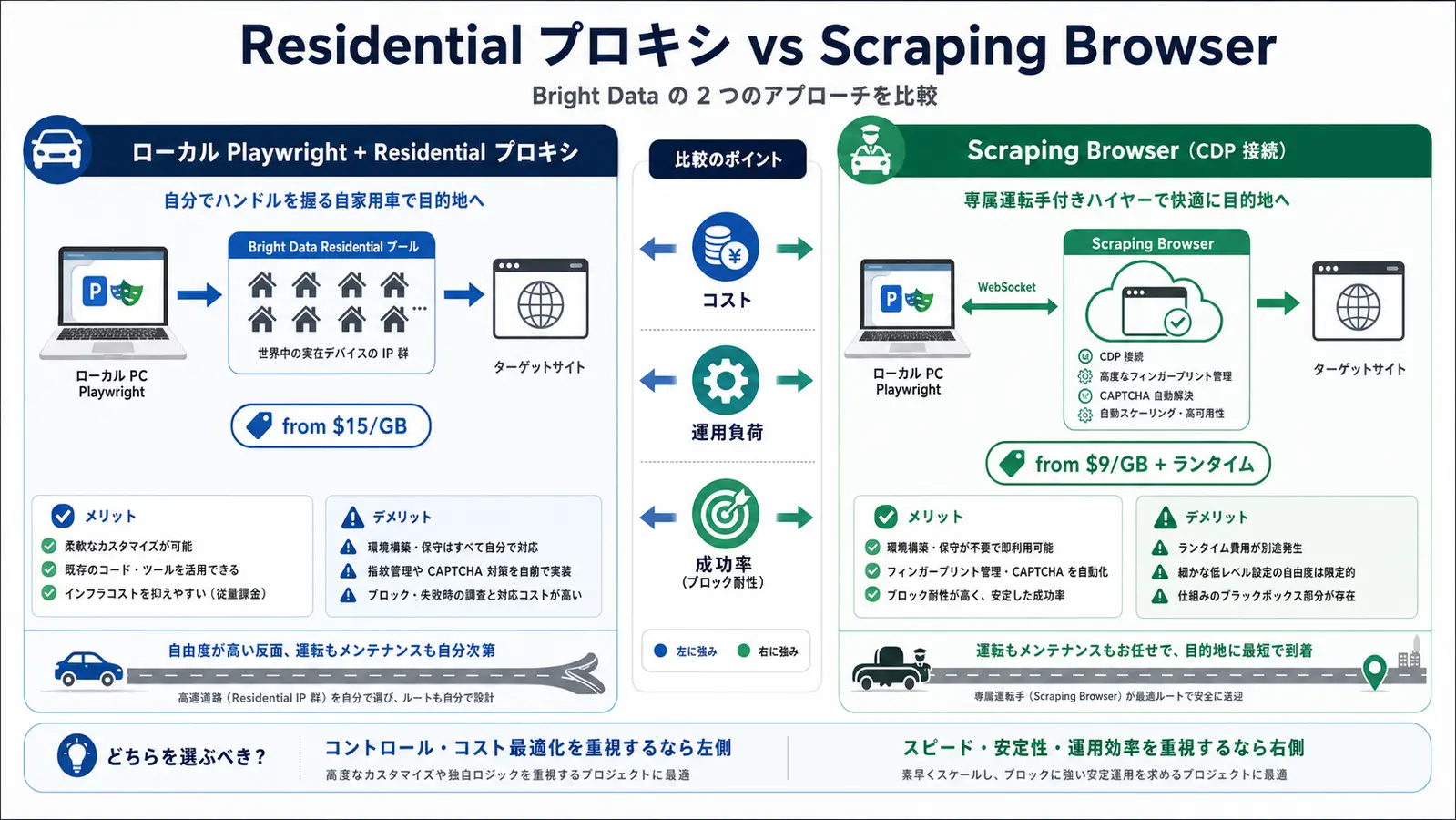
Residential プロキシ + Playwright の実装パターン
最も基本となるのが、Playwright の proxy オプションに Bright Data の Residential プロキシを指定する構成です。コードからは普通の HTTP プロキシに見えますが、Bright Data 側で IP ローテーション、地理ターゲティング、セッション管理を制御できます。
Node.js 実装 (Residential + Sticky Session)
const { chromium } = require('playwright');
const CUSTOMER_ID = process.env.BRD_CUSTOMER_ID;
const ZONE_NAME = process.env.BRD_ZONE; // 例: residential_zone_1
const ZONE_PASSWORD = process.env.BRD_PASSWORD;
async function scrapeWithStickySession(url, sessionId) {
// session-<id> を維持している間は同じ IP がアサインされる
const username = `brd-customer-${CUSTOMER_ID}-zone-${ZONE_NAME}-country-jp-session-${sessionId}`;
const browser = await chromium.launch({
headless: true,
proxy: {
server: 'http://brd.superproxy.io:22225',
username,
password: ZONE_PASSWORD,
},
});
const context = await browser.newContext({
userAgent:
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 ' +
'(KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36',
viewport: { width: 1440, height: 900 },
locale: 'ja-JP',
timezoneId: 'Asia/Tokyo',
});
// 画像・フォント・トラッカーをブロックして帯域を節約
await context.route('**/*.{png,jpg,jpeg,webp,gif,woff,woff2}', (route) => route.abort());
const page = await context.newPage();
try {
await page.goto(url, { waitUntil: 'domcontentloaded', timeout: 45_000 });
return await page.content();
} finally {
await browser.close();
}
}
scrapeWithStickySession('https://example.com/products/123', 'cart-flow-001')
.then((html) => console.log(html.length))
.catch((err) => console.error(err));
ポイントは次の 3 点です。
country-jpやcity-tokyoを ユーザー名に挿入すると地域固定 IP が取れるsession-<id>は同じ値を投げ続ける限り Bright Data 側で IP を保持する (最大数十分)- 画像・フォントをルートでブロックすると、Residential プロキシの GB 単価を 60〜80% 削減できる
Python 実装 (Residential + IP ローテーション)
import asyncio
import os
import uuid
from playwright.async_api import async_playwright
CUSTOMER_ID = os.environ["BRD_CUSTOMER_ID"]
ZONE_NAME = os.environ["BRD_ZONE"]
