
Bright Data Web Unlocker Practical Guide 2026: CAPTCHA Bypass and Cost Design
How to design and operate Bright Data Web Unlocker for Cloudflare and reCAPTCHA bypass, plus pricing model, Residential Proxy split, and pitfalls from production.

This article contains affiliate links (advertising).
Bright Data Web Unlocker is an API-based product that automatically bypasses advanced bot defenses, including Cloudflare and reCAPTCHA. Drawing on our production operations, this guide covers when Web Unlocker fits a target site, how to split traffic with Residential Proxy, the success-based pricing model, and the legal guardrails to keep in mind. The bottom line we landed on after years of running scrapers in production: route bot-heavy EC and airline/ticket sites to Web Unlocker, send geographic-sensitive scraping through Residential, and combine both to keep monthly cost predictable. We will walk through each of these choices with the trade-offs we encountered, so you can pick a configuration that fits the targets you care about most.
What Web Unlocker Is and How It Differs From a Plain Scraper
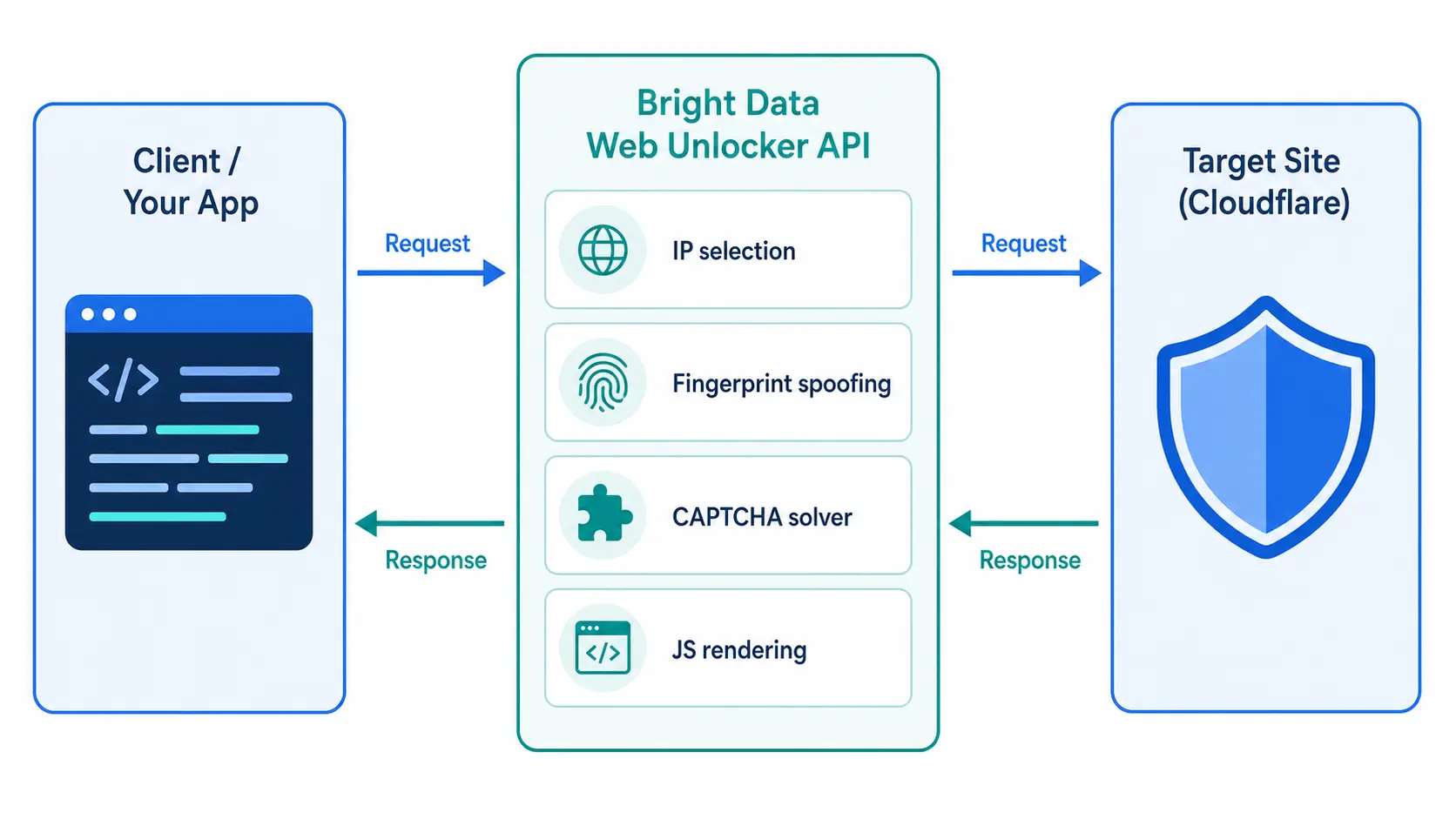
Web Unlocker is Bright Data's "API that automatically bypasses bot defenses on access." You send a URL and options, and the service handles the following internally before returning a response:
- IP selection: Picks among Residential, Datacenter, and Mobile based on the target's risk profile, so you do not need to maintain rotation logic
- Header and fingerprint spoofing: Aligns User-Agent, Accept-Language, and TLS fingerprint with real-device profiles, which is the part most home-grown scrapers get wrong
- Automatic CAPTCHA handling: Resolves reCAPTCHA, hCaptcha, and Cloudflare Turnstile with a combination of internal solvers and fallback workflows
- JavaScript rendering: Returns post-render HTML through headless browsers when needed, useful for SPAs and product detail pages that hydrate on the client
- Automatic retries: Rotates IP and fingerprint on failure and retries up to the limits you configure, with success-based billing applied
Plain proxy products only "lend you an IP," leaving fingerprint spoofing and CAPTCHA solvers for you to bolt on when you hit Cloudflare Turnstile or Akamai Bot Manager. Web Unlocker bundles that "must-build layer" into a single API endpoint, which is why teams reach for it once their custom scraper starts collecting more 403 responses than data. Positioning-wise, it sits between a raw proxy (cheaper, more flexible, more engineering work) and a fully managed scraping SaaS (higher level, less control, narrower target coverage).
Comparison With Competitors
| Tool | Approach | Difference vs Bright Data Web Unlocker |
|---|---|---|
| ScraperAPI | API-based bypass | Smaller IP pool, weaker enterprise SLA |
| Apify | Scraping SaaS | Application layer; Web Unlocker is infrastructure layer |
