n8n × Bright Data でノーコード自動データ収集を構築するガイド 2026
n8n のワークフロー自動化に Bright Data を組み込み、トリガーから収集・整形・保存までをノーコードで回す構成を実運用視点で解説します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
「公開 Web からのデータ収集を、コードを書かずに毎日自動で回したい」——この要望に最短で応えるのが n8n と Bright Data の組み合わせです。本稿は n8n とは何か、Bright Data をどう組み込むか、トリガーから保存までのワークフロー設計、API キーの安全な扱い、料金感までを、弊社の Bright Data 運用経験を踏まえて整理します。結論から言えば、定期的な公開データ収集は自己ホストの n8n と Bright Data の従量課金だけで、月数千円規模から実用的に始められます。
1. n8n と Bright Data を 60 秒で整理する
n8n (エヌエイトエヌ) は、ノードをドラッグ&ドロップで繋いで業務を自動化するソース公開型 (Sustainable Use License のフェアコード) のワークフロー自動化ツールです。Zapier や Make に近い立ち位置ですが、Docker で自己ホストでき、400 以上のサービス連携と AI Agent ノードを備えるのが特徴です。ここに Bright Data を組み合わせると、Bot 検知やCAPTCHA に阻まれがちな公開 Web からのデータ収集を、安定したマネージドインフラ越しに自動実行できます。
1.1 なぜ n8n の収集部分に Bright Data を使うのか
n8n 単体の HTTP Request ノードでも Web ページは取得できますが、本番運用では 403 / 429 の連発、JavaScript 未レンダリングによる空データ、Cloudflare などの Bot 防御で詰まります。Bright Data は 1.5 億超の Residential IP プールと Web Unlocker でこれらを吸収し、n8n のワークフロー側を単純なまま保てる点が最大の価値です。実際、n8n は公式アカウントで Bright Data 連携を発表しています。
