Bright Data Web Scraper IDE 入門ガイド 2026 - コレクター設計とコード雛形を実運用目線で解説
Bright Data Web Scraper IDE の 2026 年版ポジションと、navigate / parse / next_stage を軸にしたコレクター設計、Webhook 配信、OSS との使い分けまでを実運用の視点で整理します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
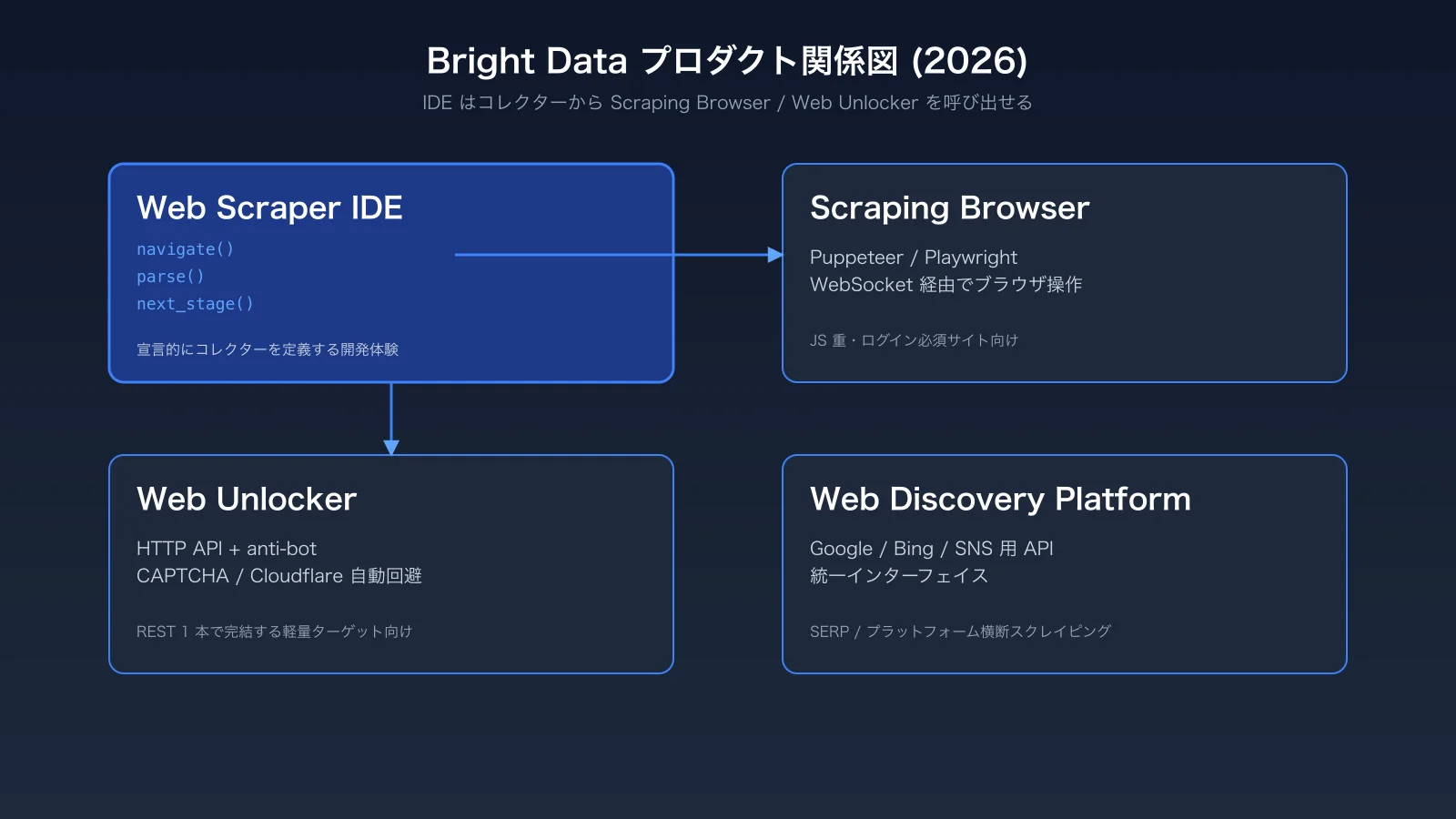
Bright Data の Web Scraper IDE は、ブラウザ上で navigate / parse / next_stage などの宣言的プリミティブを使ってコレクターを組み立てる SaaS 型 IDE です。2026 年の現在も健在ですが、Bright Data の主力は Scraping Browser と Web Discovery Platform に移っているため、IDE と他プロダクトの使い分けが要点になります。本記事では IDE の基本構造、初回セットアップ、コレクター雛形、運用上の落とし穴を弊社の実運用経験から整理します。
Web Scraper IDE の 2026 年ポジション
Bright Data の Web Scraper IDE は、もともとブラウザ完結型のスクレイパー開発環境として登場しました。2026 年時点では、より汎用な Scraping Browser や Web Discovery Platform が台頭していますが、IDE は 「コレクター単位で見積もり可能で、配信先まで Bright Data が面倒を見てくれる枠組み」 として残っています。
IDE が向くケースと向かないケース
| 向くケース | 向かないケース |
|---|---|
| 反復可能な多段クロール (一覧 → 詳細 → 注文情報) | 1 回限りの探索的データ取得 |
| 配信先 (Webhook / S3 / Snowflake) を Bright Data 側で完結したい | 自社パイプラインに細かく組み込みたい |
| 開発者以外も後から保守したい | アプリケーション側に深く統合したい |
| サイト構造が比較的安定 | サイトが頻繁にレイアウト変更される |
Bright Data 公式が掲げる「Web Discovery Platform」は、IDE のような開発体験に Google / Bing / 各種 SNS のデータを統一 API で被せたもので、AI エージェント文脈で利用者を伸ばしています。
このように、IDE は 継続収集が必要な対象を素早く Bright Data 側に載せる入口 として 2026 年も使われています。詳しいセットアップの前提は Bright Data アカウント作成と初期設定ガイド 2026 で先に整えてから IDE に進むのがおすすめです。
Scraping Browser や Web Unlocker との違い
navigate / parse / next_stage を IDE が提供するのに対し、Scraping Browser は Puppeteer / Playwright を WebSocket 経由で動かすブラウザ実体です。Web Unlocker は HTTP リクエスト単位の API で、いずれも Bright Data の anti-bot 突破レイヤーを共有しています。IDE のコレクター内部でも Scraping Browser や Web Unlocker を呼び出す形で連携できる のが現行の設計です。Scraping Browser の詳細は Bright Data Scraping Browser 実践活用ガイド 2026 で深掘りしています。
初回セットアップとコレクター作成手順
Web Scraper IDE は Bright Data ダッシュボードから数クリックで開けますが、課金まわりは押さえてから着手するほうが安全です。
