
Bright Data Webhook と Data Delivery 設計 2026 - S3 / BigQuery 連携
Bright Data の Webhook と S3 / BigQuery / Snowflake へのネイティブ配送を、ペイロード形式・リトライ・コスト・運用責任の観点で整理。スクレイピング結果を業務基盤に流す設計の決定版。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
「Bright Data のスクレイピング結果を、毎日どうやって業務システムに取り込めばいいのか」 — この問いに正面から答えるのが Webhook と Data Delivery の設計です。リアルタイム通知が欲しい場面では Webhook、分析・データウェアハウス用途では S3 / BigQuery / Snowflake への直接配送が向きます。本記事は両者のペイロード形式・リトライ・コスト・運用責任を整理し、弊社が Bright Data 上で動かしてきた経験から、迷わず選べる判断フレームを示します。
1. なぜ「配送設計」がスクレイピング基盤の要になるのか
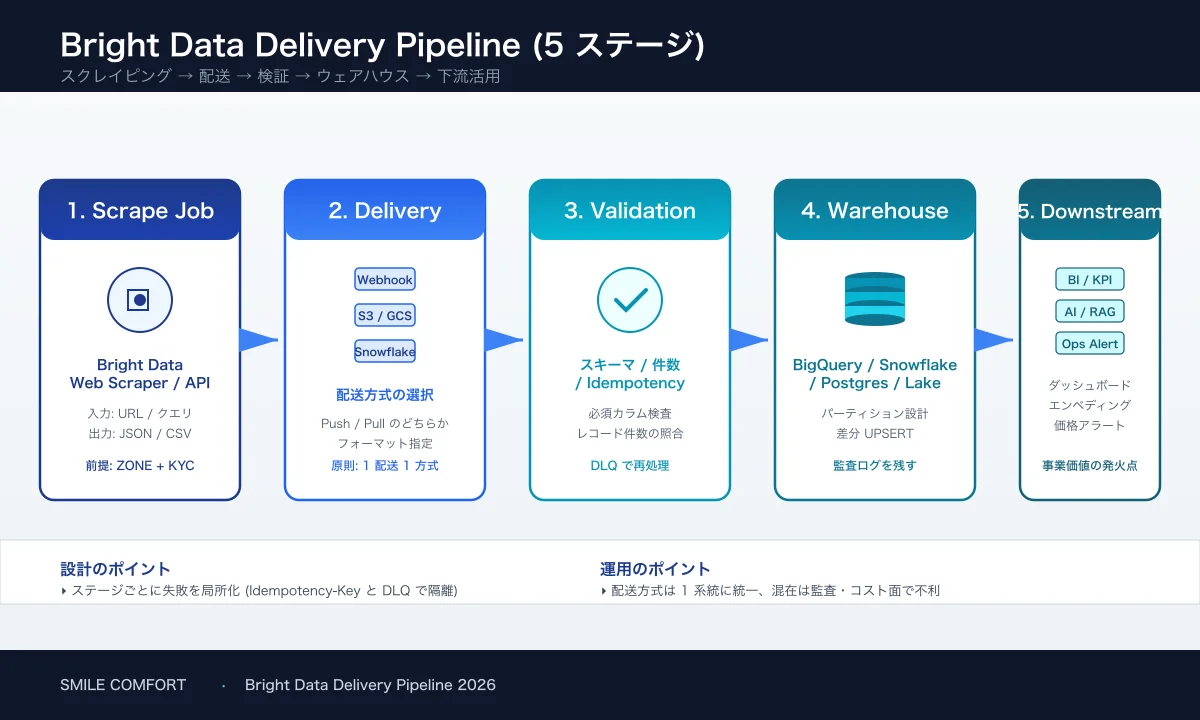
Bright Data の Web Scraper API や Dataset Marketplace が出力するデータは、そのままでは「ジョブ完了後にダッシュボード上にある JSON」に過ぎません。実運用では、これを業務システムや BI / DWH に取り込み続ける配送レイヤがボトルネックになります。
1.1 配送レイヤが詰まる典型パターン
弊社が他社事例も含めて見てきた中で、配送設計で詰まる典型は次の 3 つです。
- Pull 一辺倒: 毎時 ダッシュボードからファイルを cron で取りに行く運用にすると、ジョブ完了タイミングのズレでスキップ / 重複が起きる
- Webhook の暴発: ペイロードが大きいジョブで受信側が詰まり、500 を返した結果リトライ嵐に巻き込まれる
- スキーマ管理の放置: 配送先に届く JSON のキー名・型が変わったとき、ダウンストリームのテーブルが壊れて分析停止
Bright Data は Webhook と Native Delivery の両方を備えているため、上記をすべて構造で解けます。むしろ、どちらを選ぶかを最初に決めないまま「とりあえず JSON ダウンロード」で始めると、半年後に基盤を作り直すことになります。
