
Bright Data Retry Strategy & Rate Limit Design 2026: Exponential Backoff, Jitter, and Circuit Breakers
How to handle 429s, transient blocks, and CAPTCHA fallback on a Bright Data scraping stack with exponential backoff, full jitter, circuit breakers, and Retry-After headers. Separates Bright Data layer rate limits from target-site rate limits.

This article contains affiliate links (advertising).
Any Bright Data scraping stack run long enough will encounter 429 Too Many Requests, 503 Service Unavailable, transient CAPTCHA challenges, and short network outages — the kinds of errors that "go away if you retry". Naive immediate retries hurt the target site, burn through your Bright Data bandwidth budget, and eventually attract account warnings. This guide lays out an exponential backoff, jitter, circuit breaker, and Retry-After pattern for Bright Data workloads, separating Bright Data layer rate limits from target-site rate limits and walking through Python examples. The short version: in 2026, the realistic default is exponential backoff with full jitter, Retry-After honored, a circuit breaker per domain, and a dead-letter queue for stragglers1.
Why You Still Need a Retry Layer on Bright Data
Residential proxies, Web Unlocker, and Scraping Browser all include IP reputation tuning and automated bot-handling under the hood, so 429s and transient blocks are less frequent than on commodity proxies. You still need an explicit retry layer because rate limits at higher layers (where Bright Data has no visibility) keep happening.
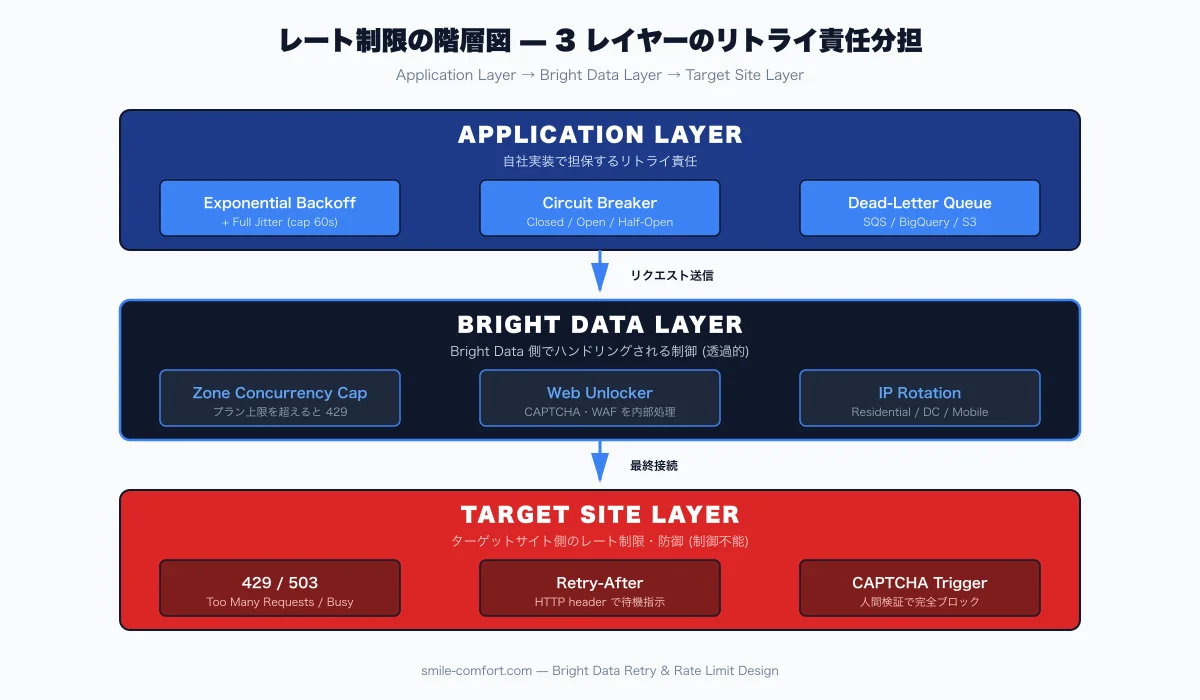
Treat Rate Limits as a Two-Tier System
A scraping stack carries rate limits at no fewer than two layers, and you have to separate them in code. Conflating the two means a single problem trips both layers and the whole pipeline halts.
