
Bright Data のリトライ戦略とレート制限設計ガイド 2026 - Exponential Backoff・Jitter・Circuit Breaker の実装
Bright Data のスクレイピング基盤で 429 や一時ブロックに遭遇したとき、Exponential Backoff・Jitter・Circuit Breaker・Retry-After ヘッダをどう組み合わせるか。Bright Data 層とターゲットサイト層の 2 階建てレート制限を分離して設計する実践ガイド。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
Bright Data でスクレイピング基盤を運用していると、429 Too Many Requests や 503 Service Unavailable、CAPTCHA 触発、一時的なネットワーク切断といった「リトライすれば通る」エラーに必ず遭遇します。何も考えずに即時リトライを繰り返すと、ターゲットサイトに迷惑をかけるだけでなく、Bright Data の帯域 (= 課金額) を浪費し、最終的にはアカウント側で警告がつく可能性もあります。本記事では、Bright Data の上で安定運用するための Exponential Backoff・Jitter・Circuit Breaker・Retry-After ヘッダ対応を、Bright Data 層とターゲットサイト層の 2 階建てとして整理し、Python 実装例まで踏み込んで解説します。結論を先に言えば、「Exponential Backoff + Full Jitter + Retry-After 尊重 + Circuit Breaker + デッドレターキュー」の 5 点セット が 2026 年時点の現実解です1。
なぜ Bright Data でも独自のリトライ設計が要るのか
Bright Data の Residential プロキシ・Web Unlocker・Scraping Browser は、IP 評価や bot 検知側の自動処理を内部に持っており、単体でも 429 や一時ブロックの発生率は他社プロキシより低い水準にあります。それでも呼び出し側で独自のリトライ設計が要るのは、Bright Data 側でハンドルできない上位層のレート制限が必ず存在するからです。
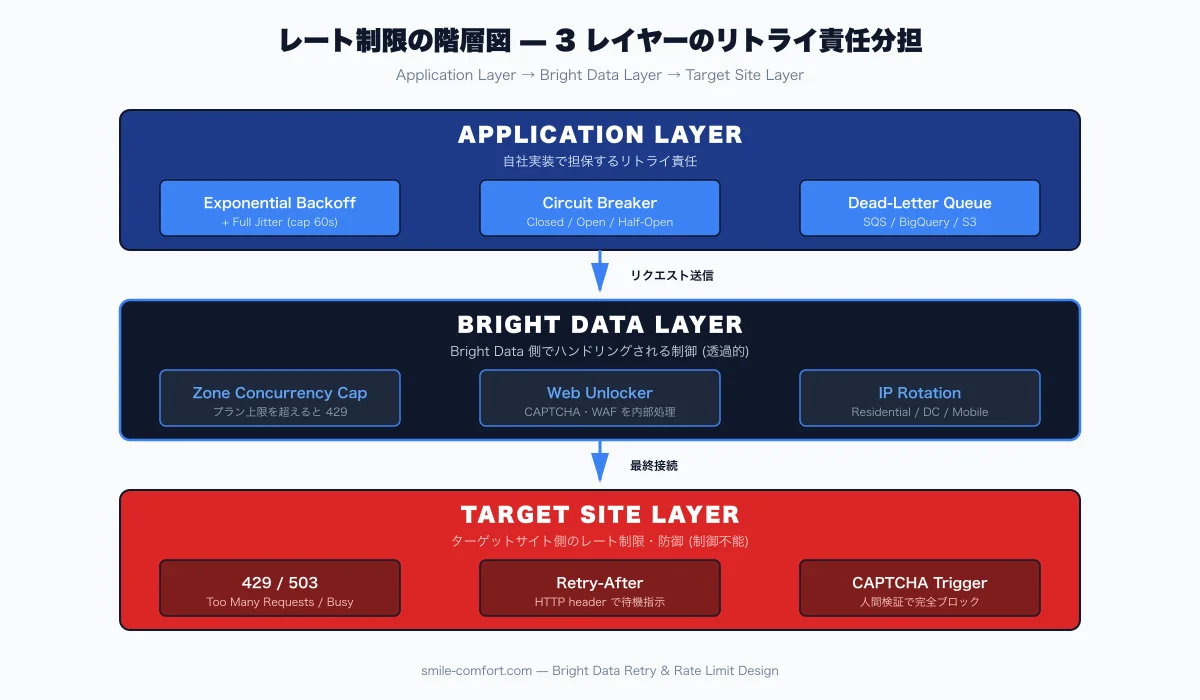
2 階建てのレート制限を分けて考える
スクレイピング基盤では、レート制限は最低でも 2 層で発生します。これを分離して設計しないと、片方の制限に過剰反応して全体が止まる、という事故が起きます。
- Bright Data 層のレート制限: Zone あたりの同時接続数上限、月次帯域上限、契約プラン上限。超過すると API が 429 を返す