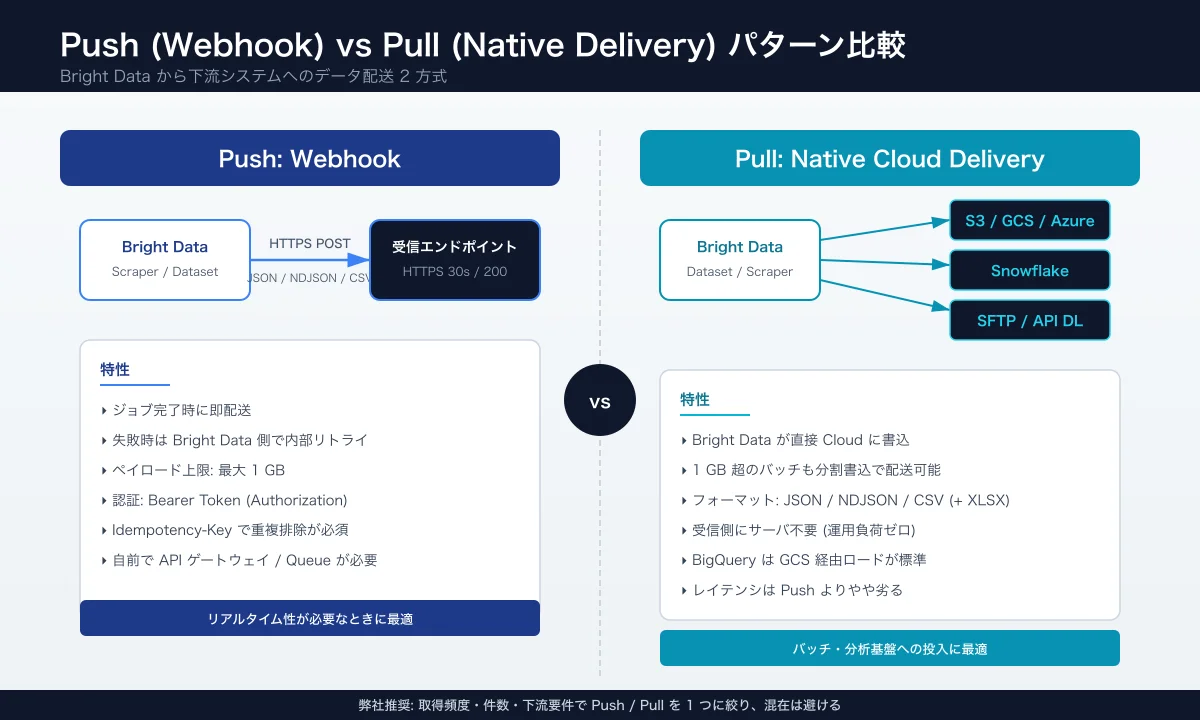
1.2 Push (Webhook) と Pull (Native Delivery) の比較
両者の差は「データを送る責任を誰が持つか」で線引きできます。
| 項目 | Webhook (Push) | Native Delivery (S3 / Snowflake / GCS) |
|---|---|---|
| データの流れ | Bright Data → 自社エンドポイント | Bright Data → クラウドストレージ / DWH |
| リアルタイム性 | ◎ (ジョブ完了 / 件数到達で即送出) | △ (バッチ単位、数分〜数時間) |
| 受信側の責任 | 高 (可用性 / 認証 / 冪等性) | 中 (権限と保存場所のみ) |
| ペイロード設計 | JSON / JSONL / CSV / NDJSON、最大 1 GB1 | JSON / CSV / NDJSON / Parquet |
| ユースケース | 価格アラート、即時通知、Agent 連携 | 分析 DWH 投入、RAG ベクトル化 |
| リトライ | あり (30 秒以内に 200 が返るまで)1 | あり (Bright Data 側で内部完結) |
スクレイピング基盤全体としてどんなコンポーネント分担になるかは AWS Lambda × Bright Data でサーバーレス スクレイピング基盤を構築する方法 2026 も併せて参照すると、配送レイヤの位置付けが見えやすくなります。
2. Webhook 連携の設計とリアルタイムユースケース
Webhook は Bright Data 側がジョブ完了タイミング (もしくは件数しきい値到達) で、指定した HTTPS エンドポイントに POST する仕組みです。「データが来てから即座にイベントを発火させたい」全シナリオ で第一候補になります。
2.1 Webhook のペイロードと認証
ペイロードは JSON (1 オブジェクト = 1 件) または JSONL (改行区切り) で届きます。Bright Data 側で次の制御が可能です。
- 形式: JSON / JSONL / CSV / NDJSON の選択 (Parquet は Marketplace のネイティブ配送のみ)
