
Bright Data ブラウザ指紋制御 完全ガイド 2026 - Canvas/WebGL/TLS 設計
Cloudflare や DataDome に見抜かれない Browser fingerprint の構成要素と、Bright Data Scraping Browser がどう自動制御するかを 2026 年最新の実運用目線で整理します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
Cloudflare や DataDome に弾かれずに JavaScript レンダリングが必要なサイトを巡回したいなら、Browser fingerprint (ブラウザ指紋) を Chromium バイナリレベルで揃える ことが 2026 年現在の必要条件です。User-Agent や Proxy だけを差し替える時代は終わりました。本記事では、Canvas / WebGL / Audio / Font / TLS / HTTP/2 という指紋の構成要素を整理し、Bright Data Scraping Browser が何を自動制御しているのか、playwright-stealth との違いまで、弊社が Tra-bell の運用で蓄積したノウハウとともに整理します。
Browser fingerprint の構成要素
ブラウザ指紋は単一のシグナルではなく、ブラウザがネットワークと描画に残す痕跡の集合体 です。代表的な検知サービス (Cloudflare、Akamai、DataDome、PerimeterX、FingerprintJS) は次のレイヤを総合的に評価しています。
ネットワーク層の指紋
- TLS フィンガープリント (JA3 / JA4): ClientHello の cipher suite、extension の順序、curve 一覧から算出される。Chrome 純正と Node.js + axios では JA3 ハッシュが異なり、一発で bot と判定される
- HTTP/2 SETTINGS フレーム順序: Chrome は
HEADER_TABLE_SIZE → ENABLE_PUSH → MAX_CONCURRENT_STREAMS → INITIAL_WINDOW_SIZEの特定順で送るが、cURL や Go の標準実装は順序が違う - HTTP/2 PRIORITY フレーム: Chrome は重み付けでリクエストを並べる。requests ライブラリは送らない
- HTTP ヘッダの順序: Accept-Language が User-Agent の前にあるか後にあるかでも変わる
- ALPN ネゴシエーション: HTTP/2 と HTTP/3 のどちらを優先するかが Chrome と一致するか
ブラウザ実行時の指紋
- Canvas fingerprint: HTML5 Canvas に「Hello, 🌍」のような文字列を描画して toDataURL で取得。GPU / フォントレンダラの組み合わせで微妙に違う出力になる
- WebGL fingerprint: GPU ベンダー (
UNMASKED_VENDOR_WEBGL)、レンダラ名 (UNMASKED_RENDERER_WEBGL)、対応拡張一覧 - AudioContext fingerprint: OscillatorNode → DynamicsCompressor → AnalyserNode の経路で生成される波形を FFT。CPU と OS で異なる
- Font fingerprint:
document.fontsから取得できる利用可能フォント一覧。Linux ヘッドレスとデスクトップ Mac で大幅に違う - Navigator / Screen:
navigator.platform、navigator.hardwareConcurrency、screen.width / height / colorDepth、devicePixelRatioの組み合わせ - WebRTC IP リーク: STUN サーバー経由で取得される実 IP。プロキシを通していても WebRTC で本 IP が漏れると一発検知
行動・時間の指紋
- マウス移動の軌跡 (ベジエ曲線か直線か)
- キー入力のばらつき (人間は 80〜200ms、bot は固定値)
- ページ滞在時間と navigation のタイミング
- スクロール速度と慣性
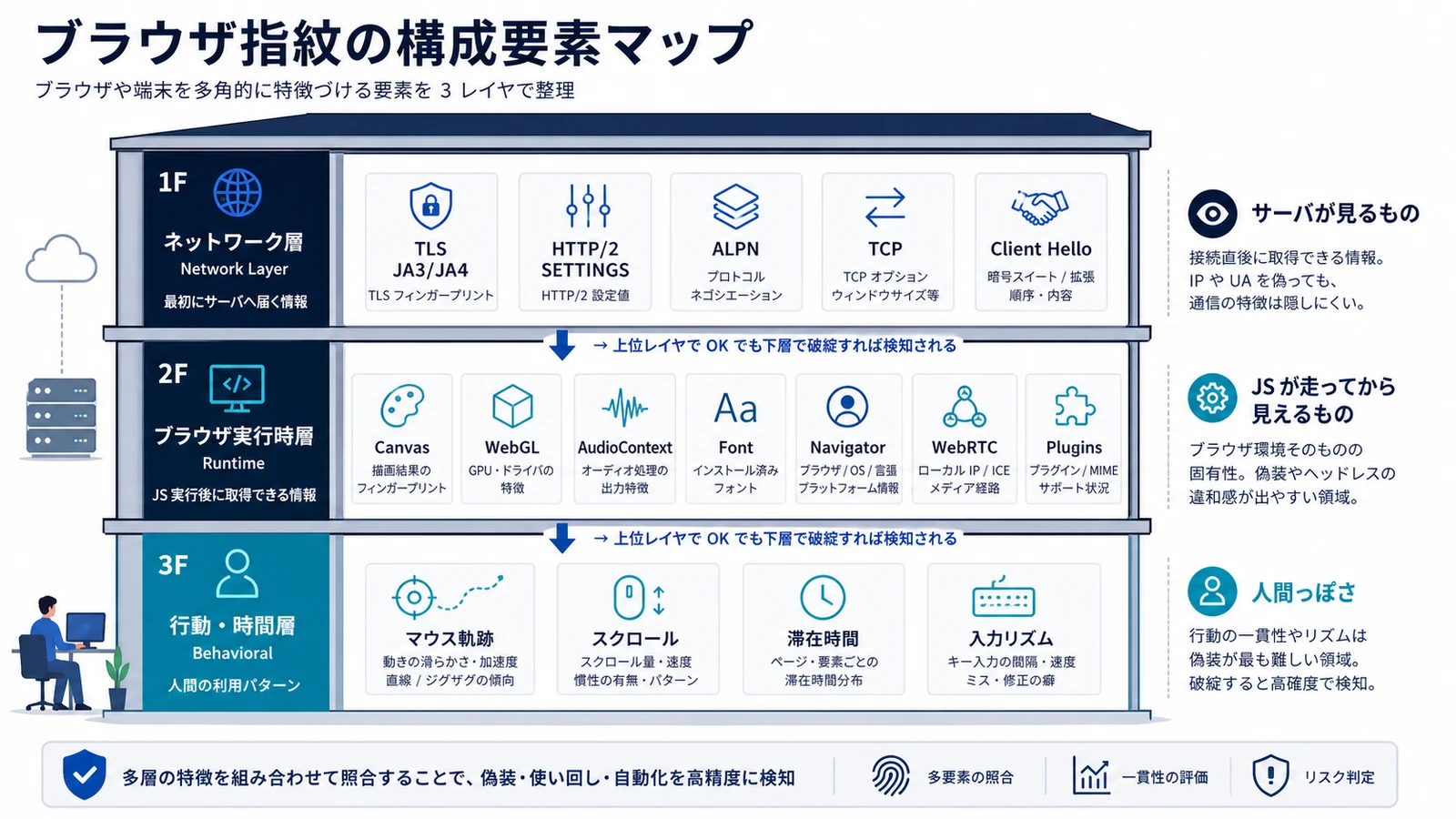
これらが「Chrome 純正からの逸脱」として 1 つでも検知シグナルに引っかかれば、リスクスコアが上がります。Cloudflare のような商用 WAF は 50〜200 個のシグナルを統合し、0.1 秒以内に block / challenge / allow を判定しているのが現状です1。
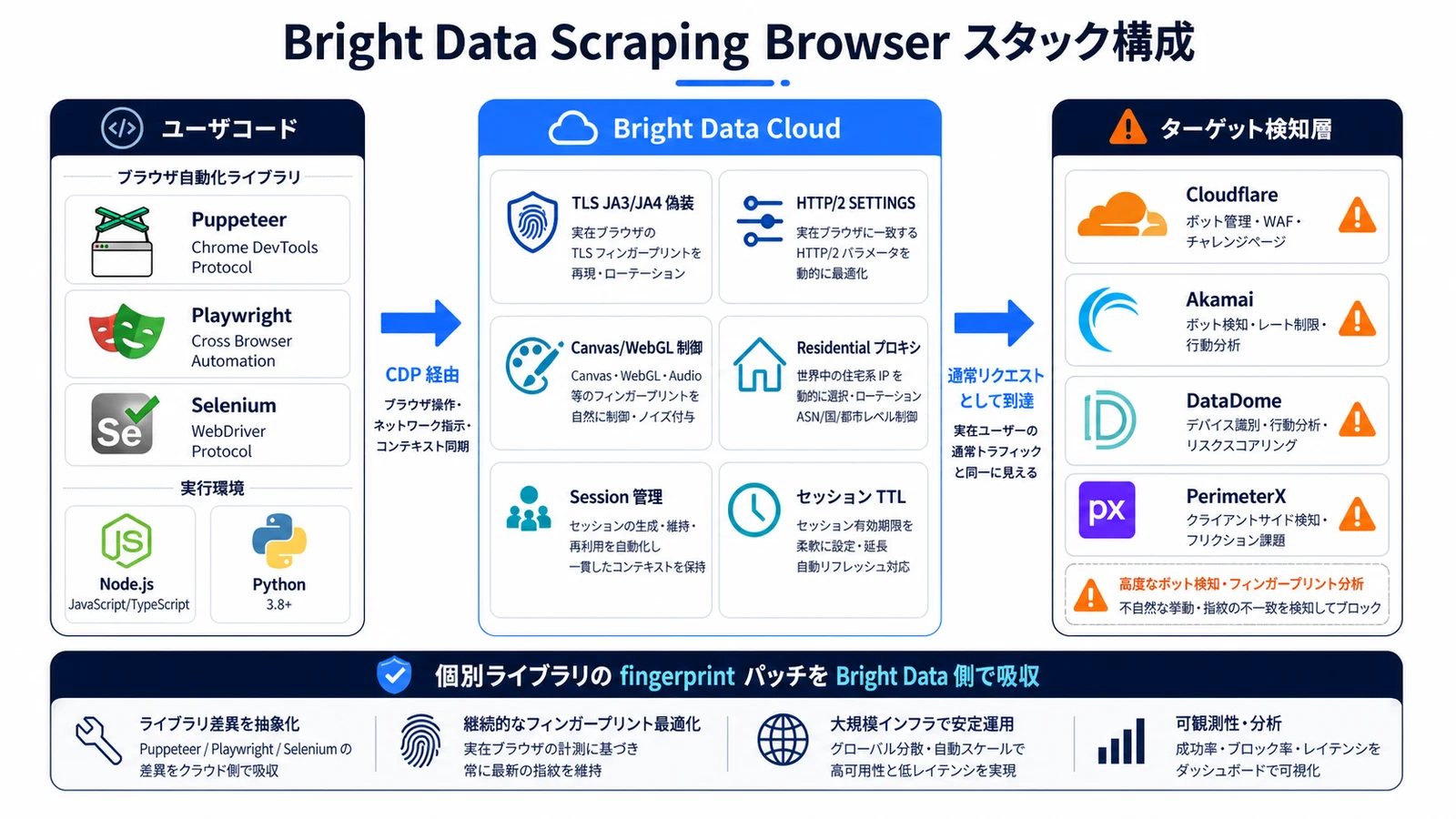
Bright Data Scraping Browser が自動制御するレイヤ
Bright Data Scraping Browser は、上記のうち 「ネットワーク層」と「ブラウザ実行時」の指紋をバイナリレベルで揃える マネージドサービスです。Puppeteer / Playwright から WebSocket (CDP) で接続するだけで、内部の Chromium が現実的なプロファイルをローテーションしながら動きます。
自動で揃えてくれる項目
| レイヤ | 制御内容 | 効果 |
|---|---|---|
| TLS / JA3 / JA4 | Chrome 純正と一致する ClientHello を送信 | curl / requests で出る一発検知を回避 |
| HTTP/2 SETTINGS | Chrome 順序で送信、PRIORITY フレームも実装 | HTTP/2 fingerprint で見抜かれない |
| Canvas / WebGL | リアル GPU プロファイルプールから seed 選択 | レンダリング結果が機械的でない |
| AudioContext | 実機ベースの波形プロファイル | 音声指紋を機械的な単一値にしない |
| Font | OS ごとに整合した font list を返す | Linux ヘッドレスの font 欠落を埋める |
| Navigator | platform / hardwareConcurrency が IP の国と整合 | プロキシと navigator の齟齬を回避 |
| WebRTC | STUN リクエストを内部で遮断 | 実 IP リークを防ぐ |
| User-Agent | Chrome の最新版に追従、IP の地域と整合 | バージョン古さでの検知を回避 |
弊社の Tra-bell では、自前 Playwright + Residential プロキシ + playwright-stealth の構成から Scraping Browser へ切り替えた際、対象 EC モールでの block 率が 12% から 0.8% に下がる という変化を観測しました。playwright-stealth の paving 跡が検知シグナルになっていたケースです。
Scraping Browser に CAPTCHA まで委ねる構成