- ターゲットサイト層のレート制限: 通常 HTTP 429 (Too Many Requests) や 503 Service Unavailable、または CAPTCHA 触発。アカウント単位 / IP 単位 / セッション単位で発火
Bright Data 層の 429 は「呼び出し方が間違っている」サインなので、即時バックオフではなく Zone の同時接続パラメータ見直しや契約プラン拡張で対応します。一方ターゲット層の 429 は「アクセスが多すぎる」サインなので、Exponential Backoff と IP ローテーションで対応します。同じ「429」でも対処方針が真逆なので、レスポンスのドメイン・URL から発生層を機械的に分類する仕組みを最初に入れます2。
Bright Data 製品ごとのリトライ責任分担
Bright Data の各製品は内部リトライ機能の有無が異なります。自分の製品が何をやってくれて何をやってくれないかを把握する ことが、二重リトライによる帯域浪費を避ける第一歩です。
| 製品 | 内部リトライ | アプリ層で必要な対策 |
|---|---|---|
| Residential / Datacenter Proxy | なし (純粋なトランスポート) | Exponential Backoff、IP ローテーション、Circuit Breaker |
| Web Unlocker | あり (CAPTCHA 自動処理含む) | 失敗時のみアプリ層で再試行 (1〜2 回まで) |
| Scraping Browser | あり (Stealth + 自動再試行) | タイムアウト管理、セッション再生成 |
| SERP API | あり (キャッシュ含む) | 429 時の Retry-After 尊重のみ |
Web Unlocker や SERP API のように内部リトライが効いている製品では、アプリ層で 5 回も 10 回も再試行すると 同じリトライを二重で走らせて課金が膨らむ ので、上限を 1〜2 回に絞り、デッドレターキュー送りの判断を早めるのが安全です。なお、Web Unlocker の Zone 設定で「Reject responses by HTTP status」に 429 と 503 を入れ忘れると、challenge ページや低品質レスポンスを成功扱いされて課金されるケースがあるので注意してください。詳しい Zone 設計は Bright Data Web Unlocker 実践活用ガイド 2026 で整理しています。
Exponential Backoff と Full Jitter の実装
ここからが本題です。リトライ間隔の設計は「サイトが回復する時間を与える」と「リトライストームを避ける」の 2 目的を同時に満たす必要があります。
Exponential Backoff の基本式
n 回目の試行 (1 始まり) の待ち時間は、次の式で計算します。
base * (2 ** (n - 1)) # 1, 2, 4, 8, 16, 32, 64...
