
Bright Data Japan EC Data Pipeline Design Guide 2026
Design Japan EC product data pipelines with Bright Data Dataset and Web Scraper API: schema, diff detection, freshness, and cost levers in one guide.

This article contains affiliate links (advertising).
You have Bright Data pulling Japan EC data, but the next layer — loading it into your product master, detecting diffs, and keeping costs sane — is where most teams get stuck. Pairing Dataset Marketplace with Web Scraper API and designing schema, diff detection, and frequency tiers properly lets you keep 1,000 to 10,000 SKUs flowing reliably for a few hundred dollars a month. This guide walks through that pipeline design for Rakuten, Amazon.co.jp, and Yahoo!, grounded in how we operate Tra-bell on Bright Data in production today.
Why IP Infrastructure Alone Does Not Finish the Job
Most articles about Japan EC scraping focus on IP infrastructure: Residential vs Datacenter, Web Unlocker vs Scraping Browser. In production, those choices only cover about a third of the work. Once the bytes are in, the next 70% is the pipeline: schema normalization, diff detection, cadence tuning, and integration with downstream systems.
Failure Modes Below the IP Layer
- Inconsistent schema across marketplaces: Without normalizing Rakuten's
itemPrice, Amazon'sprice.value, and Yahoo!'sprice_intinto a single source-of-truth model, neither diff detection nor BI works - Dedup and gap handling: When the same product is listed by multiple sellers (Amazon multi-seller, Rakuten shop variants), you need a rule for which row wins
- Cadence mismatches: Rakuten reflects master updates immediately, Amazon has multi-hour lag. If crawl cycles and merge cycles do not align, you ship stale data thinking it is fresh
- Cost linearity: "All SKUs, every day, all marketplaces" pushes Web Unlocker spend up linearly, often 2-3x what you budgeted
- Validation and outlier suppression: Bot-suspect HTML responses, A/B-tested layouts, and partial blocks return parseable but wrong data. Without a validation layer (price-range guard, schema check, anomaly score), bad rows flow downstream silently
In production, the second-order issues — JSON schema drift, mall-specific edge cases, retry storms after a layout change — outweigh the IP question. A reliable pipeline budgets time for these from day one.
For the IP and product selection layer itself, see Bright Data for Rakuten, Amazon.co.jp, and Yahoo! Shopping 2026. This article picks up after that — the data pipeline layer.