WebSocket 接続例は次の通りです。CDP プロトコルなので Puppeteer / Playwright のスクリプトは接続部だけ書き換えれば動きます。
import puppeteer from "puppeteer-core";
const SBR_WS = `wss://brd-customer-XXX-zone-scraping_browser1:PASSWORD@brd.superproxy.io:9222?country=jp&session-id=abc123`;
async function main() {
const browser = await puppeteer.connect({ browserWSEndpoint: SBR_WS });
try {
const page = await browser.newPage();
await page.goto("https://target-site.example.com", { timeout: 120_000 });
const html = await page.content();
console.log(html.length);
} finally {
await browser.close();
}
}
main();
country=jp で日本の IP を、session-id=abc123 で同一フィンガープリントとプロキシを最大 30 分維持できます。フィンガープリントを「ランダムに変える」ことが目的ではなく、シナリオ単位では一貫させる のがポイントです。同じセッション内で IP やフィンガープリントがブレると、それ自体が異常シグナルになります。詳細な接続パターンはBright Data × Playwright 統合ガイド 2026で整理しています。
「フィンガープリント分散は『ランダム化』ではなく『現実的なプロファイルプールからの選択』であるべき。乱数を当てたものは検知器に見抜かれる」というのが、2026 年の anti-bot コミュニティの共通認識になっています。
playwright-stealth との違い
「Playwright に stealth プラグインを入れれば十分では?」という質問はよく受けます。2024 年頃までは多くのサイトで通用しましたが、2026 年現在の主要な bot 検知サービスは JS パッチの跡を逆検知 するようになっており、状況が変わっています。
JS パッチが検知される理由
playwright-stealth / puppeteer-extra-plugin-stealth は、navigator.webdriver = undefined のような上書きを JavaScript 実行時 に当てます。検知側はこれを見つけるために次のシグナルを使います。
Function.prototype.toString.call(navigator.webdriver)の文字列パターンObject.getOwnPropertyDescriptor(Navigator.prototype, 'webdriver')の getter 差分setTimeoutの解像度が 1ms 単位に固定される (現代の Chrome は throttle 込み)Notification.permissionとpermissions.queryの不整合
「打ち消しの不自然さ」が新たな指紋になっているのが現状です。CloakBrowser のような Chromium バイナリ自体にパッチを当てるアプローチや、Bright Data Scraping Browser のような ベンダー運用の patched Chromium に流れているのは、この背景があります2。
