
Bright Data vs Apify 2026: Proxy Quality vs Actor Flexibility, Which to Pick
Compare Bright Data and Apify across pricing, success rate, and operational effort. Practical guidance for picking between small-scale and large-scale deployments.

This article contains affiliate links (advertising).
"Bright Data or Apify?" is one of the questions we get most often when helping companies build serious scraping infrastructure. The short answer: Bright Data sells IP pool quality and success rate as infrastructure, while Apify sells Actors and developer ergonomics as an application layer. They are less direct competitors than complementary tools. This article compares them across pricing, success rate, and operational effort, and gives a practical rubric for choosing between small and large-scale deployments.
1. Understanding Their Positioning in One View
Bright Data is built around proxy networks (Residential, Datacenter, ISP, Mobile) and layered services like Web Unlocker, SERP API, Scraping Browser, and a Dataset Marketplace. Apify is built around Actors, cloud-hosted scraper containers that you can deploy, share, or buy via the Actor Store.
1-1. Product Lineup Comparison
| Axis | Bright Data | Apify |
|---|---|---|
| Core product | Residential / Datacenter / ISP / Mobile Proxy | Actors (cloud scrapers) and the Actor Store |
| No-code path | Dataset Marketplace (prebuilt data products) | Run any Actor with a single click |
| Anti-bot handling | Web Unlocker (auto CAPTCHA, Cloudflare, Akamai bypass) | Crawlee SDK plus pluggable proxies (you write the logic) |
| SERP data | SERP API returning structured JSON | Buy a Google Search Actor from the Actor Store |
| IP pool scale | 150M IPs across 195 countries (claimed) | Apify proxies plus integration with external providers |
Bright Data competes on IP quality and scale. Apify competes on breadth of Actors and developer experience.
1-2. The Winner Depends on the Target Site
If you scan X discussions in 2026, the verdict flips depending on the target. For social platforms like user profiles or post feeds, several practitioners report that Apify Actors outperform direct Bright Data scraping.