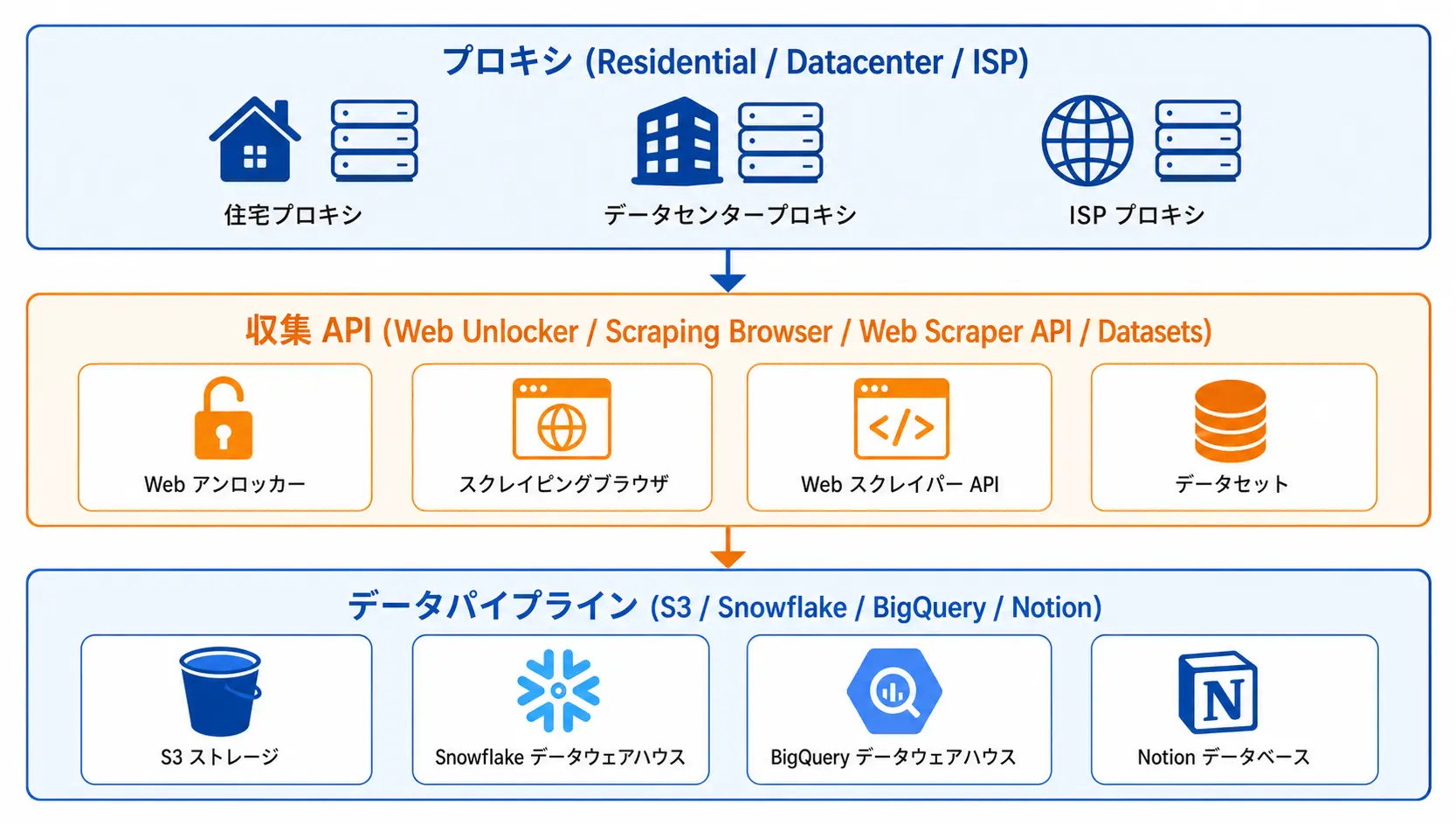
Where Dataset Marketplace and Web Scraper API Fit
Bright Data offers three families of data acquisition, each with different operational characteristics.
| Layer | Mode | Japan EC Use Cases |
|---|---|---|
| Proxy (Residential / DC / ISP) | Raw HTML through your own code | Detail extraction with custom parsers |
| Web Scraper API / IDE | Collector (template) returns JSON | Schema-fitting for semi-structured Rakuten / Yahoo! data |
| Dataset Marketplace | Buy pre-built datasets | Broad, lower-cadence Amazon catalog or benchmarking |
A practical Japan EC pipeline pushes parsing toward Bright Data ("if a template exists, use it"), keeps Python focused on flowing parsed data into business systems, and reserves raw proxy work for the long tail. This is cheaper and reduces ongoing maintenance.
Source-of-Truth Schema and Product ID Design
The pipeline's center of gravity is a normalized cross-marketplace schema. Raw JSON from each marketplace has its own shape, so you always insert a staging layer that maps them onto common keys and types.
Example Cross-Marketplace Schema
| Column | Type | Purpose | Sample Source |
|---|---|---|---|
mall_code | string | rakuten / amazon-jp / yahoo-shopping | Added at fetch time |
mall_item_id | string | Rakuten item code / ASIN / Yahoo! code | Per-marketplace ID |
sku_global_id | string | Unified ID we assign (JAN + ASIN hash, etc.) | Generated by pipeline |
title | string | Product name (raw, display use) | itemName / title / name |
price | int | Tax-inclusive price (JPY) | itemPrice / price.value / price_int |
stock_status | enum | in_stock / low / out | Normalized from each mall |
category_path | string[] | Hierarchical category | genreId resolved / Browse Node |
attributes | jsonb | Semi-structured attributes (color, size, capacity) | Stored raw per mall |
crawled_at | timestamp | Fetch timestamp | Added at fetch time |
payload_hash | string | Hash of key columns | For diff detection |
Always Define sku_global_id
mall_item_id alone cannot tie the same product across Amazon (ASIN) and Rakuten (item code). Define sku_global_id separately and downstream master sync and ranking aggregations get dramatically easier. Practically, JAN codes are the first choice; when missing, fall back to a normalized-title plus key-attributes hash. Track the resolution method per row so analysts know whether a join is exact or fuzzy, and budget review cycles to inspect low-confidence groupings before they corrupt downstream metrics.