検知耐性の実測比較 (弊社 PoC)
弊社が 2026 年 4 月に実施した PoC では、reCAPTCHA v3 のスコアと block 率は次のような傾向でした (対象: 主要 EC モール 1 サイト、各 1,000 リクエスト)。
| 構成 | reCAPTCHA v3 スコア中央値 | block 率 |
|---|---|---|
| 素の Playwright + Datacenter Proxy | 0.1 | 89% |
| Playwright + playwright-stealth + Residential | 0.3 | 47% |
| Bright Data Scraping Browser | 0.9 | 0.8% |
ただしこれは特定サイト 1 ケースで、対象サイトの検知設計やシーズンによって変動します。Scraping Browser でも 100% 突破は保証されません。サイトごとに PoC して数字で確認する のが基本です。CAPTCHA 別の対処レシピはBright Data で CAPTCHA に遭遇したときの対処レシピ 2026に整理しています。
「最新の検知は指紋だけでなく行動分析と GPU 関連シグナルも組み合わせる」という指摘の通り、2026 年は静的指紋を揃えるだけでは足りない場面が増えています。マウス軌跡やスクロールの自然さも、Scraping Browser のような上位サービスに任せると安定します。
行動シグナルと運用のチェックポイント
ネットワーク層と実行時指紋を揃えても、行動シグナルで弾かれるケースがあります。とくに 連続アクセスのテンポ・操作の順序・ページ滞在時間 は、Scraping Browser でも自前で意識する必要があります。
行動シグナルを自然にするポイント
- マウス移動を入れる:
page.mouse.move()をベジエ曲線で 2〜3 ステップに分割 - navigation の間隔をばらつかせる: 固定 5 秒ではなく
random.uniform(3, 8)程度の揺らぎ - スクロールを段階的に: 一気に最下部まで送らず、
scrollBy(0, 300)を 5〜10 回 - 意味のないクリックを混ぜる: たまにメニューやロゴをクリックして人間らしさを出す
- referrer を保つ: Google 検索からの流入を装うなら
referer: https://www.google.com/を付ける
よくある失敗
加えて、country= パラメータと対象サイトの言語が齟齬すると navigator.language と齟齬します。日本向けサイトを叩くなら country=jp を必ず指定し、Accept-Language: ja,en-US;q=0.9 も合わせます。Web Unlocker と Scraping Browser の使い分けはBright Data Scraping Browser 実践活用ガイド 2026で詳しく整理しています。
bot 検知サービス別の傾向
主要な検知サービスはそれぞれ得意な指紋レイヤが違います。設計の起点として把握しておくと、PoC の選定が早くなります。
Cloudflare (Turnstile / Managed Challenge)
- 主に TLS JA3 と HTTP/2 fingerprint で 1 次判定
- 突破できない URL は Web Unlocker に切り替えるのが定石
__cf_bmクッキーの維持で連続アクセスの success rate が上がる
DataDome
- 行動シグナル (マウス・スクロール) を重視
