
Bright Data vs Zyte 2026: Proxy Scale vs AI Auto-Extraction, Which to Choose
Bright Data vs Zyte in 2026: proxy scale, Web Unlocker, and SERP API versus Zyte's Scrapy Cloud and AI extraction, with use-case guidance to pick one.

This article contains affiliate links (advertising).
"Should we go with Bright Data or Zyte (formerly Scrapinghub)?" is a question we field again and again from teams building a scraping stack. This guide weighs both vendors fairly with the latest information as of writing time (May 2026). The short version: choose Bright Data when you need massive proxy scale, unblocking, and SERP at volume; choose Zyte when the Scrapy ecosystem and AI auto-extraction can cut your implementation and maintenance. We fold in lessons from running Bright Data in production to push past surface-level comparisons1.
Where Bright Data and Zyte Sit Today
Both are strong players in data collection, but they win different layers. Bright Data is known for the scale of its proxy infrastructure and unblocking; Zyte is known for scraping developer experience and AI extraction.
Bright Data's Position
Bright Data (formerly Luminati) was founded in 2014, is headquartered in Israel with a global presence, and has one of the industry's longest histories. Its calling card is a 400M+ residential IP pool - among the largest available - plus a broad lineup spanning Web Unlocker, Scraping Browser, SERP API, and a Dataset Marketplace. Enterprises pick it when they need scale plus acquisition certainty2.
Zyte's Position
Zyte grew out of the company behind Scrapy and has built a developer-friendly reputation since its Scrapinghub days. Anchored by Scrapy Cloud (managed Scrapy spider execution), Automatic Extraction (AI structured extraction), and the Zyte API (smart proxy plus rendering), its product design lands well with teams that want to minimize code and maintenance3.
Shared Strengths
- Ethical IP and data sourcing: both publish robots.txt adherence, opt-outs, and GDPR/CCPA/APPI handling
- JavaScript rendering: both handle SPAs and dynamic sites
- Enterprise posture: SLAs, custom plans, and demo support
- Usage-based pricing: pay-as-you-go plus volume discounts and free/low-cost trials
Framing them as "two data-collection vendors with different centers of gravity" makes the comparison much cleaner. For a proxy-pure-play matchup, see Bright Data vs Oxylabs 2026, which is useful for judging on raw proxy terms.
The Big Picture: Bright Data vs Zyte Side by Side
Before the feature details, here is the at-a-glance scorecard. The table reflects the state of play as of writing time, and all prices are approximate.
| Dimension | Bright Data | Zyte (formerly Scrapinghub) |
|---|---|---|
| Proxy network scale | 400M+ IPs, 195 countries, city/ASN/carrier targeting | Smart proxy inside Zyte API (less focus on selling a standalone pool) |