Apify wins here because its community-tuned Actors are specialized for those sites. IP quality alone does not close that gap. If you want a deep dive into Bright Data's pricing first, see our Bright Data Pricing Cheat Sheet 2026.
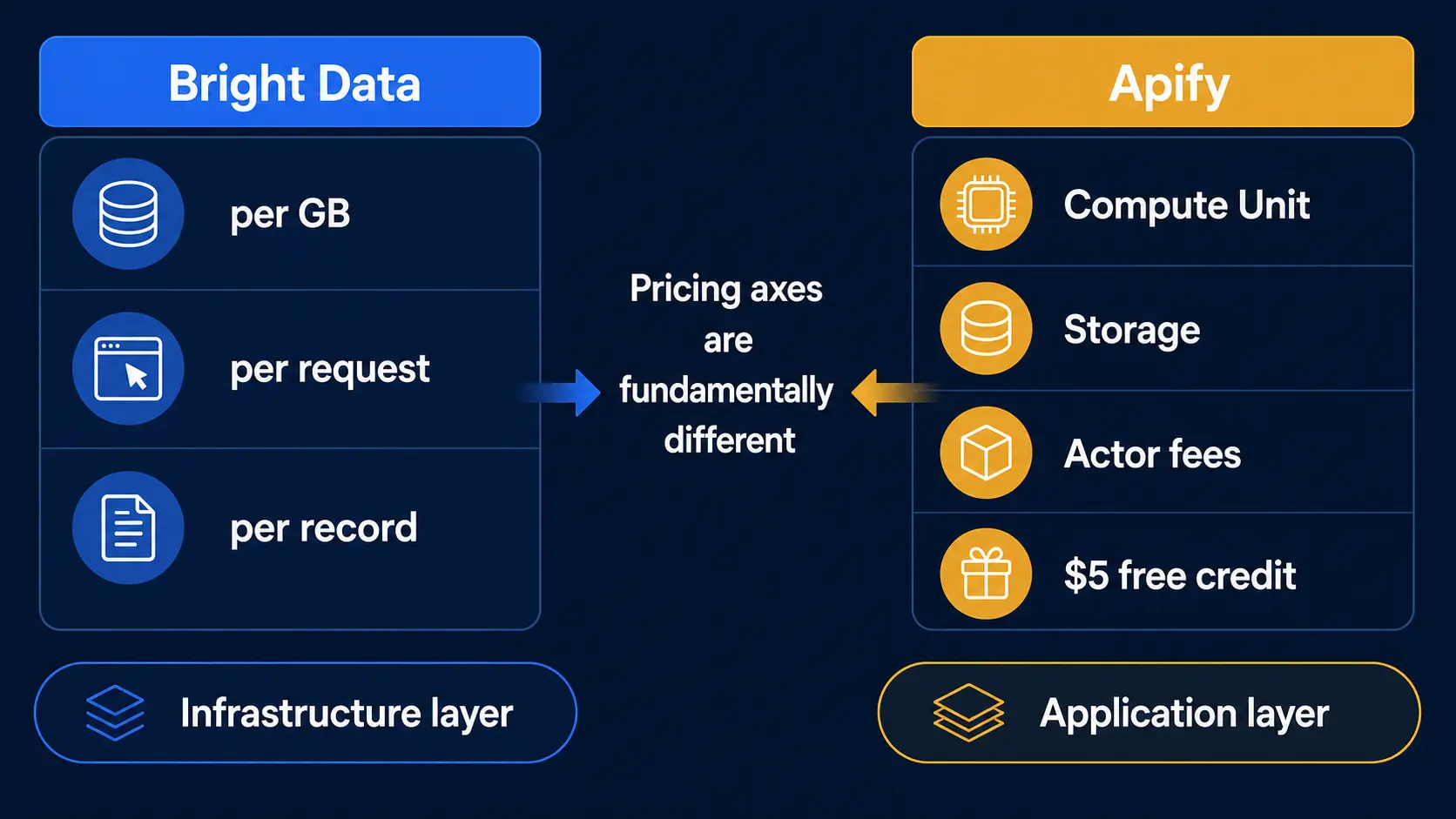
2. The Two Pricing Models Are Fundamentally Different
Both are usage-based, but the units differ enough that face-value comparison is misleading.
2-1. Bright Data Pricing Axes
- Residential Proxy: From $15/GB (~¥2,250/GB), with tiered volume discounts.
- Datacenter Proxy: From $0.5/GB (~¥75/GB), with static IP options.
- Web Unlocker: From $3 per 1,000 requests (~¥450), billed only for successful responses.
- SERP API: From $3 per 1,000 requests, returning structured JSON.
- Dataset Marketplace: Per-record pricing down to $0.001/record (~¥0.15) at very high volume.
Volume discounts are aggressive. Above 500K records per month, the effective per-record cost drops substantially.
2-2. Apify Pricing Axes
- Compute Unit (CU): Billed for Actor runtime and memory consumption.
- Storage: Per-GB billing for datasets and key-value stores.
- Proxy bandwidth: Charged when using Apify's own proxy network.
- Actor fees: Paid Actors in the Store set their own pricing (monthly, per run, or per record).
- Free tier: New users get $5 (~¥750) in credits.
Compute Unit consumption tracks the size of the machine you run on, so code efficiency directly drives cost.
2-3. Bright Data Wins at Volume
X discussions consistently flag that beyond 500K records per month, Bright Data's per-record pricing becomes hard to beat.
Apify shines in the free and mid-volume range, but Compute Unit consumption can compound at scale. Starting on Apify and migrating to Bright Data as volume grows is a reasonable trajectory.
3. Evaluating Success Rate and Operational Effort
Choosing the cheaper option is right in the short term, but a low success rate means retries that quietly inflate cost. Always compare effective cost, defined as billed amount divided by successful records. Here is the approach we use in production PoCs.
3-1. Run the Same 1,000 URLs Through Both
- Build a target URL list (for example, 1,000 product detail pages).