- Bright Data layer: per-Zone concurrent connections, monthly bandwidth caps, plan-level quotas. Exceeding these returns a 429 from the Bright Data API itself.
- Target-site layer: usually HTTP 429 (Too Many Requests) or 503 Service Unavailable, sometimes a CAPTCHA challenge. Fires per account, per IP, or per session.
A Bright Data 429 means "you are calling us wrong" — the fix is concurrency settings or a plan upgrade, not exponential backoff. A target-site 429 means "you are accessing me too aggressively" — the fix is exponential backoff plus IP rotation. The same status code maps to opposite responses, so you need a classifier that inspects the response domain and URL to decide which tier triggered it2.
Map Retry Responsibility to Each Bright Data Product
Bright Data products differ in how much retry logic they handle internally. Knowing what each product already does for you is the first step to avoiding double-retries that quietly double your bandwidth bill.
| Product | Internal retry | What you must add at the app layer |
|---|---|---|
| Residential / Datacenter Proxy | None (pure transport) | Exponential backoff, IP rotation, circuit breaker |
| Web Unlocker | Yes (includes CAPTCHA handling) | Limit app-layer retries to 1-2 attempts |
| Scraping Browser | Yes (Stealth + auto retry) | Timeout management, session regeneration |
| SERP API | Yes (includes caching) | Honor Retry-After on 429 |
When the product already retries internally — Web Unlocker, SERP API — running 5 or 10 application-level retries on top doubles every retry and inflates billing. Cap the outer layer at 1 to 2 attempts and let the dead-letter queue catch the rest. Also, on Web Unlocker Zones make sure "Reject responses by HTTP status" includes 429 and 503; otherwise challenge pages and degraded responses count as billable successes. The full Zone configuration is covered in the Bright Data Web Unlocker Practical Guide 2026.
Implementing Exponential Backoff With Full Jitter
This is the core of the design. Retry timing has to satisfy two goals at once: give the target site time to recover, and avoid synchronizing retries across clients.
The Base Formula
Wait time for the nth attempt (1-indexed) is:
base * (2 ** (n - 1)) # 1, 2, 4, 8, 16, 32, 64...
With base = 1 second you get 1, 2, 4, 8 seconds. Used alone, every client that failed at the same moment sleeps the same number of seconds and retries at the same moment — a synchronized "retry storm". Jitter solves this.
Full Jitter (Recommended)
The Full Jitter pattern, popularized by the AWS Architecture Blog in 2015, is now the de facto default:
sleep = random.uniform(0, base * (2 ** (n - 1)))
The fourth attempt picks uniformly from [0, 8] seconds. The expected wait halves, but requests get fully spread across the time axis, dropping the retry-storm probability to effectively zero. There is also Equal Jitter (base * 2^(n-1) / 2 + random(0, base * 2^(n-1) / 2)), but Full Jitter wins on simplicity and distribution3.