| Unblocking | Web Unlocker (auto-defeats Cloudflare/Akamai/DataDome) | Rotation and rendering integrated into Zyte API |
| AI auto-extraction | Web Scraper IDE + AI assist (flexible but more implementation) | Automatic Extraction leads (codeless structuring) |
| Scrapy integration | Python-capable but no Scrapy-specific platform | Scrapy Cloud is the home turf (deploy/schedule/monitor) |
| SERP API | Mature dedicated SERP API (Google/Bing, etc.) | No dedicated SERP API (build via general API) |
| Ready-made data | Buy via Dataset Marketplace | Limited pre-packaged dataset catalog |
| Billing unit | GB (proxy) / request (Unlocker, SERP) | Request/compute unit (API) / runtime (Scrapy Cloud) |
| Best fit | Data vendors, large-scale collection, AI agent stacks | Python/Scrapy teams, structured-data-first |
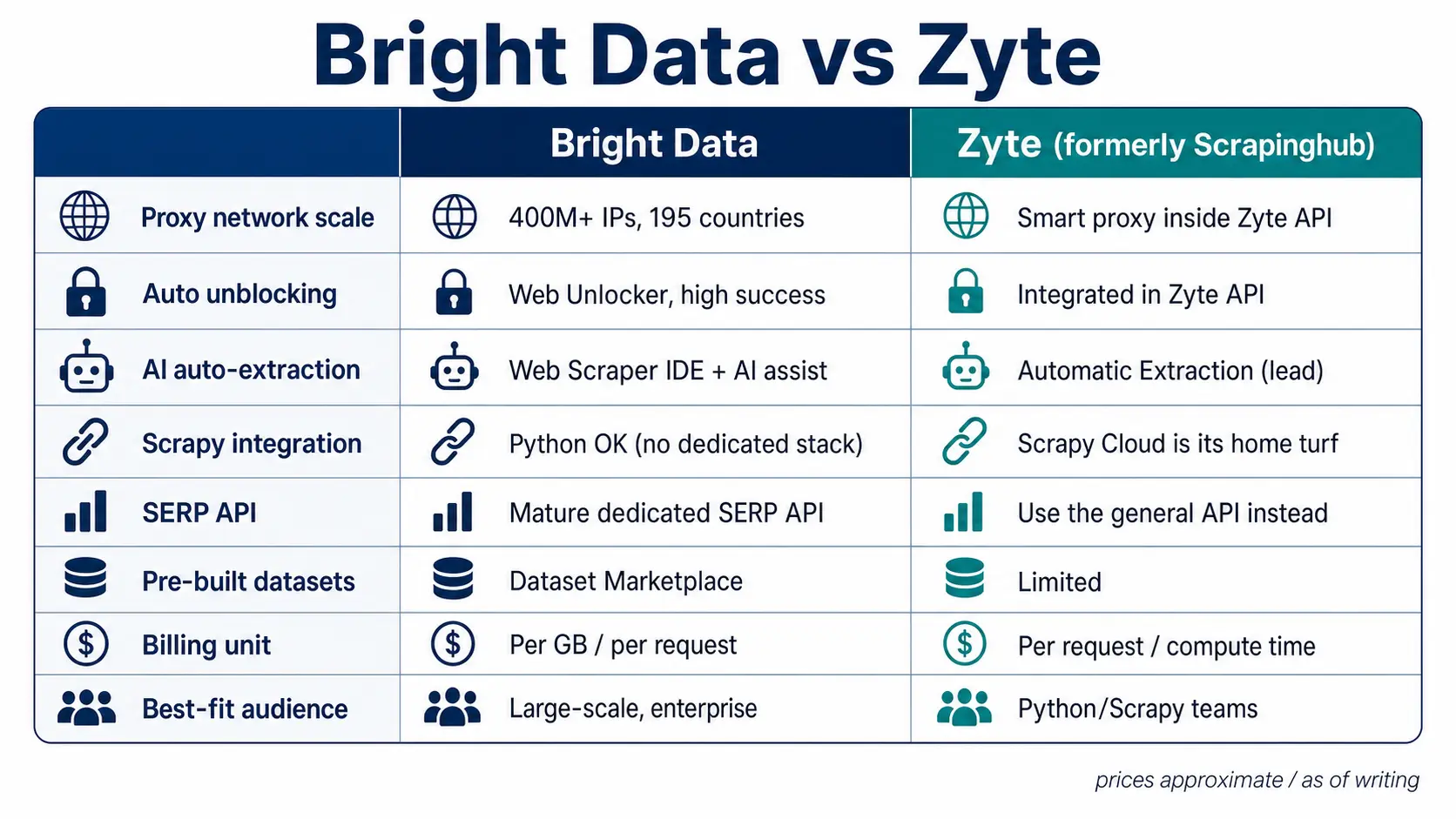
Put simply, Bright Data competes on breadth and reliability of acquisition infrastructure, while Zyte competes on finished data and hands-off Scrapy operations. For a product-by-product Bright Data pricing teardown, see Bright Data Pricing Cheat Sheet 2026.
Proxies, Unblocking, and SERP: Bright Data Leads
When the requirement is "acquire tough, well-defended sites without interruption, at scale," Bright Data pulls clearly ahead. This is not the territory Zyte primarily competes in.
Proxy Scale and Geo Coverage
Bright Data's residential pool sits at over 400 million IPs, with targeting down to country, city, ASN, and carrier. Zyte embeds a smart proxy inside the Zyte API, but it is modest about selling a giant standalone pool as raw proxies - it positions proxies as part of an integrated scraping solution. On the diversity of residential IP sourcing and the breadth of rotation design, Bright Data has the edge.
Automatic Unblocking via Web Unlocker
Bright Data's Web Unlocker automatically combines proxy selection, fingerprints, headers, and retry logic to defeat advanced anti-bot systems like Cloudflare, Akamai, and DataDome. On X, users share that it is reliable for AI agents and Cloudflare-protected sites and often returns clean structured JSON4.
How quickly an unblocker tracks anti-bot updates directly determines how "unstoppable" a long-running scraper stays. Zyte's Zyte API does well here too, but Bright Data's dedicated, heavily polished product has the advantage.
SERP API and Dataset Marketplace
A dedicated SERP API that returns Google/Bing results as structured JSON is a mature Bright Data area, and it earns praise alongside Web Unlocker in AI agent workflows5. Zyte has no flagship SERP API, so you build it on the general API with more effort. Bright Data also lets you buy ready-made data via the Dataset Marketplace, which can remove scraper maintenance entirely. For adjacent features around SERP automation, see Bright Data vs Smartproxy 2026.