- For Apify, pick a relevant Actor from the Store or write a Crawlee scraper.
- For Bright Data, hit Web Unlocker directly.
- Record success rate, total time, and actual bill.
- Compute effective unit price as
billed_amount / successful_records.
We run this same drill for our own product Tra-bell whenever we add a new target. In our experience, sites guarded by Akamai or Cloudflare favor Bright Data's Web Unlocker, while long-tail e-commerce sites are often faster to launch on Apify Actors.
3-2. Operational Phase Differences
| Aspect | Bright Data | Apify |
|---|---|---|
| Time to first request | Need to set up proxy zones and tune for success | Run an existing Actor in minutes |
| Output schema consistency | Unified API responses, easy to handle | Schema varies per Actor |
| Failure isolation | Clear split between proxy layer and your code | Bugs inside an Actor are harder to inspect |
| Compliance documentation | KYC, GDPR, CCPA published publicly | Depends on each Actor author |
| Adding a new target | You implement the scraper yourself | Often available in the Actor Store |
3-3. The Third Option: Hybrid Deployment
Hybrid usage has become more common in 2026. By dropping Bright Data endpoints into an Apify Actor's proxy settings, you get Actor ergonomics combined with Residential-grade success rate.
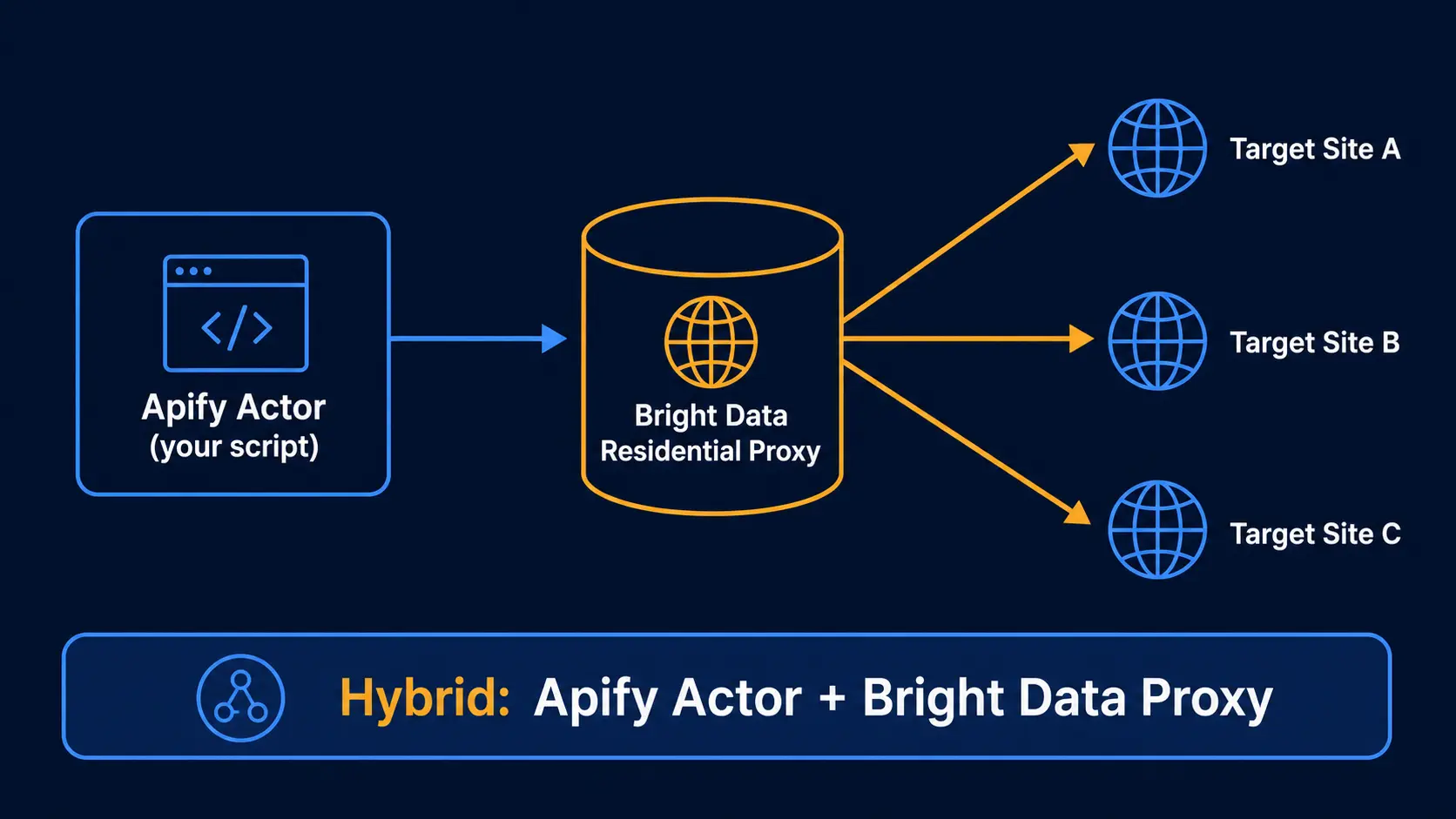
For our clients, we often recommend starting on Apify Actors and shifting weight onto Bright Data as the volume profile becomes clear. For more competitor context, see Bright Data vs Oxylabs 2026.
4. Recommendation by Use Case
Five common scenarios from real projects, with a default recommendation for each:
| Use case | Recommendation | Reason |
|---|---|---|
| E-commerce price monitoring (500K+ records/month) | Bright Data | Web Unlocker plus Residential maintains success rate while volume pricing kicks in |
| Google SERP tracking | Bright Data | SERP API returns structured JSON, lowering ongoing maintenance |
| LinkedIn / Instagram profile collection | Apify | Mature Actors targeting these sites are ready to run |
| PoC for a new target site | Apify | $5 free credit and Actor Store get you running fastest |
| Large-scale AI training data | Bright Data plus Apify hybrid | Best balance of cost and coverage |
