
Bright Data Scraping Browser 実践活用ガイド 2026 - Puppeteer/Playwright 統合とコスト設計
Bright Data Scraping Browser を Puppeteer / Playwright と接続し、Cloudflare や CAPTCHA を回避する手順と料金の落とし穴を実運用目線で解説します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
Bright Data Scraping Browser は Chromium 互換のヘッドレスブラウザ + 住宅プロキシ + Bot 検知回避が一体になった SaaS です。Puppeteer / Playwright のスクリプトを 1 行書き換えるだけで、Cloudflare や DataDome を含む防御層の突破を Bright Data 側に委譲できます。本記事では実運用視点で、接続コードの書き換え方、コスト最適化、よくある落とし穴までを順に整理します。
Scraping Browser とは何か
Scraping Browser は Bright Data が運用する Chromium ベースのリモートブラウザで、WebSocket (CDP) 越しに Puppeteer / Playwright / Selenium から操作できます。自前で Headless Chromium と Residential プロキシを束ねる代わりに、フィンガープリント分散・CAPTCHA 自動解決・セッション維持までを Bright Data 側に任せられるのが要点です。
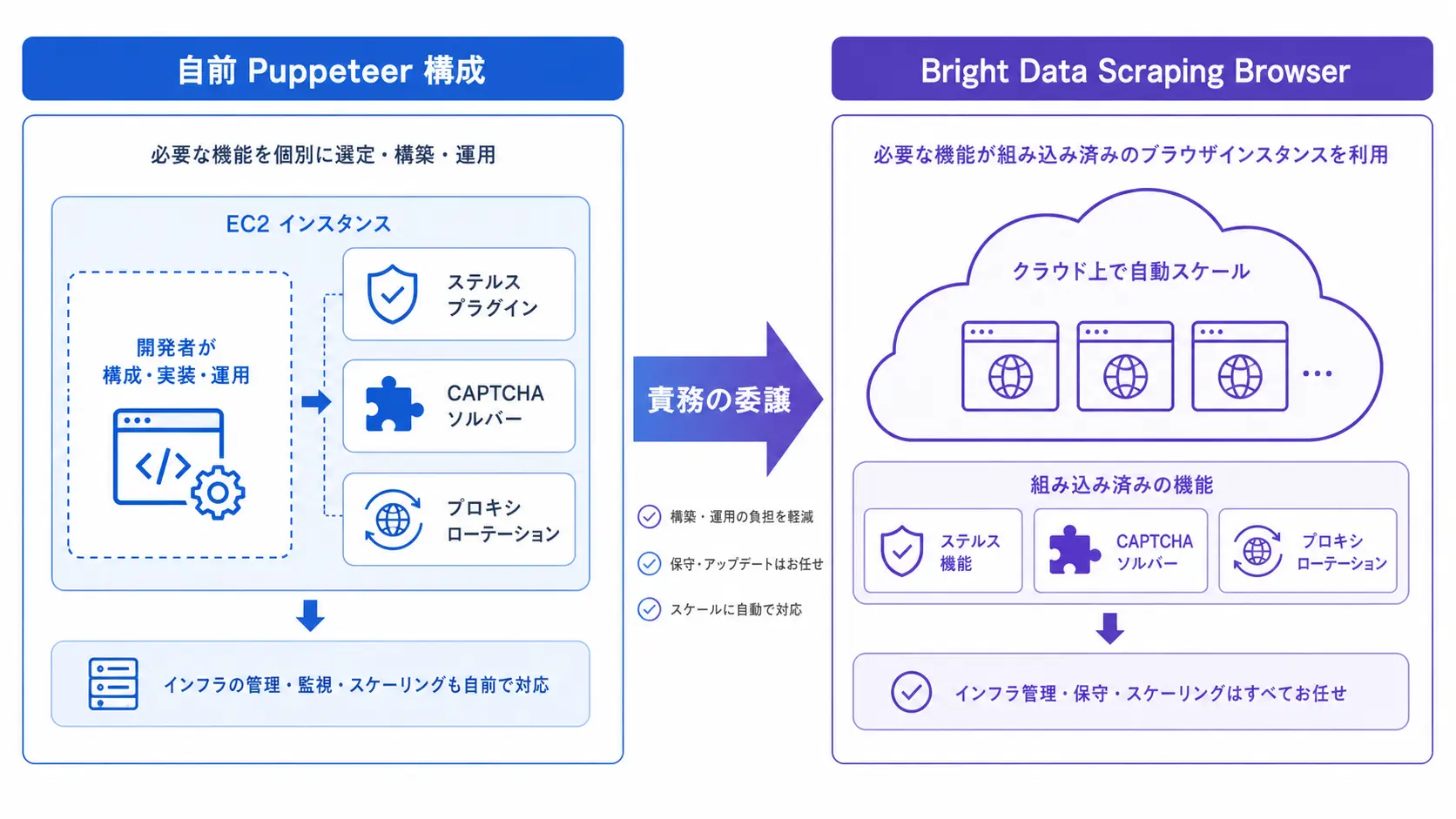
自前 Puppeteer との違い
| 比較軸 | 自前 Puppeteer + Proxy | Scraping Browser |
|---|---|---|
| ブラウザの実行場所 | 自社サーバー (EC2 / Lambda) | Bright Data クラウド |
| Stealth プラグイン | 自前で導入・追従 | 内蔵 (継続アップデート) |
| CAPTCHA 突破 | 別途 2Captcha 等を統合 | 自動 (追加課金あり) |
| IP ローテーション | プロキシ側で実装 | 同一 WebSocket で透過処理 |
| 価格モデル | サーバー + プロキシ帯域 | $9/GB の従量制 (2026 年 5 月時点) |
自前 Puppeteer は表面的なコストが安く見えますが、保守工数と検知率改善のアップデート対応 を含めると Scraping Browser のほうが TCO で逆転するケースが多い、というのが弊社の経験則です。
どんな対象で効果が出るか
Scraping Browser の費用対効果が出やすいのは、JavaScript レンダリングが必須かつ Bot 検知が厳しい SPA — たとえば EC モール、SNS、求人サイトの動的ページです。逆に静的 HTML を返す API ライクなサイトでは、bright-data-web-unlocker-guide で扱う Web Unlocker (HTTP API) のほうが安く済みます。両者の使い分けは Bright Data Web Unlocker 実践活用ガイド で整理しています。
Puppeteer / Playwright での接続コード
ここでは最短経路の接続コードを示します。Bright Data ダッシュボードで Scraping Browser ゾーンを作成すると、brd-customer-<id>-zone-<name>:<password>@brd.superproxy.io:9222 形式の WebSocket エンドポイントが発行されます。
Puppeteer 接続例
import puppeteer from "puppeteer-core";
const SBR_WS = `wss://brd-customer-XXX-zone-scraping_browser1:PASSWORD@brd.superproxy.io:9222`;
async function main() {
const browser = await puppeteer.connect({ browserWSEndpoint: SBR_WS });
try {
const page = await browser.newPage();