- 認証: Authorization ヘッダ経由の Bearer トークン (Webhook 設定時に
webhook_header_Authorization=Bearer+TOKENで指定) 1 - 送信タイミング: ジョブ完了時 / 件数しきい値到達時 (チャンク配送) 1
- 再試行: 受信側が 30 秒以内に 200 を返したら成功、それ以外は Bright Data 側で内部的にリトライ1
- ペイロード上限: 1 配送あたり最大 1 GB。これを超える、または安全に運用したい場合は送信ジョブ側で件数を絞ってチャンク分割するか、S3 配送に切り替える1
- メタデータ: ジョブ ID、Dataset ID、取得件数、取得時刻
実装上は 受信側で冪等キー (ジョブ ID + バッチ ID) を保持しておく ことが重要で、リトライ時の重複処理を防げます。弊社では DynamoDB か Redis を冪等チェックに使い、同じキーが来たら 200 を返して捨てる構成にしています。
2.2 受信エンドポイントの実装パターン
Webhook 受信側はサーバーレスが定番です。下記が実運用で使われる組み合わせです。
- AWS Lambda + API Gateway: 一般的。Lambda の同時実行数で負荷の上限を制御
- Cloud Run / Functions: GCP 系のときの第一候補。コールドスタートが比較的軽い
- Vercel Functions / Next.js API Routes: 軽量・即立ち上げ。ペイロード上限に注意
- EC2 / Cloud Run on VPC: VPC 内 DB に直結したい場合
弊社の運用感では、ペイロードが大きいジョブで Lambda タイムアウト (15 分) を超えるリスクがあるときは、API Gateway → Lambda → SQS にいったん退避 → ワーカー Lambda で処理という二段構成が安全です。
「Bright Data の Webhook / ポーリング実装は競合より煩雑に感じる開発者もいる。シンプルな API レスポンスで完結できるかは選定時にチェックすべき」(原文の要旨: Some developers find Bright Data's webhook/polling implementation messier than alternatives that return simpler instant API responses.)