For CAPTCHA design, pair this with Bright Data Web Unlocker Practical Guide 2026.
5. Hedging Against Centralized-Service Risk
Both companies continue to grow in 2026, but there is rising concern on X about centralized pricing pressure and single points of failure.
Decentralized scraping infrastructure is not yet production-ready, but vendor lock-in is a real consideration. We typically recommend the following design principles to clients.
- Abstract the proxy layer so Bright Data, Apify, or a self-hosted alternative are all swappable.
- Keep the data layer (BigQuery, Snowflake) under your own control.
- Run retries and job queues on your own infrastructure (AWS SQS, Lambda), not locked inside a vendor.
We help design and run these patterns end-to-end. Our Bright Data Residential Proxy for Price Monitoring: A How-To walks through one such reference architecture.
6. Our Own Case: Why Tra-bell Runs on Bright Data
We operate Tra-bell, a hotel price tracking service, on top of Bright Data's Residential Proxy and Web Unlocker. We evaluated Apify at the start, but the combination of hundreds of thousands of URLs per day, high success-rate requirements, and well-documented compliance pushed us to Bright Data.
If you are designing similar production-grade scraping infrastructure, we can help with architecture, PoCs, and cost optimization on a project basis.
7. Conclusion: Split by Scale and Target
Bright Data and Apify are less rivals than complementary services. For small projects, PoCs, and targets covered by Apify Actors, pick Apify. For large volume, high success-rate requirements, and ongoing SERP or e-commerce monitoring, pick Bright Data. Hybrid deployments using Apify Actors with Bright Data proxies are increasingly common as teams scale. Above all, decide based on effective cost (price divided by success rate) rather than headline unit pricing.
Information current as of 2026-05-21. Please check the official sites for the latest updates.
This article contains affiliate links.
Frequently asked questions
Related articles

Bright Data Pricing Cheat Sheet 2026: Product-by-Product Cost Guide

Bright Data vs Oxylabs 2026: Pricing, Features, and Success Rates Compared