「AI と Bright Data を組み合わせ、複数プラットフォームのプロフィールを検索・検証・分析して要約レポートを自動生成する」(原文意訳: n8n と Bright Data MCP + OpenAI で 360 度のソーシャルメディアレポートを生成するテンプレート)
1.2 想定ユースケース
- 競合価格モニタリング、レビュー・求人・不動産情報の継続収集
- SEO 順位の定期取得とスプレッドシートへの蓄積
- 新規リードのエンリッチメント (会社情報・SNS プロフィールの自動付与)
- ニュース・コンテンツの集約と Slack 通知
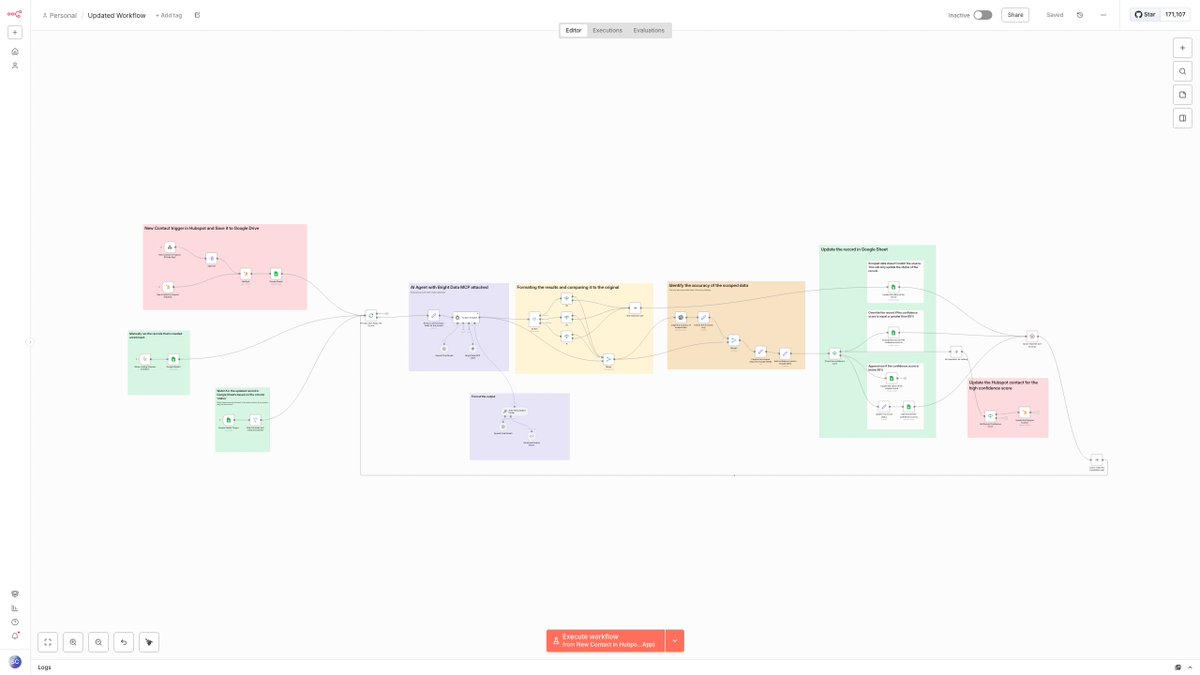
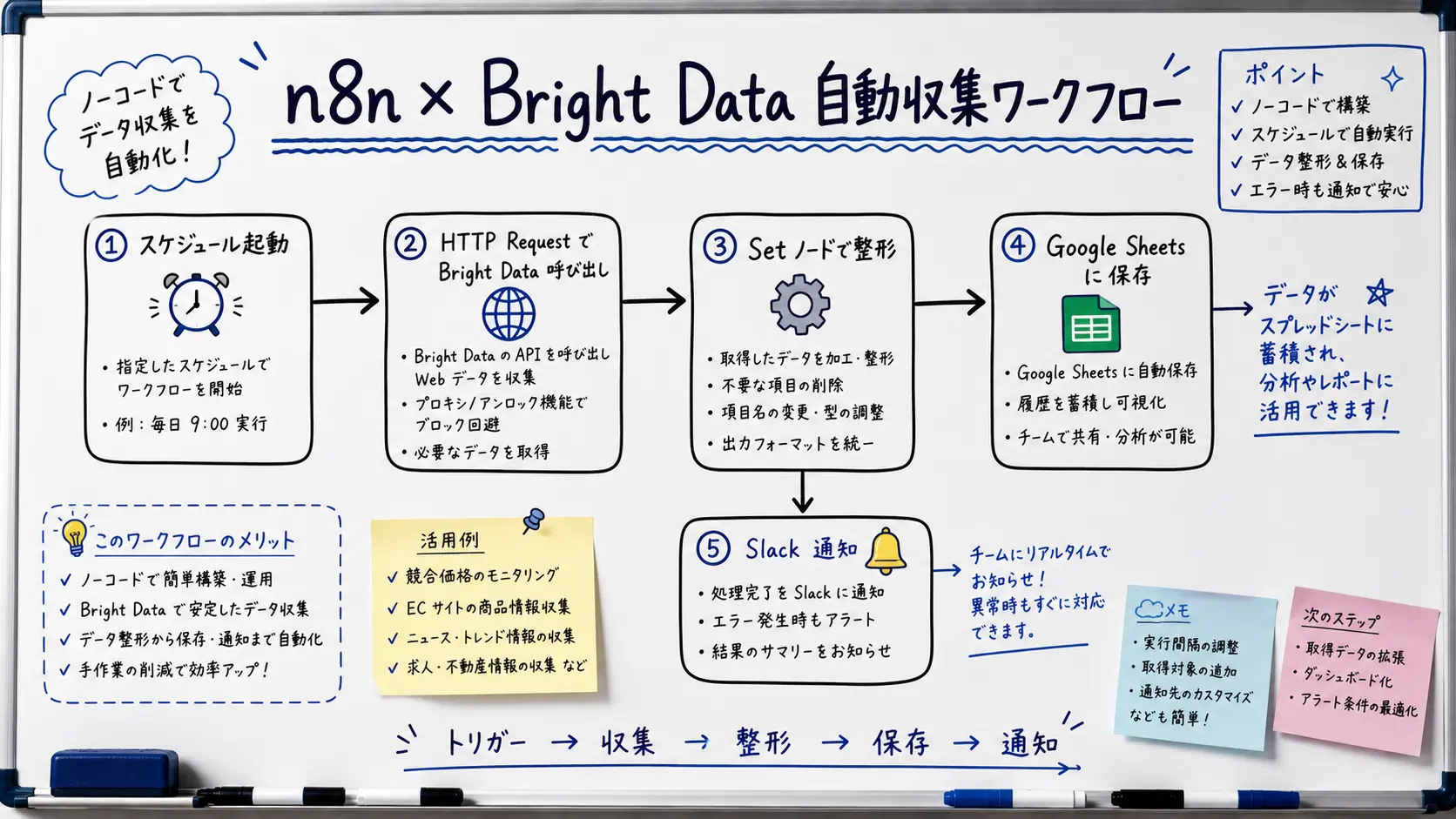
2. ワークフローの基本構成 (トリガー → 収集 → 整形 → 保存)
n8n × Bright Data のワークフローは、おおむね 5 つのブロックで構成されます。どれも標準ノードを線で繋ぐだけで組め、コードはほぼ不要です。
| ブロック | 使うノード | 役割 |
|---|---|---|
| トリガー | Schedule / Webhook / Form | 日次・時間指定・オンデマンドで起動 |
| 収集 | HTTP Request または AI Agent + Bright Data MCP | Bright Data 経由でデータ取得 |
| 整形 | Set / Edit Fields / IF / Item Lists | フィールド抽出・フィルタ・整形 |
| 保存 | Google Sheets / Postgres / Notion | 収集結果を蓄積 |
| 通知 | Slack / Gmail | 変化検知時のアラート |
次の図は、この一連の流れを 1 本のワークフローとして表したものです。
2.1 収集ブロックの 2 つのパターン
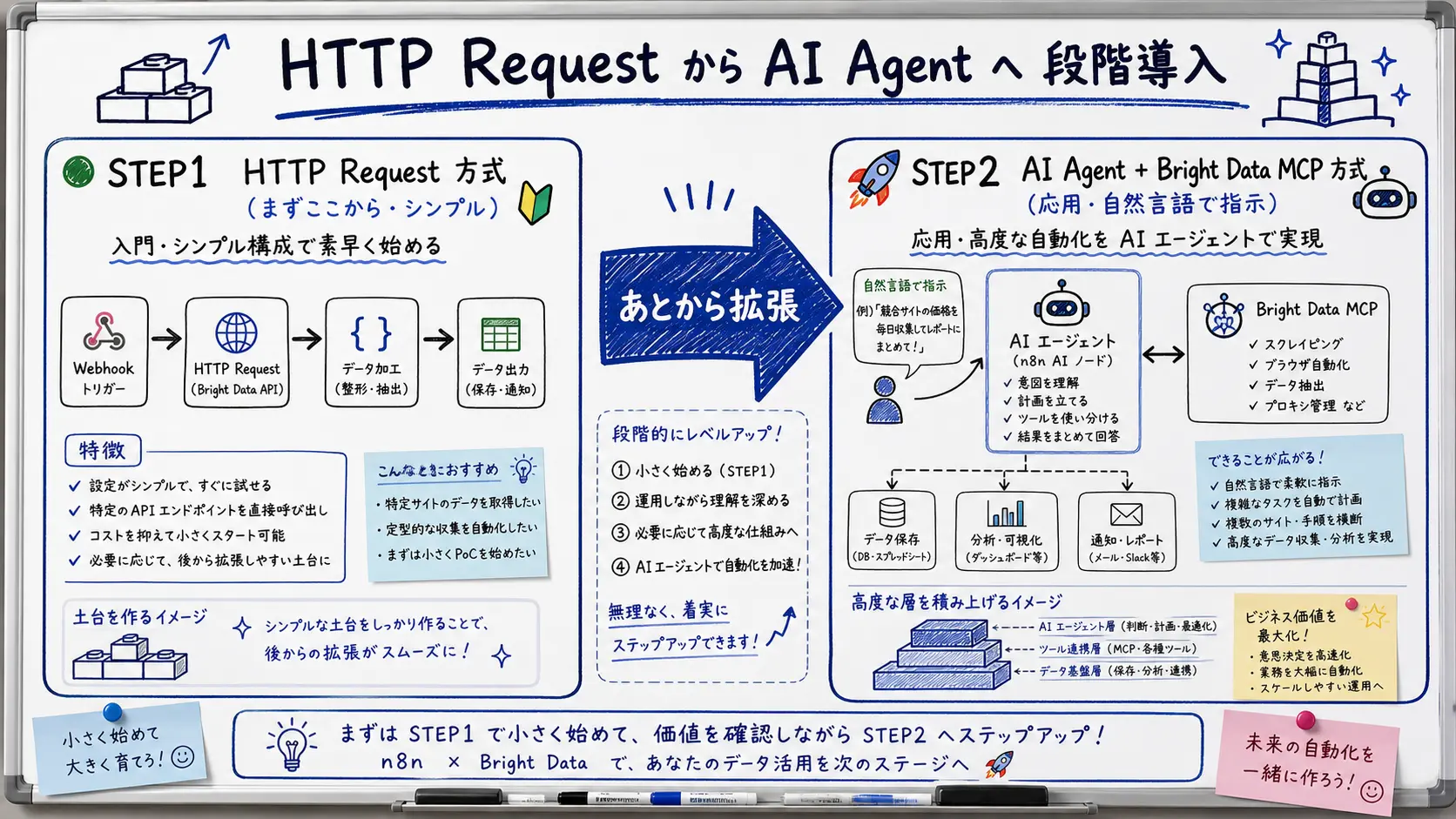
Bright Data の組み込み方は、大きく 2 通りあります。
- HTTP Request ノード方式: Web Unlocker / SERP API / Web Scraper のエンドポイントに直接リクエストを送る。構造化スクレイピング API を使えば、HTML を解析せずクリーンな JSON が返るため整形が楽です。