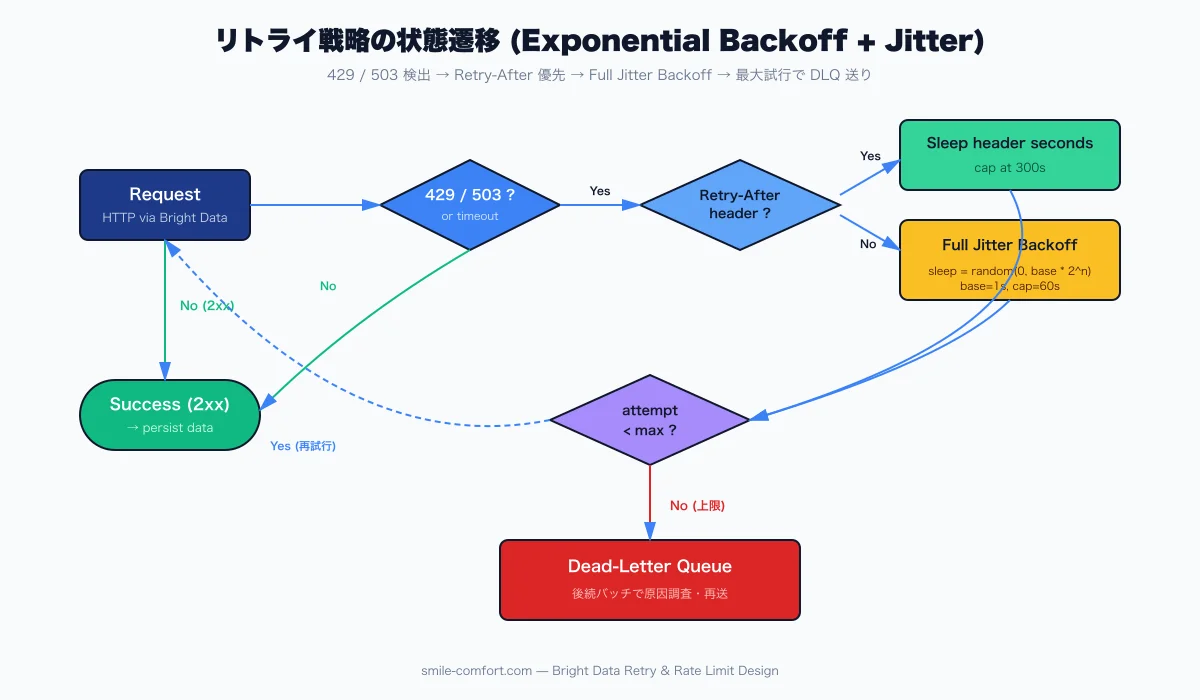
Honor the Retry-After Header
When a 429 or 503 arrives with a Retry-After header, the header value beats your backoff math. Two formats exist: a delta-seconds value (Retry-After: 30) or an HTTP-date (Retry-After: Wed, 21 Oct 2026 07:28:00 GMT). Ignoring it can degrade your Zone's reputation on Bright Data's side as well4.
If you receive an absurdly long value (86400 = 24 hours), treat it as an intentional block signal — do not loop, send the URL to the dead-letter queue for human inspection.
Python Reference Implementation
In production, tenacity is the cleanest choice.
from tenacity import (
retry,
stop_after_attempt,
wait_exponential_jitter,
retry_if_exception_type,
)
import requests
from requests.exceptions import RequestException, HTTPError
import time
# Bright Data Residential proxy (Zone username/password)
BD_PROXY = "http://brd-customer-XXXX-zone-residential:pass@brd.superproxy.io:22225"
PROXIES = {"http": BD_PROXY, "https": BD_PROXY}
class RetryAfter(HTTPError):
"""429/503 with a Retry-After header."""
@retry(
stop=stop_after_attempt(5),
wait=wait_exponential_jitter(initial=1, max=60, jitter=1.0),
retry=retry_if_exception_type((RequestException, HTTPError)),
reraise=True,
)
def fetch(url: str) -> requests.Response:
resp = requests.get(url, proxies=PROXIES, timeout=30)
if resp.status_code in (429, 503):
retry_after = resp.headers.get("Retry-After")
if retry_after and retry_after.isdigit():
wait = min(int(retry_after), 300)
time.sleep(wait)
raise RetryAfter(f"{resp.status_code} from {url}")
resp.raise_for_status()
return resp
wait_exponential_jitter(initial=1, max=60, jitter=1.0) behaves like Full Jitter — initial * 2^attempt capped at 60 seconds, with random padding. A hand-rolled version using random.uniform and a for loop works the same way if you want to avoid the dependency.
As the X post above puts it, exponential backoff with jitter is "table stakes" for production scrapers in 2026. The judgment call is no longer whether to implement it — it is whether your parameters match your traffic profile.