ZONE_PASSWORD = os.environ["BRD_PASSWORD"]
async def fetch_with_rotation(urls: list[str]) -> list[str]:
async with async_playwright() as p:
results: list[str] = []
for url in urls:
# URL ごとに新しい session ID を発行し、IP を切り替える
session_id = uuid.uuid4().hex[:12]
username = (
f"brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}"
f"-country-jp-session-{session_id}"
)
browser = await p.chromium.launch(
headless=True,
proxy={
"server": "http://brd.superproxy.io:22225",
"username": username,
"password": ZONE_PASSWORD,
},
)
context = await browser.new_context(
locale="ja-JP",
timezone_id="Asia/Tokyo",
viewport={"width": 1440, "height": 900},
)
page = await context.new_page()
try:
await page.goto(url, wait_until="domcontentloaded", timeout=45_000)
results.append(await page.content())
finally:
await browser.close()
return results
if __name__ == "__main__":
asyncio.run(fetch_with_rotation([
"https://example.com/products/100",
"https://example.com/products/200",
]))
リクエスト単位で IP を切り替えるパターンです。ログイン不要のページネーション、価格比較サイトの巡回、SEO ランキングチェックなど、各リクエストが独立しているユースケースに向きます。
「Playwright と Bright Data の Residential プロキシを組み合わせると、シンプルな fetch では落ちるサイトでも安定して取れる」(Daniel Miessler 氏は X で、Personal AI Infrastructure リポジトリの段階的スクレイピング設計をシェアしています。原文要約)
Scraping Browser (CDP 接続) で検知耐性を底上げ
Residential プロキシは強力ですが、Cloudflare Turnstile や DataDome の高難度バージョンが導入されているサイトでは、Playwright 側のフィンガープリント (webdriver フラグ、Chrome のヘッドレスシグナル、自動化らしい挙動) が原因でブロックされることがあります。Bright Data Scraping Browser は、Bright Data のクラウド上で動く実際の Chrome に CDP (Chrome DevTools Protocol) 経由で接続する仕組みで、フィンガープリント、CAPTCHA 自動突破、ブラウザのレジリエンス処理を Bright Data 側に任せられます。
Node.js 実装 (Scraping Browser CDP 接続)
const { chromium } = require('playwright');
const USERNAME = process.env.BRD_SB_USERNAME; // Scraping Browser 用ユーザー名
const PASSWORD = process.env.BRD_SB_PASSWORD;
async function scrapeWithBrowser(targetUrl) {
// セッション ID を渡すと、同一セッション中はブラウザ状態が維持される
const sessionId = `session-${Date.now()}`;