- AI Agent + Bright Data MCP 方式: n8n の AI Agent ノードに Bright Data MCP のツールを渡し、「これらの URL から価格・在庫を抽出して」と自然言語で指示する。ノード設定をさらに減らせます。
MCP を使った構成の詳細は Bright Data MCP サーバーで AI Agent にスクレイピングを任せる実践ガイド 2026 で解説しています。まずは HTTP Request 方式から始め、AI Agent 化は後から足すのが分かりやすい進め方です。
2.2 整形・保存ブロックの組み方
収集後は Set ノードで必要なフィールドだけを抜き出します。式の例は {{ $json.data.price }} のように、収集結果の JSON 構造を参照する形です。IF ノードで「前回より価格が下がったら」のような条件分岐を作り、Google Sheets ノードで行を追記、Slack ノードでアラートを送る、という流れが定番です。Webhook で結果を外部システムへ渡したい場合は、配信設計を Bright Data Webhook と Data Delivery 設計 2026 に整理しているので合わせて参照してください。
3. 競合価格モニタリングを 30 分で組む手順
もっとも需要の多い「競合の商品価格を毎日取得してシートに溜める」ワークフローを例に、最短手順を示します。HTTP Request 方式で組みます。
- Bright Data 管理画面でアクセストークンを発行し、Web Unlocker または Web Scraper の Zone を 1 つ作成する
- n8n の Credentials に Bright Data の API トークンを登録する (ワークフローに直書きしない)
- Schedule Trigger ノードを追加し、毎朝 9 時など実行タイミングを設定する
- Set ノードに監視対象の商品 URL リストを入れる
- HTTP Request ノードで Bright Data のエンドポイントを呼び、URL と取得したいフィールド (価格・在庫・レビュー数) を渡す
- Set / Item Lists ノードで返ってきた JSON を整形する
- Google Sheets ノードで行を追記し、IF ノードで価格下落を検知したら Slack ノードで通知する