Handling Semi-Structured Attributes
Rakuten and Yahoo! taxonomies have thousands of branches; Amazon Browse Nodes go just as deep. Normalizing every attribute up front is unrealistic. Store the raw payload in attributes (jsonb) and let consumers select only the keys they care about. If you need to map Rakuten or Yahoo! categories to a clean taxonomy downstream, AI-based completion approaches like our CataMap offer one route worth evaluating.
Versioning and Backfill Strategy
Schemas change because marketplaces change. When Amazon Browse Node IDs reshuffle or Rakuten introduces a new attribute, your staging layer needs a versioned schema, not an in-place mutation. Store every fetched row with a schema_version column and gate downstream consumers by version. Backfilling old data with a new mapping is then a controlled operation rather than a cascade of failed rebuilds. For BigQuery or Snowflake sinks, append-only history tables make backfills almost free.
Building the Fetch Layer With Web Scraper API
Web Scraper API runs Collectors on Bright Data's side and returns JSON. A request kicks off the async job, you poll for completion, then download the result. This is well suited to queue-driven architectures.
Fetch Flow (Pseudo Code)
import os
import time
import httpx
BD_TOKEN = os.environ["BD_TOKEN"]
COLLECTOR_ID = "<collector_id>" # Per marketplace (Rakuten, Amazon, etc.)
def trigger_collect(items: list[dict]) -> str:
"""Submit a list of input items and return a snapshot_id."""
res = httpx.post(
f"https://api.brightdata.com/dca/trigger?collector={COLLECTOR_ID}",
headers={"Authorization": f"Bearer {BD_TOKEN}"},
json=items,
timeout=30.0,
)
res.raise_for_status()
return res.json()["snapshot_id"]
def fetch_result(snapshot_id: str) -> list[dict]:
"""Poll until ready, then return the JSON array."""
for _ in range(60):
s = httpx.get(
f"https://api.brightdata.com/dca/snapshot/{snapshot_id}?format=json",
headers={"Authorization": f"Bearer {BD_TOKEN}"},
timeout=30.0,
)
if s.status_code == 200:
return s.json()
time.sleep(10)
raise TimeoutError("snapshot not ready")
Because trigger and fetch are split, you can drop the trigger step into a queue (SQS, Cloud Tasks) and run the fetch step in a separate worker. Lambda and Cloud Run runtime limits stop being a constraint. For the serverless side of this architecture, see AWS Lambda x Bright Data: Serverless Scraping Pipeline 2026.
Per-Marketplace Collector Notes
Rakuten
- Official Collectors are limited; you typically build selectors in the Web Scraper IDE starting from
item.rakuten.co.jp/<shop>/<itemId>/ - Capture: product name, price, stock label, shop ID, image URL, review count, category ID
- Where Rakuten RMS or the Rakuten Web Service provides the data via API, prefer the API and use scraping only for ranking pages and search-result-only fields
Amazon.co.jp
- Official Collectors are mature (product detail, search, reviews, bestsellers)
- Feed ASINs and JSON comes back — usually no custom parser needed
- Prices and stock can move on a minute scale, so it can make sense to run hot SKUs 2 to 4 times a day
Yahoo! Shopping
- Fewer official Collectors than Rakuten; expect more IDE work
- PayPay Mall items mingle with Yahoo! Shopping — segment by
store_idto make downstream aggregation cleaner - For fields exposed by the Yahoo! Shopping Web API, use the API first
On X, DifyJapan has shared examples of plugging Bright Data Web Scraper into Dify as a knowledge source.
"Built an Amazon product scraper with n8n and Bright Data — surprisingly low maintenance" (Original: n8n と Bright Data を使えば、ローコードで Amazon の商品データを継続的に集められる)
n8n is commonly used to call Web Scraper API on a cron trigger and dump results into Google Sheets, Notion, or Postgres. Either Dify or n8n works well as the orchestration layer for non-engineer operators, and lets product or marketing teams adjust schedules and retry rules without touching engineering tickets.
Diff Detection and Refresh Cadence
A pipeline's real value shows up when it only propagates what changed, not the whole catalog every day. This drops downstream API calls, DB writes, and notification spam by an order of magnitude.