base = 1 秒なら 1 / 2 / 4 / 8 秒と倍々で増えます。これだけだと、同じタイミングで失敗した複数クライアントが同じ秒数だけ待ち、同じタイミングで再リトライする「リトライストーム」が起きます。これを潰すのが Jitter です。
Full Jitter (推奨)
AWS Architecture Blog が 2015 年に提唱した「Full Jitter」が現在のデファクトで、計算式は次の通り。
sleep = random.uniform(0, base * (2 ** (n - 1)))
例えば 4 回目の試行は [0, 8] 秒の一様乱数になります。期待値は半減するが、リクエストが時間軸で完全に分散される ため、リトライストームの確率を実質ゼロにできます。Equal Jitter (base * 2^(n-1) / 2 + random(0, base * 2^(n-1) / 2)) という亜種もありますが、シンプルさと分散性能で Full Jitter が選ばれることが多いです3。
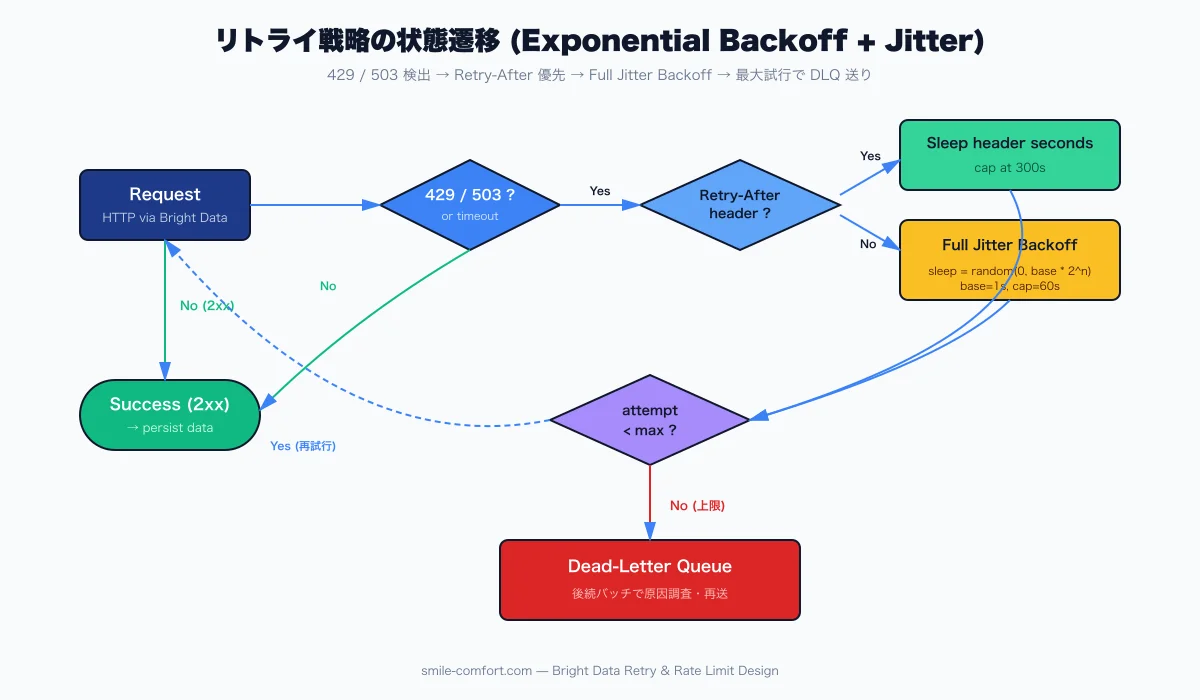
Retry-After ヘッダの優先
429 / 503 と一緒に Retry-After ヘッダが返ってきたら、Exponential Backoff の計算値ではなく ヘッダの値を優先 します。値の形式は秒数 (Retry-After: 30) または HTTP-date (Retry-After: Wed, 21 Oct 2026 07:28:00 GMT) の 2 通り。これを無視すると、Bright Data 側でも該当 Zone の評価が落ちる可能性があります4。
ただし極端に長い値 (例: 86400 = 24 時間) が返るケースは、サイト側で意図的にブロックされているサインなので、Exponential Backoff のループに戻さずデッドレターキューに送ります。
Python での実装例
実運用では tenacity ライブラリを使うのが最もシンプルです。
from tenacity import (
retry,
stop_after_attempt,
wait_exponential_jitter,
retry_if_exception_type,
)
import requests
from requests.exceptions import RequestException, HTTPError
import time
# Bright Data Residential proxy (Zone username/password)
BD_PROXY = "http://brd-customer-XXXX-zone-residential:pass@brd.superproxy.io:22225"
PROXIES = {"http": BD_PROXY, "https": BD_PROXY}
class RetryAfter(HTTPError):
"""Retry-After ヘッダ付き 429/503 を表す例外"""
@retry(
stop=stop_after_attempt(5),
wait=wait_exponential_jitter(initial=1, max=60, jitter=1.0),
retry=retry_if_exception_type((RequestException, HTTPError)),
reraise=True,
)
def fetch(url: str) -> requests.Response:
resp = requests.get(url, proxies=PROXIES, timeout=30)
if resp.status_code in (429, 503):
retry_after = resp.headers.get("Retry-After")
if retry_after and retry_after.isdigit():
wait = min(int(retry_after), 300)
time.sleep(wait)
raise RetryAfter(f"{resp.status_code} from {url}")
resp.raise_for_status()
return resp
wait_exponential_jitter(initial=1, max=60, jitter=1.0) が Full Jitter 相当の挙動で、initial * 2^attempt を上限 60 秒で打ち切り、それぞれにランダム加算します。tenacity を使わない手書き版でも、同じロジックを愚直に書くだけで動きます。