| Scrapling (OSS) | TLS/HTTP3 spoofing + custom CAPTCHA bypass | Self-hosted, requires maintenance, stability needs validation |
| ZenRows | API-based bypass | Bright Data leads on IP pool and SLA |
Web Unlocker is also gaining traction as the "layer that reliably returns JSON from Cloudflare-protected sites" for AI agents like Mastra, n8n, and Claude/Cursor when accessed via MCP servers. In AI-assisted development workflows we have seen, agents call Web Unlocker via MCP to fetch product data, scrape competitive intelligence, or pull market signals, and then hand the parsed JSON to an LLM for downstream reasoning. That two-step pattern was hard to stabilize with raw proxies, but the success-based contract Web Unlocker offers makes it tolerable inside an agentic loop.
The growing reference from AI agent infrastructure is one of the drivers behind Web Unlocker's expanding presence.
Pricing and the Reality of Success-Based Billing
Web Unlocker pricing is expressed per 1,000 requests as of May 2026.
Unit Cost Range
| Item | Cost guideline |
|---|---|
| Web Unlocker standard | $3 / 1,000 requests (~¥450/1k) |
| Volume discount | 30–50% off above 1M requests/month |
| Annual contract discount | 10–20% off on monthly equivalent |
The success-based billing model means 404s and outright blocks do not generate charges, which is a meaningful improvement over flat per-request billing when you target heavily defended sites. However, "success" is judged by status code 200 combined with response inspection, so you need to monitor the share of requests that actually hit the billing condition. Teams that skip this step often see a 15–25% gap between forecast and actual invoice in the first month. We recommend setting up a small dashboard that tracks status codes, retry counts, and bill-eligible request shares from day one. For the full pricing picture across Bright Data products, including Residential, Datacenter, and SERP API tiers, see our Bright Data Pricing Cheat Sheet 2026 before signing a contract.
Three Cost Optimization Patterns
- Tiered fallback: Try Datacenter Proxy first, route only failures to Web Unlocker. Cheap paths handle simple public pages, and only the truly defended URLs hit the premium API. We typically see 60–70% of total traffic resolved on the cheap tier.
- Cache layer: For workloads that hit the same URL multiple times, a 24-hour cache often halves the bill. Redis or DynamoDB with TTL works well in production; the cache hit rate is usually the single biggest lever on monthly spend.
- URL pre-filtering: Skip Web Unlocker for sites without bot detection and those with public JSON APIs. A simple allowlist/denylist sitting in front of the routing logic prevents accidental over-spend.
Japanese operators have publicly questioned whether "tools that bypass bots with success-based billing" are legal. We unpack the legal angle next.