Zyte's Strengths: Scrapy Cloud and AI Auto-Extraction
In fairness, Zyte has clear strengths Bright Data lacks. Miss them and you risk the wrong call - "great proxies, but heavy development."
Automatic Extraction (AI Structuring)
Zyte's Automatic Extraction uses machine-learning models to pull structured data from common page types - products, prices, reviews, articles, jobs - with little or no custom parsing. Its biggest wins are high out-of-the-box accuracy and resilience when site layouts change. For teams losing hours every month to parser maintenance, this is the standout. Bright Data can structure data via its Web Scraper IDE and AI assist, but it tends to require more implementation and post-processing.
Scrapy Cloud
Scrapy Cloud is a managed SaaS that handles deploy, schedule, scale, monitoring, and storage for Scrapy spiders. It ships Git integration, autoscaling, dashboards, data pipelines, and exports, with a free/dev tier. For Python/Scrapy-first teams, there is no equivalent on the Bright Data side, so this is Zyte's home turf.
Pricing Balance
Zyte API bills per request or compute unit, and because auto-extraction trims wasted bandwidth, the cost per finished record tends to be efficient. Bright Data, meanwhile, is cost-effective at scale and where unblocking value is high, though some users call it pricey for certain use cases6.
In other words, the cost advantage flips on a single question: are you processing large volumes of raw GBs, or do you want finished data with minimal code?
Picking a Side by Use Case
Four common production scenarios and which vendor we'd anchor on. See the decision flow below as well.
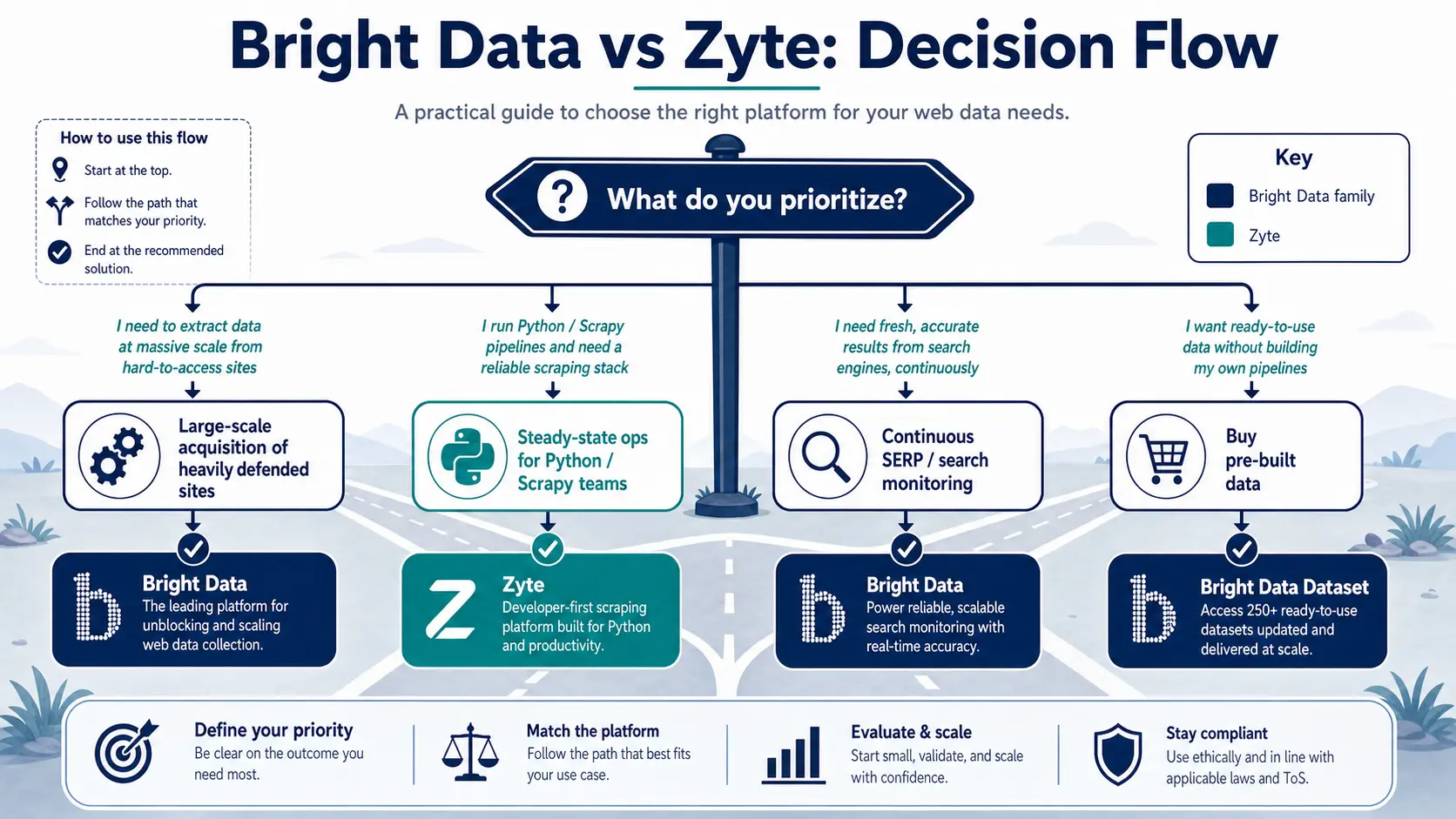
Case 1: Large-scale Acquisition of Heavily Defended Sites
- Pick: Bright Data (Residential + Web Unlocker)
- Cloudflare/Akamai/DataDome bypass and IP pool scale pay off
- Adding Web Unlocker to existing scrapers needs minimal code
- For an Actor-style SaaS comparison, see Bright Data vs Apify 2026
Case 2: Steady-state Ops for Python/Scrapy Teams
- Pick: Zyte (Scrapy Cloud + Automatic Extraction)
- Offload spider deploy, monitoring, and scaling to a SaaS
- Run codeless structuring on common page types
- Route only the toughest sites to Bright Data proxies as a hybrid
Case 3: Continuous SERP / Search Monitoring
- Pick: Bright Data SERP API
- Dedicated API yields stable structured JSON and saves engineering hours
- Zyte requires building on the general API, which adds effort
Case 4: Buying Pre-built Data / AI Training Collection
- Pick: Bright Data (Dataset Marketplace)
- Buy validated, ready-made datasets with lower legal risk
- Bright Data also surfaces often in large-scale web data collection discussions
Hybrid Caveats and Operational Design
You do not have to commit to one vendor, but hybrids carry operational overhead. Keep these design points in mind.
How to Split Roles