実際、Webhook 経路を入れると「受信側を作る・運用する」工数が増えます。短期 PoC で済む程度のジョブなら、後述する Native Delivery で S3 に置く方が早いこともあります。「リアルタイム性が本当に要件か」を最初に問い直すと無駄な設計を減らせます。
2.3 Webhook が活きるユースケース
- 価格アラート: 競合の値下げ・在庫切れを 5 分以内に Slack / メール通知
- AI Agent 連携: スクレイピング結果を Agent の context に即流し込む (Bright Data MCP サーバーで AI Agent にスクレイピングを任せる実践ガイド 2026 のような MCP 連携と相性が良い)
- イベントドリブン処理: 新着レビュー検知 → センチメント分析 → ダッシュボード更新
逆に 「日次バッチで DWH に積めば十分」な分析用途では Webhook はオーバーキル です。次の Native Delivery に移ります。
3. S3 / BigQuery / Snowflake へのネイティブ配送
Bright Data の Data Delivery は、スクレイピング結果を直接クラウドストレージ / DWH に書き込んでくれる機能です。受信側で API を作らなくても済むので、運用負荷の総量が劇的に下がります。
3.1 対応先と認証情報
2026 年 5 月時点で公式の Marketplace data delivery / Datasets delivery options に掲載されているターゲットは下記の通りです23。
| ターゲット | 認証方式 | 主な用途 |
|---|---|---|
| Amazon S3 | IAM アクセスキー or AssumeRole | データレイク / バックアップ |
| Google Cloud Storage | サービスアカウント JSON | データレイク (GCP 系) |
| Google Cloud Pub/Sub | サービスアカウント JSON | リアルタイムストリーミング |
| Microsoft Azure (Blob) | SAS or Account Key | データレイク (Azure 系) |
| Snowflake | 専用ユーザー / Role / internal named stage3 | 分析 DWH |
| SFTP | パスワード or 公開鍵 | 既存ファイルサーバ取り込み |
| Webhook | (任意の Auth ヘッダ) | リアルタイム HTTPS POST |
| API ダウンロード | API キー | 小規模・ad-hoc 用途 |
| メール / ダウンロード | (不要) | 小規模・即見たい用途 |
BigQuery と Redshift は 2026 年 5 月時点で公式の直接配送先には載っていません2。Bright Data が BigQuery への直接配送を公式に提供していないため、弊社では Bright Data → GCS / S3 への配送 → BigQuery 外部テーブル / Dataflow / BigQuery Data Transfer 経由でロード する構成を推奨 しています4。記事内で「BigQuery で分析する」と書く場合も「直接配送」ではなく「GCS 経由ロード」を前提に設計しましょう。
設定はダッシュボードから Target を追加するだけで、Bright Data 側がスケジュール (オンデマンド / 完了時 / 日次 / 時間単位) に従って書き込んでくれます。
3.2 出力フォーマットとスキーマ
ファイル形式は JSON / NDJSON / CSV / XLSX / Parquet から選べます (Parquet と XLSX は Marketplace のネイティブ配送で利用) 2。Parquet は Snowflake / BigQuery (GCS 経由) へのロードが高速かつスキーマ自動推定が効くため、運用観点で第一候補です。XLSX は分析担当者が Excel / Google Sheets で素早く確認したいケースで便利です。
スキーマ周りで運用負荷が下がる工夫として、Bright Data 側でカラム選択・リネーム・型変換ができる UI が用意されています。 とはいえ、ダウンストリームでの破壊的変更を防ぐため、Bright Data 側のフィールド変更は禁止し、変換はアプリ層で吸収する ポリシーを取ると安全です。
3.3 Native Delivery の典型ユースケース
- BI ダッシュボード: BigQuery / Snowflake → Looker Studio / Tableau / Metabase
- RAG / LLM 学習: S3 / GCS に Parquet で保管 → Embedding バッチ (Bright Data で LLM RAG 用データソースを構築するガイド 2026 でも触れています)
- 商品マスタ整備: Dataset Marketplace の Amazon / 楽天 / Yahoo! 系データを S3 → 商品マスタ統合 (Bright Data Dataset Marketplace 完全活用ガイド 2026 と組み合わせ)
- dbt パイプライン: DWH 取り込み → dbt で変換 → BI / ML 特徴量
「Bright Data は『データ配送までハンズオフ』を訴求点にしており、スクレイピング + 配送が一体化している点が選定理由になっている」(原文の要旨: Bright Data positions "hands-off data delivery" as a key selling point, alongside their scraping infrastructure.)