await page.goto("https://target-site.example.com", { timeout: 2 * 60_000 });
const html = await page.content();
console.log(html.length);
} finally {
await browser.close();
}
}
main();
Playwright 接続例
import { chromium } from "playwright";
const SBR_WS = `wss://brd-customer-XXX-zone-scraping_browser1:PASSWORD@brd.superproxy.io:9222`;
const browser = await chromium.connectOverCDP(SBR_WS);
const context = browser.contexts()[0];
const page = await context.newPage();
await page.goto("https://target-site.example.com", { timeout: 120_000 });
console.log(await page.title());
await browser.close();
よく使うクエリパラメータ
WebSocket URL のクエリパラメータで挙動を細かく制御できます。
country=jp… 日本 IP に限定 (city=tokyo まで指定可能)session-id=<任意>… 同一 IP / Cookie を最大 30 分維持lock-session=true… 並列実行で別セッションが割り込まないよう排他化
弊社で運用する Tra-bell (Bright Data 上で動くホテル価格追跡サービス) でも、地域比較のため country パラメータで日本/米国/欧州を切り替える運用を行っています。
「Bright Data Scraping Browser を Puppeteer に接続するだけで、自前で組んでいた Stealth 設定がほぼ不要になった」という開発者の声。Stealth プラグインの保守から解放されることが Scraping Browser を選ぶ実利として強調されています。
Scraping Browser を Puppeteer / Playwright と接続する基本パターンは、開発者コミュニティでもこの形でテンプレ化されつつあります。
実装ステップとよくある詰まりどころ
PoC から本番運用に乗せるまでの典型的な順番をまとめます。
- ゾーン作成: ダッシュボードで Scraping Browser ゾーンを作り、KYC を通す
- 疎通確認: 上記の接続コードで
https://geo.brdtest.com/welcome.txtなどのテスト URL を叩く - 対象サイトの分析: ネットワークタブで XHR / GraphQL を観察し、ブラウザ操作が本当に必要か再確認
- 再現可能なフローを Playwright Codegen で記録: 手動で 1 回流したフローをスクリプト化
- タイムアウト・リトライ設計: page.goto は 60 - 120 秒、ネットワーク状態は
waitUntil: "domcontentloaded"を基準に - エラー時のスクリーンショット保存: 失敗時に
page.screenshot()を S3 / R2 に投げて事後解析 - トラフィック計測: 数日運用したあと GB ベースの実コストを集計し、Web Unlocker / Datacenter との切り替えを検討
CAPTCHA に当たったときの分岐は Bright Data で CAPTCHA に遭遇したときの対処レシピ も合わせて参照してください。Scraping Browser でも完全に消えるわけではなく、reCAPTCHA v3 のスコアが低い場合は明示的なリトライ設計が必要です。
法務・運用上の注意点
Scraping Browser を導入する前に、対象サイトの利用規約と robots.txt を確認するのが大前提です。技術的に取得できることと、規約上取得してよいことは別問題で、以下のチェックリストを PoC 開始前に必ず通します。
- robots.txt の Disallow を尊重し、Crawl-Delay を超えない頻度で叩く
- 個人情報を含むページのスクレイピングは個人情報保護法 / GDPR / CCPA の対象
- ログイン後の領域は利用規約違反の可能性が高い (BtoB SaaS の管理画面など)