const params = new URLSearchParams({
'session-id': sessionId,
country: 'jp',
// 'unblock': 'true', // 高難度サイト向け (追加課金)
});
const wsEndpoint =
`wss://${USERNAME}:${PASSWORD}@brd.superproxy.io:9222?${params.toString()}`;
const browser = await chromium.connect(wsEndpoint);
try {
const page = await browser.newPage();
await page.setViewportSize({ width: 1920, height: 1080 });
await page.goto(targetUrl, { waitUntil: 'networkidle', timeout: 60_000 });
const data = await page.evaluate(() => ({
title: document.title,
itemCount: document.querySelectorAll('.product-card').length,
}));
return data;
} finally {
await browser.close();
}
}
scrapeWithBrowser('https://example.com/listing').then(console.log);
chromium.connect() でリモートブラウザに接続するため、ローカルでヘッドレス Chrome を立てる必要がありません。CAPTCHA は Bright Data 側で解決済みのページが返ってくるため、本来 Playwright で書く必要があった "CAPTCHA 検出 → 待機 → 再試行" の分岐をコードから消せます。
Residential vs Scraping Browser の使い分け
| 観点 | Residential プロキシ + ローカル Playwright | Scraping Browser (CDP 接続) |
|---|---|---|
| 料金 | $15/GB から | $9/GB から (ブラウザ稼働込み) |
| ブラウザ運用 | 自分でヘッドレス Chrome を起動 | Bright Data 側で運用 |
| フィンガープリント | 自分で対策 (Patchright / Stealth) | Bright Data 側で自動化 |
| CAPTCHA | 自分でハンドリング | Bright Data 側で自動解決 |
| 適したスケール | 中規模 (月 100GB 程度まで) | 大規模 / 高難度 |
実運用では、Residential プロキシで取れるサイトはそのまま Residential、CAPTCHA に頻繁にぶつかるサイトだけ Scraping Browser に切り替える、というハイブリッド構成にコストが収まりやすいです。Web Unlocker (Proxy API) との使い分けはBright Data Web Unlocker 実践活用ガイド 2026で詳しく整理しています。
「Kubernetes + Playwright + Bright Data Browser API はスケーラブルなパイプラインの定番。fingerprint をクラウド側で管理してくれる安心感が大きい」(Aleksei 氏 / 原文要約)
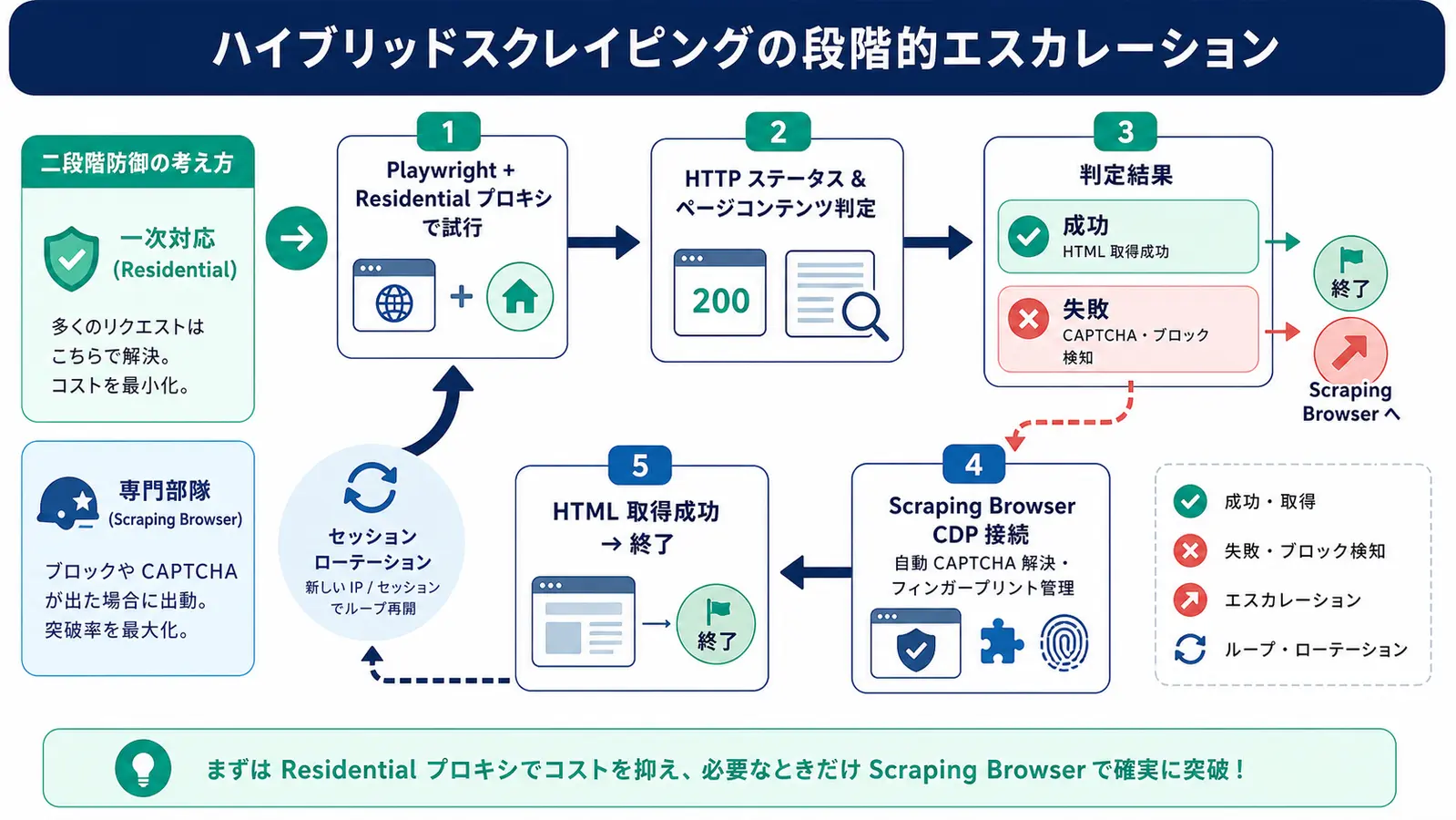
運用で詰まりやすい 5 つの落とし穴
ここからは本番運用で実際に遭遇する典型的なトラブルです。先に知っておくと、PoC から本番投入までの時間が短くなります。
1. 407 Proxy Authentication Required
ユーザー名のフォーマットミスが原因の 9 割です。brd-customer-<id>-zone-<zone> が正しい構造で、<id> と <zone> の間にハイフンが必要、<zone> 名は Bright Data ダッシュボードの Zone 一覧と完全一致する必要があります。lum-customer-... 形式の旧フォーマットも有効ですが、新規契約では brd- 接頭辞を使う方が将来的に安全です。