「データ配送までハンズオフ」が Bright Data の隠れた強みです。Apify や ScraperAPI が「スクレイピングの仕組み」を売っているのに対し、Bright Data は「データが指定した場所に届く」ことまで責任を持つ設計になっています。
4. ペイロード設計と失敗時の冪等性
Webhook と Native Delivery どちらを採用しても、最終的にダウンストリームで「同じデータを 2 回処理しないこと」「届かなかったデータをいつでも再送できること」が運用品質を左右します。
4.1 冪等キーの設計原則
冪等キーは下記の組み合わせで構成すると失敗が少ないです。
dataset_id + batch_id + record_idのハッシュをユニーク制約に- DynamoDB / Redis / Postgres unique index で 24 時間〜30 日保持
- 重複検出時は 200 を返して捨てる (Webhook の再試行嵐を抑止)
- DWH 側は upsert (merge) で書き込み、insert を避ける
4.2 失敗時のリトライ設計
4.3 弊社の運用パターン
弊社が Bright Data の配送設計で実プロダクションに乗せている標準構成は次の通りです。
- Webhook で SQS にエンキュー (即時イベント、200 を即返す)
- 同時に S3 へ Native Delivery (バックアップ / 監査用)
- SQS ワーカー Lambda で冪等性チェック → DynamoDB / BigQuery に書き込み (BigQuery は GCS 経由ロードで投入)
- dbt で BigQuery テーブルを正規化 → BI / RAG / 分析へ
- 障害時は S3 のファイルをワーカーに再投入 (Webhook ペイロード喪失時の保険)
この構成にしておくと、リアルタイム性とバッチ整合性、再現性を同時に確保できます。Webhook 単独 / Native Delivery 単独ではどちらも運用上の痛みが残り、最終的に「両方を並走させる」設計に行き着きました。同様の基盤を構築したいケースは要件次第で伴走可能です。
5. まとめ
Bright Data の Webhook と Native Delivery は、スクレイピング基盤を業務システムに繋ぐ際の「最後の 1 マイル」を構造的に解くための機能です。Webhook はリアルタイム性、Native Delivery は分析・DWH 用途。実運用ではこれらを並走させて、冪等性と再送可能性を担保するのが正解です。ペイロード設計とスキーマ進化への耐性を最初に決めておけば、半年後に基盤を作り直す事態を避けられます。
考え方の核は Webhook を「シグナル (signal)」、Native Delivery を「正本 (source of truth)」として役割分担する ことです。この切り分けを最初に据えてしまえば、保存先の選定もリトライ方針も DWH 構成も、設計議論を繰り返すよりは粛々と適用していく機械的な作業に近づき、新規パイプラインの立ち上げが「数週間」から「数日」へと短縮できます。なお、同じ Bright Data + Webhook + Native Delivery の組み合わせは、弊社が運用するホテル価格追跡サービス Tra-bell でも採用しており、Bright Data 上で稼働中のプロダクションサービスとして並走運用の知見を蓄積しています。
※情報は 2026-05-24 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
Footnotes
-
Bright Data 公式 - Webhooks delivery (Web Scraper API): https://docs.brightdata.com/datasets/scrapers/google/data-delivery/webhooks ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Bright Data 公式 - Marketplace data delivery and export: https://docs.brightdata.com/datasets/marketplace/data-delivery-and-export ↩ ↩2 ↩3
-
Bright Data 公式 - Scrapers library delivery options (Snowflake internal named stage): https://docs.brightdata.com/datasets/scrapers/scrapers-library/delivery-options ↩ ↩2
-
Google Cloud 公式 - BigQuery 外部テーブル / BigQuery Data Transfer: https://cloud.google.com/bigquery/docs/external-data-cloud-storage ↩
よくある質問
関連記事

Bright Data Dataset Marketplace 完全活用ガイド 2026 - 既製データ購入で月額数万円のスクレイパー保守を捨てる