アカウント前提と料金感
IDE 自体は無料で利用でき、課金は実行時の Scraping Browser / Web Unlocker / Residential Proxy の従量料金です。コミット契約 (月 $500〜) を結んでいなくても従量課金で開始できますが、本番運用では一定のコミットを切る方が単価が下がります。アカウント作成・KYC・支払い設定はあらかじめ済ませておきましょう。
新規コレクターを開く
- Bright Data ダッシュボードにログインし、左メニューの「Web Scrapers → Web Scraper IDE」を開く
- 「New collector」をクリックし、ターゲットサイトのプリセット (Amazon, Walmart, LinkedIn など) か「Custom」を選ぶ
- 出力先 (CSV / JSON / NDJSON) と配信モード (API / Webhook / S3 等) を決める
- IDE 上で
navigate/parse/collect/next_stageのブロックを記述する
プリセットは一覧・詳細・レビューなどの想定構造があらかじめ組まれているので、サイト固有のチューニングだけ書き換える形が最速です。Custom を選んだ場合も IDE 内部にスニペットライブラリがあり、navigate で URL を踏む / parse で CSS / XPath を取り出す / next_stage で次フェーズに遷移する、という流れに収まります。
コレクター雛形 (例)
擬似コード的に書くと、商品一覧から詳細を辿る最小構成は次のような流れになります。
navigate('https://example.com/list')で一覧ページを開くparseで各商品の URL を抽出collectで URL を次ステージに渡すnext_stage('detail')で詳細ページステージに移動- 詳細ステージで価格・在庫・レビュー件数などを
collect - 結果を配信先に送信
ここまで navigate / parse / collect / next_stage の 4 プリミティブで完結します。Scraping Browser を内部で呼び出すと CAPTCHA 突破や JS レンダリングを差し込めるため、レンダリング必須の SPA でも同じ枠組みで処理できます。Scraping Browser を本格的に組み合わせるなら Bright Data のドキュメントと Scraping Browser 単体記事を併用すると最短ルートで設計できます。
コードベースのコレクター設計と運用のコツ
IDE はブラウザ上で動きますが、長期運用するなら 「ローカルにエクスポートして Git で版管理する」 のが弊社の標準フローです。バージョン履歴と差分レビューを CI で回せるようにしておくと、サイト変更による壊れに対する初動が一段速くなります。
Step-by-Step: 価格モニタリング用コレクター
- ターゲット URL リストを Google Sheet 等で管理
- IDE で URL リストを
input.urlパラメータとして受け取るコレクターを作成 navigate(input.url)→parseで価格・在庫・URL を取り出すcollectでprice,currency,stock,url,timestampをスキーマ化- 配信先を Webhook (社内 API or Cloud Run) に設定
- スケジューラ (Bright Data 内蔵 or 外部 Airflow) で 1 日 4 回実行
このまま運用に乗せるとログが Bright Data ダッシュボードに溜まるため、失敗回数・1 件あたりのバイト数・実行時間の 3 つを必ずダッシュボード化しておきます。Webhook 受け取り側で BigQuery / Snowflake に流す設計は Bright Data Webhook と Data Delivery 設計 2026 を併読すると素早く決まります。
コスト最適化と弊社事例