Hash-Based Diff Detection
import hashlib
import json
def payload_hash(item: dict) -> str:
"""Stable hash from price, stock, ranking, and headline attributes."""
sig = {
"price": item["price"],
"stock_status": item["stock_status"],
"ranking": item.get("ranking"),
"title": item["title"],
}
payload = json.dumps(sig, sort_keys=True, ensure_ascii=False)
return hashlib.sha256(payload.encode("utf-8")).hexdigest()
Persist payload_hash per fetched row and short-circuit "no change" rows by comparing against the previous hash. You do not need elaborate diff logic — a hash match is enough operational signal for almost every case.
Tiered Refresh Cadence
| Target | Recommended Cadence | Relative Cost |
|---|---|---|
| Hot price/stock monitoring SKUs (50-200 items) | 4-8 times per day | 100% (baseline) |
| Standard SKUs (500-2,000 items) | Once per day | 30-50% |
| Long tail (5,000-tens of thousands) | Once per week | 5-10% |
| Category listings, rankings | 1-2 times per day | 10-20% |
Moving from "all SKUs once a day" to a tiered cadence typically cuts Bright Data request volume by 40-60%. ABC analysis on sales is a stable way to assign tiers.
Propagating Changes Downstream
After diff detection, the question becomes "where does the change go?" Common sinks and patterns:
- Product master DB (Postgres / MySQL): Upsert with a strict
updated_atcolumn - BI / analytics (BigQuery / Snowflake): Append-only history table, view picks latest row per SKU
- Slack / email alerts: Threshold rules like price change of 10% or more
- OMS (Japanese ecommerce order management systems): Sync via product master update API. If you need cross-mall taxonomy resolution, an AI completion layer like CataMap fits between
Idempotency and Replay Safety
A pipeline that cannot be replayed safely is a future incident. Make every transformation step idempotent — same input always yields same output, repeats are no-ops. The (mall_code, mall_item_id, crawled_at) triple is a strong natural key, and downstream merges should use it for dedup. When you need to re-process a day's data after a schema fix, you should be able to point the orchestration tool at the date range and let it replay without manual cleanup.
Cost Optimization and Where We Help
Total pipeline cost is the sum of fetch (Bright Data), processing (Lambda / Cloud Run), and storage (S3 / BigQuery). Bright Data usually dominates the bill, so that is the lever with the most leverage.
Five Practical Cost Levers
- Tiered cadence: Stop crawling everything daily. Split hot and standard SKUs
- Reuse Collectors: One Collector per marketplace category, push variation into runtime parameters
- Limit Web Unlocker: Use Web Scraper API for structured data and reserve Web Unlocker for retries on failures
- Archive snapshots to S3: Cold-store after 30 days so reruns do not re-bill Bright Data
- Avoid weekday-morning spikes: Marketplaces are noisier then; off-peak windows reduce retry waste
The broader pricing structure is covered in Bright Data Pricing Cheat Sheet 2026.
Monitoring and Budget Alerts
Without active monitoring, Bright Data spend climbs quietly. Track three metrics in your observability stack: success rate per Collector, bytes per fetch, and snapshots per hour. Set budget alerts at 70% and 90% of the monthly cap with Slack notifications, and make the pipeline degrade gracefully when limits approach — drop long-tail SKUs first, keep the hot tier flowing. We also recommend a weekly cost review where you compare yield (rows landed in the warehouse) to spend; the ratio should stay stable or improve.
We run our own hotel price tracking product Tra-bell on Bright Data using Residential, Web Unlocker, and Web Scraper API, and we operate the full pipeline — normalization, diff detection, and downstream integration. We can engage on similar Japan EC data pipeline projects depending on requirements.
Wrap Up
For Japan EC data pipelines, the bottleneck is not the IP layer — it is the post-fetch design: normalized schema, hash-based diff detection, tiered refresh cadence, and disciplined monitoring. Combining Dataset Marketplace with Web Scraper API makes 1,000 to 10,000 SKU pipelines comfortable at a few hundred dollars per month, leaves your engineers focused on business logic instead of parser maintenance, and gives downstream systems clean, versioned data they can trust. The structure here mirrors how we operate Tra-bell. If you are getting stuck early, talk to a specialist before you have to refactor.
Information current as of 2026-05-21. Please check the official sites for the latest updates.
This article contains affiliate links.
Frequently asked questions
Related articles

Bright Data for Rakuten, Amazon.co.jp, and Yahoo! Shopping 2026: A Practical Scraping Guide

Bright Data Residential Proxy for Price Monitoring: A How-To