Four Legal and Ethical Principles to Anchor On
Web Unlocker enables technical access, but does not resolve terms of service, copyright, or personal data law issues at the target. Using the tool itself is not illegal, but depending on the target and request pattern, civil liability remains in scope.
1. Always Review Terms of Service
If a target site explicitly bans scraping in its ToS, technical retrieval can still violate the contract. Job boards, racing and sports data, and real estate listings are particularly protective because "the data is the business."
2. Respect robots.txt and Crawl-Delay
robots.txt is advisory, but ignoring Crawl-Delay can lead to civil claims related to unfair competition or business interference under server-load arguments. Even with Web Unlocker, the responsibility to enforce your own rate limits stays with you.
3. Handle Personal and Sensitive Data Carefully
GDPR, CCPA, and Japan's Act on the Protection of Personal Information all require extra care when collecting personally identifiable data. Bright Data clears KYC on the IP side, but the legality of the data you collect is your responsibility.
4. Stay Within Public Data
Login-walled data, paid content, and API-key-protected areas are out of scope. Web Unlocker may technically reach them in some configurations, but "can" and "should" are different questions, and operating in the gray zone here is what tends to convert a technical project into a legal incident.
Splitting With Residential Proxy: The Operational Decision Axis
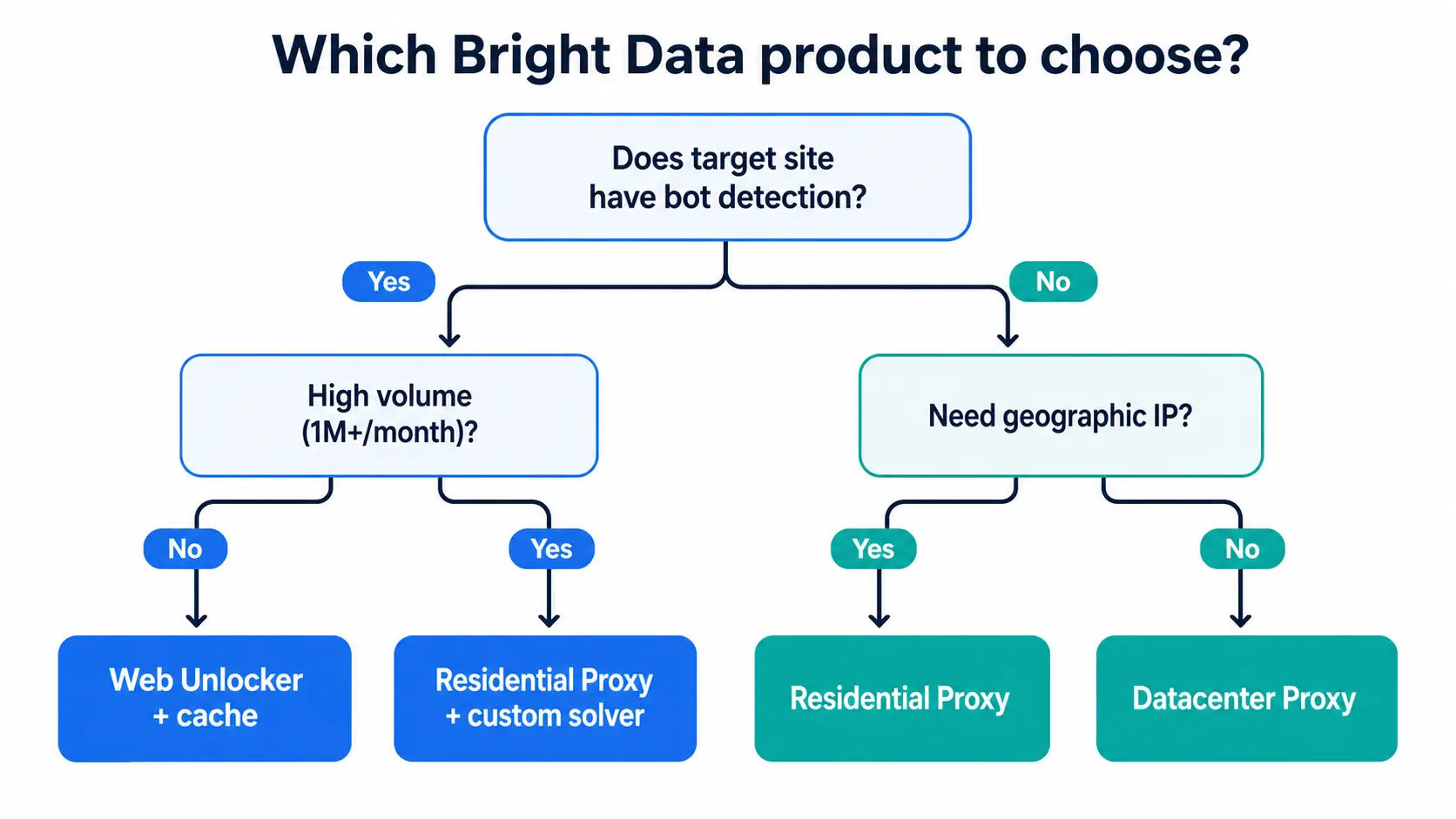
Web Unlocker is not a universal solution; pairing it with Residential Proxy is the realistic stance. Here is the decision framework.