- Bright Data は KYC により IP 出所を担保しているが、これは 法令遵守の保証ではない
- スクレイピングに関する判例 (hiQ vs LinkedIn, Meta vs Bright Data 等) は継続的にウォッチ
GDPR / 個人情報保護法の細部は Bright Data と GDPR / 個人情報保護法 2026 を別途参照してください。
コスト設計の勘所
Scraping Browser は $9/GB 従量制 (2026 年 5 月時点) で、フルブラウザを動かすため Residential プロキシより 1 リクエストあたりの転送量が増えがちです。実コストを抑える 3 つの定石を示します。
1. 不要リソースをブロック
画像 / 動画 / フォント / 広告タグは読まないように request interception で落とします。EC 商品ページなら、これだけで転送量を 40 - 60% 削れることが多いです。
await page.route("**/*", (route) => {
const type = route.request().resourceType();
if (["image", "media", "font"].includes(type)) return route.abort();
return route.continue();
});
2. レンダリング深度の制御
networkidle まで待つと余計な XHR を全部踏むので、domcontentloaded + 必要な要素の waitForSelector に切り替えると 1 ページあたり 20 - 30% は短縮できます。
3. Web Unlocker / Datacenter との段階的切り替え
弊社で支援する案件では、対象サイト群を「JS レンダリング必須」「HTTP で返ってくる」「検知ゆるい」の 3 層に分け、Scraping Browser / Web Unlocker / Datacenter を使い分けています。3 層を併用するとプロキシ予算を 40 - 60% 圧縮できた事例もあります。料金の全体感は Bright Data のコスト最適化テクニック 2026 で整理しています。
「Scraping Browser は主力として使い、軽い対象は Web Unlocker に逃すと月額が大きく変わる」という運用報告。コストを抑える構成として現場で定着しつつあるパターンです。
開発者間でも、Scraping Browser を「主力」、Web Unlocker を「サブ」に置く構成が現実解として定着しつつあります。
弊社 (スマイルコンフォート) の運用事例
弊社では、Bright Data の Residential プロキシと Scraping Browser を組み合わせたホテル価格追跡サービス Tra-bell を自社運用しています。JS レンダリング必須の予約サイトと HTTP API ライクなサイトを混在させる構成で、転送量ベースのコストを月次でチューニングしてきた経験があります。同等のスクレイピング基盤を PoC 段階から構築したいケースには、Scraping Browser 単体の導入支援、AWS Lambda / ECS 連携、データ基盤 (BigQuery / Snowflake) への接続まで一括で伴走可能です。
ホテル業界に限らず、EC 価格モニタリング・求人比較・SEO 監視といった用途でも同じ構成が応用できます。Bright Data 上で動く実運用プロダクトの構造を知りたい方は、Tra-bell のサイトもあわせてのぞいてみてください。
まとめ
Bright Data Scraping Browser は、自前 Puppeteer + プロキシ + Stealth プラグインの組み合わせを 1 つの SaaS に置き換えるサービスです。接続コードを WebSocket エンドポイントに差し替えるだけで、Cloudflare や CAPTCHA を含む防御層への対応をベンダー側に委譲できます。JS レンダリング必須 + Bot 検知が厳しい SPA で費用対効果が高く、コストは画像/フォントのブロックと Web Unlocker との使い分けで 30 - 60% 削減可能です。PoC で 1 - 2 週間運用したうえで月次の実コストと検知率を確認し、本番設計に進むのが堅実な進め方になります。
※情報は 2026-05-21 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
よくある質問
関連記事