この 7 ステップは、既存テンプレートを下敷きにすれば 30〜60 分で組めます。Bright Data の安定した取得基盤があるおかげで、無料スクレイパーにありがちな「ある日突然データが取れなくなる」事故を避けられるのが実利です。
3.1 API キーは n8n Credentials で守る
Bright Data の API トークンは、必ず n8n の Credentials 機能に登録します。ノードのパラメータや JSON エクスポートに直書きすると、ワークフローを共有・バージョン管理する際に漏洩します。Credentials に登録しておけば、ノードからは資格情報を参照するだけになり、トークン本体はエクスポートに含まれません。Zone ごとにトークンを分け、用途別に権限を絞るとさらに堅牢です。
4. 導入効果とコスト感
n8n × Bright Data の魅力は、運用コストの低さと安定性の両立です。n8n を自己ホストすれば本体は無料で、課金されるのは Bright Data のデータ収集分だけになります。
4.1 実際のコスト削減例
ユーザーからは、月 200 ドル超の専用ツールを、月 30 ドル程度の Bright Data 利用に置き換えたという報告も上がっています。
「月 200 ドル超かかっていたツールを、n8n と月 30 ドル程度の Bright Data 利用で置き換えられた。無料スクレイパーより圧倒的に安定している」(原文意訳)
Bright Data の料金は 2026 年 5 月時点で、Web Unlocker / SERP API が 1,000 リクエスト (1K Results) あたり 1.5 ドル前後 (PAYG。コミット契約で 1 ドル台まで)、Residential プロキシが 1GB あたり 8 ドル前後 (約 1,200 円/GB。PAYG、コミット契約で 5 ドル台まで下がる) が目安です1。構造化 API を使い、生 HTML 取得を減らすほどコストは下がります。最新の単価は Bright Data 料金プラン早見表 2026 と公式の料金ページで確認してください。
4.2 リードエンリッチメントのような応用
価格監視以外にも、HubSpot に新規リードが入ったら Bright Data で会社情報や SNS プロフィールを自動付与し、CRM を更新する、といった RevOps 用途も実例があります。
「新規 HubSpot リード → AI がツールを判断 → Bright Data MCP が LinkedIn / 企業情報 / メール検証を取得 → CRM を自動更新。手作業ゼロ」(原文意訳)