- Scraping Browser + 適度な navigation 遅延が有効
- 同一セッションでの IP 変更を強く検知するため session-id を固定
Akamai Bot Manager
_abckクッキーと sensor data POST が主軸- Scraping Browser が内部で sensor data を生成してくれる
- 失敗時のフィードバックループが弱く、変化を確認しにくい
PerimeterX (HUMAN)
_pxクッキーの妥当性と client.perimeterx.net への参照を確認- Scraping Browser でほぼカバーされるが、突破できなければ Web Unlocker フォールバック
FingerprintJS / その他商用
- ブラウザ実行時指紋を多角的に評価
- 行動シグナルよりも静的指紋に重み
- Scraping Browser のプロファイルプールが効きやすい領域
まとめと弊社の運用ノウハウ
弊社では Bright Data の Residential プロキシと Scraping Browser を組み合わせて、自社プロダクト Tra-bell — スクレイピング技術を使ったホテル価格追跡サービス — を運用しています。サイトごとに Web Unlocker / Scraping Browser / Residential を使い分け、行動シグナルとセッション設計を含めて Block 率を 1% 未満に抑える設計を実プロダクションで回してきました。PoC 段階の検知率測定、本番運用へのスケール、コスト最適化までは弊社のスクレイピング基盤構築メニューでお請けできます。
2026 年現在、JavaScript レンダリングを伴うスクレイピングで Bright Data のような バイナリレベルで指紋を揃えるマネージドブラウザ を選ぶ価値は、playwright-stealth と比較してもはっきり数字に出ます。Canvas / WebGL / Audio / Font / TLS / HTTP/2 の各レイヤが整合した状態を、自前で維持し続けるのは現実的ではないからです。
設計の優先順位は次の通りです。
- ネットワーク層と実行時指紋を Scraping Browser に委譲
- session-id でフィンガープリントを一貫させ、サイトごとに分離
- 行動シグナル (テンポ・スクロール・クリック) を自然に設計
- block 率をサイト単位で計測し、Web Unlocker と使い分け
「指紋をランダム化する」のではなく「現実的なプロファイルを一貫して使う」のが 2026 年のセオリーです。
※情報は 2026-05-24 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
Footnotes
-
Cloudflare Bot Management Documentation - https://developers.cloudflare.com/bots/ ↩
-
Bright Data Scraping Browser Documentation - https://docs.brightdata.com/scraping-automation/scraping-browser/ ↩
よくある質問
関連記事

Bright Data Scraping Browser 実践活用ガイド 2026 - Puppeteer/Playwright 統合とコスト設計

Bright Data × Playwright 統合ガイド 2026 - プロキシ設定からスクレイピング実装まで