2. 帯域 (GB) が予想の 3〜5 倍
Playwright はデフォルトで画像・CSS・フォント・トラッカー JS まで取得します。context.route() で image, font, media リソースをブロックすると、転送量を 60〜80% 削減できます。本記事 H2-2 の Node.js 例にあるブロックパターンは、ほぼすべての汎用スクレイピングに転用できます。
3. セッションが途中で切れる
Bright Data のスティッキーセッションは「ユーザー名に同じ session-<id> を送り続ける限り」維持されます。ただし、最大セッション時間は Zone 設定で決まる (デフォルト 1〜10 分) ため、長時間のフローでは IP が切り替わる前提で再ログインのリトライ処理を組み込んでおきます。
4. Playwright のフィンガープリント露呈
navigator.webdriver = true や、Chrome ヘッドレス特有の permissions.query 戻り値が原因で、Cloudflare に検出されるケースがあります。Patchright / Camoufox といった派生実装を使うか、Scraping Browser に切り替えるのが現実的な解決策です。自前で add_init_script を積み上げるアプローチは保守コストが高くつきます。
5. リトライ戦略の不在
スクレイピングは失敗が前提です。失敗を Sentry / CloudWatch に流すだけでは復旧できないため、tenacity (Python) / p-retry (Node.js) などで指数バックオフ + ジッターを入れ、3〜5 回まで自動再試行する仕組みをアプリ層に持たせます。再試行のたびに session-<id> をローテートすると、ブロックされた IP を避けられます。
スクレイピング基盤の運用を一段上に引き上げる
Bright Data + Playwright の構成は強力ですが、本番運用では「単にコードが動く」だけでは足りません。並列実行のスロットリング、失敗ログの永続化、料金監視、データの正規化と Snowflake / BigQuery への投入まで含めて、スクレイピング基盤として完成させる必要があります。コストコントロールの実践テクニックはBright Data のコスト最適化テクニック 2026で詳しく扱っています。
弊社では、Bright Data の Residential プロキシと Web Unlocker を使ったホテル価格追跡サービス Tra-bell を自社で運用しています。Playwright 並列実行・セッション管理・失敗ハンドリング・Snowflake へのデータ投入まで含めた基盤を、PoC から本番運用への移行段階で伴走するノウハウがあります。スクレイピング基盤の設計レビューや、既存スクレイパーの Bright Data 化 (Web Unlocker / Scraping Browser 移行) もご相談可能です。
「AI エージェントが Web を操作するワークロードでは、Residential IP + 本物のブラウザフィンガープリントの組み合わせがブロックを大幅に減らす」(kevntz 氏 / 原文要約)
まとめ
Bright Data × Playwright は、地理ターゲティング・セッション管理・ボット検知回避を一気通貫で扱える強力な組み合わせです。実装パターンは大きく 2 つで、Residential プロキシ経由の素直な構成と、Scraping Browser に CDP で接続するクラウド型の構成に分かれます。PoC は Residential から始め、CAPTCHA が頻発するサイトだけ Scraping Browser に切り替えるハイブリッド設計が、コストと検知耐性のバランスを取りやすい現実解です。本記事のコードはそのまま改変して使えるので、ぜひ手元で動かしてみてください。
※情報は 2026-05-22 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
よくある質問
関連記事

Bright Data Scraping Browser 実践活用ガイド 2026 - Puppeteer/Playwright 統合とコスト設計

Bright Data Web Unlocker 実践活用ガイド 2026 - CAPTCHA突破とコスト設計