上記の X 投稿でも触れられているように、Exponential Backoff + Jitter は 2026 年時点で本番スクレイパーの「table stakes」(=最低限の標準) として扱われています。実装したかどうかではなく、適切なパラメータで動いているかが評価軸です。
Circuit Breaker とデッドレターキューで暴走を止める
Exponential Backoff だけだと、ターゲットサイトが本当に落ちている場合に最大リトライ回数まで延々と待ち続けてしまいます。これを早期に検知して止めるのが Circuit Breaker です。
Circuit Breaker の 3 状態
Circuit Breaker は次の 3 状態を遷移します。
- Closed (通常): リクエストを通す。失敗カウントが閾値超えで Open へ
- Open (遮断): リクエストを即時失敗にする。一定時間経過で Half-Open へ
- Half-Open (試験): 1 リクエストだけ試す。成功なら Closed、失敗なら Open に戻る
Python の pybreaker、Node.js の opossum、Go の gobreaker が代表的な実装です。Bright Data のスクレイピング基盤では ドメイン単位 または Zone × ドメイン単位 でブレーカーを 1 つずつ持たせるのが運用上の定石。同じ Zone で 5 連続失敗したらそのドメインを 5 分間遮断する、というオーダーで設定します。
import pybreaker
breaker = pybreaker.CircuitBreaker(
fail_max=5,
reset_timeout=300, # 5 分後に Half-Open
exclude=[RetryAfter], # Retry-After は失敗とカウントしない (サイト側の指示なので)
)
@breaker
def fetch_with_breaker(url):
return fetch(url)
exclude に RetryAfter を指定するのがポイントで、サイト側が「30 秒待って」と返しているのは異常ではなくレート制御の指示なので、ブレーカーの故障カウントには含めません。
デッドレターキューで失敗を切り離す
最大リトライ回数を超えた URL、Circuit Breaker が Open のままになり続けたドメイン、極端に長い Retry-After が返った URL は、本番ループから切り離してデッドレターキュー (DLQ) に送ります。SQS / Redis / BigQuery など何でも構いません。重要なのは 人間が後で確認できる粒度で URL・失敗理由・タイムスタンプ・Zone を残しておくこと。これがないと、なぜ取得失敗が増えたのかが原因不明のまま放置されます。
上記の X 投稿でも、リトライ無限ループを避けるためにデッドレターキューを必ず置くべきと触れられています。Bright Data の課金は帯域ベースなので、デッドレターキューを置かない設計は 「失敗するリクエストに永遠に課金される」 という最悪のコスト構造になります。
Bright Data の Zone と運用設計
リトライ戦略は、上位層 (アプリ) だけでなく Bright Data の Zone 設定とも揃える必要があります。Zone 側の設定をチューニングすると、アプリ層のリトライ回数を減らせて結果的にコストが下がります。
Zone 単位の同時接続数とプール設計
Bright Data Zone のダッシュボードで設定する Max concurrent requests は、契約プラン上限を超えないように設計します。これが小さすぎるとアプリ層から見ると「Bright Data 側で 429 が返る」状態になり、ターゲットサイト由来の 429 と区別できないままリトライループに入ります。
| 用途 | 推奨 Zone 同時接続 | 補足 |
|---|---|---|
| 軽量モニタリング (~1 万 req/日) | 5〜10 | 過剰だと月額帯域を一気に使う |
| 中規模スクレイピング (~10 万 req/日) | 20〜50 | 用途別に Zone を分割 |
| 大規模パイプライン (100 万 req/日 超) | 100〜500 | プラン拡張と帯域モニタリング必須 |
用途別の Zone 分割や同時接続の見積もり方は Bright Data Proxy Zone の設計と作成完全ガイド 2026 で詳しく解説しているので、Zone を初めて設計する場合は先にこちらを読んでおくとリトライ設計の前提が整います。