- Acquisition (access): route tough sites through Bright Data Web Unlocker / Residential
- Structuring (extraction): run common pages through Zyte Automatic Extraction
- Orchestration: Scrapy Cloud if you are Scrapy-first, your own Lambda / Cloud Run for a general platform
How Smile Comfort Can Help
We have run Bright Data in production for over two years and have evaluated Zyte across multiple client engagements. We have learned which choices look clean on paper but get heavy in practice - and where splitting acquisition from extraction actually optimizes cost.
A sample of what we can help with:
- Proxy Zone design by use case (price monitoring, SERP monitoring, social analytics, etc.)
- Bright Data vs Zyte comparison trial design and success-rate measurement
- Scraping infrastructure (AWS Lambda / Cloud Run + Bright Data + S3 + Snowflake)
- Data platform integration (BigQuery, Snowflake, dbt pipelines)
- Cost optimization across Residential, Datacenter, and Web Unlocker mixes
- Compliance hygiene (robots.txt adherence, rate control, terms-of-service review)
We run Tra-bell, our in-house hotel price-tracking service, on Bright Data's Residential and Web Unlocker stack. Because we have also evaluated Zyte as a comparison vendor, we can advise from the PoC design stage onward.
Summary
Bright Data and Zyte both do "data collection," but their centers of gravity differ. Bright Data leads on acquisition certainty and scale with its 400M+ IP proxy pool, Web Unlocker, SERP API, and Dataset Marketplace. Zyte leads on hands-off structured-data acquisition with Scrapy Cloud and Automatic Extraction. The baseline: Bright Data when bypass and scale are the requirement, Zyte when you are Python/Scrapy-first and want finished data fastest. Hybrid setups that split roles are common in production, and a real trial before signing is essential. Zyte's own account also stresses respecting terms of service, robots.txt, and applicable laws - lawful public-data collection is the shared baseline for both vendors7.
Information current as of 2026-05-31. Please check the official sites for the latest updates.
This article contains affiliate links.
Footnotes
-
Bright Data official site - https://brightdata.com/ ↩
-
Bright Data product lineup - https://brightdata.com/proxy-types ↩
-
Zyte official site - https://www.zyte.com/ ↩
-
User experience with Web Unlocker (X) - https://x.com/chriskrim2002/status/2059591971652407695 ↩
-
SERP API sentiment (X) - https://x.com/YaronBeen/status/2042863522669842757 ↩
-
User sentiment on Bright Data pricing (X) - https://x.com/_aurumX/status/2060312892885684677 ↩
-
Zyte official account on compliance (X) - https://x.com/zytedata/status/2046499235558830539 ↩
Frequently asked questions
Related articles

Bright Data vs Oxylabs 2026: Pricing, Features, and Success Rates Compared

Bright Data vs Apify 2026: Proxy Quality vs Actor Flexibility, Which to Pick