When to Pick Web Unlocker
- High-bar bot defenses (Cloudflare, reCAPTCHA, Akamai) sit in front and your custom scraper is collecting more 403s than data
- You need post-JavaScript DOM (SPAs, product detail pages) and do not want to operate a fleet of headless browsers
- Low to medium frequency (under 100K requests/month) where IP management overhead would dominate the engineering hours
- You want Bright Data to handle retries on failure and prefer to optimize for time-to-data rather than unit cost
When to Pick Residential Proxy
- Geographic price or search result diversity matters (JP IP, US IP, regional discounts) and you need fine-grained control over location targeting
- High volume (1M+ requests/month) where unit cost dominates the equation and the team has the engineering budget to operate the stack
- You want to own response parsing, session management, and cookie persistence at the application layer
- CAPTCHA rarely appears (public product pages, SEO monitoring, news aggregation) and the bot defense bar is low
For a concrete Residential build, see Bright Data Residential Proxy for Price Monitoring: A How-To, which complements this Web Unlocker guide when you design a combined topology.
Where Web Unlocker Beats the Competition
Versus other bot-bypass APIs, Web Unlocker leads on IP pool size (1.5B IPs across 195 countries), API coverage including MCP integrations, and enterprise SLA (99.99% uptime). It is not the cheapest, but on a TCO basis that includes engineer recovery time and IP management overhead, the premium is reasonable for teams that need reliability over absolute lowest cost. The KYC-verified IP pool also makes the compliance conversation simpler when stakeholders ask where the traffic originates. For a head-to-head comparison with Oxylabs in the same tier, see Bright Data vs Oxylabs 2026: Pricing, Features, and Success Rates Compared.
Lessons From Operating Tra-bell on Bright Data
At Smile Comfort, we run Tra-bell, a hotel price tracking service, on a combination of Bright Data Residential Proxy and Web Unlocker. Lightly defended booking sites route through Residential, while Cloudflare-protected OTAs go through Web Unlocker, and we tune monthly cost with this two-tier routing. The architecture has held up across several rounds of OTA bot defense upgrades since we put it in place.
From production experience, here is what worked, what required adjustment, and what was a missed call:
- What worked: We dropped custom fingerprint spoofing on Cloudflare-protected OTAs. Engineering maintenance went from 20 hours per month to 3, and on-call incidents related to scraper failures became rare. The reliability gain alone justified the Web Unlocker premium.
- Where we adjusted: The success-based bill came in 20% above forecast initially because our retry policy was too aggressive. We tightened response inspection, lowered the retry ceiling, and added a 24-hour cache layer to bring spend back in line with the original budget.
- What we missed: Early on, we routed bot-free pages (publicly cached hotel descriptions) through Web Unlocker and inflated the bill needlessly. We added a URL router to triage paths properly, and that single change cut Web Unlocker spend by roughly 30%.
We can help with the design, PoC, and operation of similar scraping platforms, including the routing and cost-control patterns described above.
You can find the Tra-bell architecture and our reference setup for Bright Data-based scraping platforms below.
Wrap-Up: Pick Web Unlocker Where It Actually Earns Its Keep
Web Unlocker is an API-based product that automatically bypasses Cloudflare, reCAPTCHA, and similar bot defenses. It is not a universal answer, and the operational playbook is to combine it with Residential Proxy, pre-filter target URLs, and layer in caching to keep cost in check. On the legal side, "the tool is legal, but the target ToS and robots.txt are separate questions" should be your anchor, and a one-pass legal review before production rollout is strongly recommended. The teams that get the most value from Web Unlocker treat it as one tool in a tiered routing strategy rather than the only tool, and they invest in observability from day one so the bill stays close to the forecast. Bright Data's features and pricing evolve, so verify the latest details on the official site before signing.
Information current as of 2026-05-21. Please check the official sites for the latest updates.
This article contains affiliate links.
Frequently asked questions
Related articles

Bright Data Pricing Cheat Sheet 2026: Product-by-Product Cost Guide

Bright Data Residential Proxy for Price Monitoring: A How-To