CAPTCHA と 429 の見分け方
レスポンスボディに g-recaptcha や __cf_bm などの指紋があれば、それは 429 ではなく CAPTCHA 触発です。CAPTCHA は Exponential Backoff では解決せず、Web Unlocker や Scraping Browser への切り替えで対処するのが正しいルートです。具体的な切り分け手順と Bright Data 製品の使い分けは Bright Data で CAPTCHA に遭遇したときの対処レシピ 2026 でレシピ化しています。リトライしても抜けない URL に出会ったら、まず CAPTCHA を疑う癖をつけておくと無駄な帯域消費を防げます。
サーバーレス基盤との組み合わせ
AWS Lambda などサーバーレスでスクレイピングを動かす場合、Lambda のタイムアウト (最大 15 分) と Exponential Backoff の上限を整合させます。例えば 5 回リトライで合計待ち時間が 1 + 2 + 4 + 8 + 16 = 31 秒程度に収まるよう設計し、それを超えたら DLQ に送る。サーバーレス側のリトライ (DLQ 連携、SQS の Visibility Timeout) と組み合わせた具体的な構成は AWS Lambda × Bright Data でサーバーレス スクレイピング基盤を構築する方法 2026 で実装例を整理しています。
弊社のスクレイピング支援と Tra-bell の事例
スマイルコンフォートは Bright Data の Residential / Web Unlocker / Scraping Browser を業務として運用してきた経験があり、Exponential Backoff + Circuit Breaker + DLQ を組み合わせたリトライ設計の伴走を提供しています。自社運用プロダクトの Tra-bell (ホテル価格追跡サービス) も Bright Data のスクレイピング基盤の上で動いており、リトライ重複を避ける設計と Zone 別の Circuit Breaker 配置で、月次の帯域コストを年単位で安定させてきました。
リトライ回数を増やしたら成功率は上がるが帯域コストも上がる、というジレンマに直面している案件は、Zone 同時接続数と Circuit Breaker の閾値を見直すだけで両方が改善するケースが多いです。コスト面での見直しポイントは Bright Data のコスト最適化テクニック 2026 でも整理しています。
まとめ
Bright Data でリトライ戦略を設計するときの肝は、(1) Bright Data 層とターゲットサイト層を分けて考える、(2) Exponential Backoff + Full Jitter を基本とし Retry-After ヘッダを優先する、(3) Circuit Breaker でドメイン単位の暴走を止める、(4) デッドレターキューで人間が確認できる経路を作る、の 4 点です。Web Unlocker や Scraping Browser を使う場合は内部リトライと二重にならないようアプリ層の上限を絞ることも忘れずに。リトライは「成功率を上げる手段」であると同時に「失敗したときの帯域消費を制御する手段」でもあるので、両方の観点で PoC 時にパラメータを測定してから本番に乗せましょう。
※情報は 2026-05-24 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
Footnotes
-
Bright Data official documentation — https://docs.brightdata.com/ ↩
-
MDN HTTP 429 Too Many Requests — https://developer.mozilla.org/docs/Web/HTTP/Status/429 ↩
-
AWS Architecture Blog "Exponential Backoff And Jitter" — https://aws.amazon.com/blogs/architecture/exponential-backoff-and-jitter/ ↩
-
RFC 9110 Retry-After header — https://datatracker.ietf.org/doc/html/rfc9110#name-retry-after ↩
よくある質問
関連記事