帯域コストを抑えるには、画像・フォント・サードパーティ JS を IDE の block_resources パラメータで切るのが最も効きます。弊社では、ホテル価格追跡サービス Tra-bell を Bright Data の Residential Proxy と Scraping Browser の組み合わせで運用しており、画像ブロックと不要 JS の遮断だけで月次帯域を 30〜40% 抑制した実績があります。同様の構成は要件次第で PoC からの伴走支援が可能です。
「Scrapling などの adaptive スクレイパーは、サイトの構造変化に追従するため、保守工数を大きく下げられる」(原文の要旨)。Web Scraper IDE は依然として宣言的開発体験で優位ですが、サイト構造のドリフトが激しい対象には Scrapling のような OSS を組み合わせる選択肢があるという意見です。
トラブル対処とアンチパターン
IDE は便利ですが、サイト構造の変化や anti-bot の進化への追随を怠るとすぐに壊れます。よくある詰まりどころと対処を整理します。
構造変化で parse が壊れる
CSS セレクタ / XPath を直書きしていると、サイト改修で全コレクターが一斉に止まることがあります。対策は次の 3 つです。
- セレクタを変数化し、上部に一覧化しておく
- ステージごとに「成功率しきい値 (95% 等)」を IDE で設定して、しきい値割れで自動通知
- 構造差分検知 (Scrapling や自前 diff スクリプト) を別ジョブで回す
「Lightpanda は Zig で 1 から書いたヘッドレスブラウザで、Chromium ベースより 11 倍速い」(原文の要旨)。大量並列が必要な用途では、Bright Data の Scraping Browser に乗せる前にこうした軽量ブラウザで第一段を捌くハイブリッドも 2026 年では選択肢に入ります。
配信先の障害
Webhook / S3 / Snowflake への配信は基本的に Bright Data 側で再試行されますが、宛先側の認証情報失効や Snowflake のステージ権限漏れで止まるケースは少なくありません。Webhook 受信側で 2xx を必ず返し、収集失敗とは別に「配信失敗」のメトリクスを切っておくと切り分けが速くなります。
OSS との使い分け
サイトの防御強度が弱く、保守工数も自社で吸収できる場合は、Scrapling / Lightpanda / Playwright + stealth プラグインなどの OSS スタックも実用です。逆に、Cloudflare / DataDome / Akamai が掛かった対象を継続収集するなら、IDE と Scraping Browser を素直に使うのが TCO 最小という肌感覚です。
まとめ — IDE は「素早く collector を立ち上げる入口」
Bright Data Web Scraper IDE は、宣言的プリミティブで多段クロールを短く書け、配信まで一気通貫で組める SaaS 型 IDE です。2026 年でも有効ですが、複雑な anti-bot 突破は Scraping Browser、SERP や SNS は Web Discovery Platform に寄せて、IDE は「素早く collector を立ち上げる入口」として位置づけるのが最適解です。
サイト構造の安定性・防御強度・継続運用工数の 3 軸で IDE と OSS を使い分けると、コストと保守性のバランスが取りやすくなります。本番運用に近い PoC を 2〜4 週間でやり切る想定なら、IDE は最初の起点として優秀な選択肢です。
※情報は 2026-05-24 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
よくある質問
関連記事

Bright Data Scraping Browser 実践活用ガイド 2026 - Puppeteer/Playwright 統合とコスト設計