弊社では、Bright Data の Residential プロキシを使ったホテル価格追跡サービス Tra-bell を自社運用しています。n8n のようなワークフロー基盤と Bright Data を組み合わせた定期収集の設計・PoC・運用までは、要件次第でご相談いただけます。
5. 運用上の注意点と法令への配慮
ノーコードで手軽に組める一方、自動で繰り返し動くからこそガードレールは人間側で設計する必要があります。
- 取得対象の合法性: 対象サイトの利用規約と robots.txt を事前確認し、公開データのみを適法な範囲で取得する
- レート制御: Schedule の頻度と 1 回あたりのリクエスト数を抑え、対象サイトへ過負荷をかけない
- コスト上限: Bright Data 側で Zone ごとの月額キャップと利用アラートを設定し、ワークフローの暴走による請求増を防ぐ
- 個人情報: GDPR / 個人情報保護法 / CCPA など対象国の法令に配慮し、センシティブデータの収集は避ける
- エラー処理: n8n の Error Trigger で失敗時に通知し、リトライ設定で一時的な失敗を吸収する
これらを最初のワークフローに組み込んでおくと、後からの手戻りを大きく減らせます。
6. まとめ
n8n × Bright Data は、「公開 Web の定期収集をノーコードで、安定して、安く回す」ための実用解です。n8n を自己ホストすれば本体は無料で、課金は Bright Data の従量分のみ。HTTP Request 方式で土台を作り、必要に応じて AI Agent + MCP へ拡張していくのが分かりやすい進め方です。Bot 検知突破の精度と製品ラインの広さを踏まえると、ノーコード自動化基盤の収集レイヤとして Bright Data は有力な選択肢といえます。
※情報は 2026-05-31 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
Footnotes
-
Bright Data 公式料金ページ (2026 年 5 月時点): https://brightdata.com/pricing ↩
よくある質問
関連記事


Bright Data Webhook と Data Delivery 設計 2026 - S3 / BigQuery 連携