Stop Runaways With Circuit Breakers and Dead-Letter Queues
Exponential backoff alone keeps retrying until the cap. If the target is genuinely down for an hour, you will burn bandwidth waiting. Circuit breakers catch this case early.
The Three Circuit Breaker States
A circuit breaker transitions through three states.
- Closed (normal): requests pass through. After N failures in a row, trip to Open.
- Open (tripped): requests fail fast. After the cooldown, transition to Half-Open.
- Half-Open (probing): one trial request is allowed. On success, return to Closed; on failure, back to Open.
pybreaker (Python), opossum (Node.js), and gobreaker (Go) are the canonical implementations. For Bright Data scraping, the operational pattern is one breaker per domain — or per Zone-by-domain pair. A reasonable starting point: 5 consecutive failures in the same Zone for the same domain trips the breaker for 5 minutes.
import pybreaker
breaker = pybreaker.CircuitBreaker(
fail_max=5,
reset_timeout=300, # 5-minute cooldown before Half-Open
exclude=[RetryAfter], # Retry-After is the site's instruction, not a fault
)
@breaker
def fetch_with_breaker(url):
return fetch(url)
The exclude=[RetryAfter] line is important: a Retry-After response is the site's rate limiting working as intended, not a fault. It should not count toward the breaker's failure tally.
Use a Dead-Letter Queue to Quarantine Failures
URLs that exceeded the retry cap, domains where the breaker keeps re-tripping, and responses with extreme Retry-After values all need to leave the main loop and enter a dead-letter queue (DLQ). SQS, Redis, or BigQuery all work. The non-negotiable part is recording URL, failure reason, timestamp, and Zone at a granularity humans can audit later. Without that, increases in failure rate stay unexplained.
The X post above echoes the same point: never retry forever. Bright Data billing is bandwidth-based, so a design without a DLQ is a design where doomed requests get billed for eternity.
Aligning With Bright Data Zones and Operations
The retry layer has to align with Zone-side settings, not just with application code. Tuning the Zone first lets you reduce application-layer retries and lower your bill at the same time.
Per-Zone Concurrency and Pool Sizing
Bright Data's Max concurrent requests setting per Zone should sit comfortably below the plan ceiling. Too low and your app sees Bright Data return 429s — which look identical to target-site 429s if you do not classify by domain, sending the retry loop into a dead end.
| Workload | Recommended Zone concurrency | Notes |
|---|---|---|
| Light monitoring (~10K req/day) | 5-10 | Higher values waste monthly bandwidth quickly |
| Mid-scale scraping (~100K req/day) | 20-50 | Split Zones by use case |
| Large pipeline (1M+ req/day) | 100-500 | Plan upgrade and bandwidth monitoring required |
Use-case Zone splitting and concurrency sizing are covered in detail in the Bright Data Proxy Zone Design and Setup Guide 2026; skim that one first if you have not designed Zones yet, because the retry design assumes the Zone layout is already sensible.
Distinguishing CAPTCHA From 429
If the response body contains fingerprints like g-recaptcha or __cf_bm, it is a CAPTCHA trigger, not a 429. Exponential backoff will not help; you need to switch to Web Unlocker or Scraping Browser. Triage and per-product allocation patterns are documented in the Bright Data CAPTCHA Handling Playbook 2026. When retries fail to break through, suspect CAPTCHA first — it saves the bandwidth you would otherwise spend banging on a challenge page.
Serverless Integration
When you run scrapers in AWS Lambda or similar, align the Lambda timeout (max 15 minutes) with your backoff cap. A 5-retry policy that totals 1 + 2 + 4 + 8 + 16 = 31 seconds of wait fits comfortably; anything beyond that should go to the DLQ. End-to-end serverless wiring (DLQ integration, SQS visibility timeout) is laid out in the AWS Lambda x Bright Data: Serverless Scraping Pipeline 2026.
Our Scraping Support and the Tra-bell Case
We operate Bright Data Residential, Web Unlocker, and Scraping Browser in production and can help design exponential backoff plus circuit breaker plus DLQ retry stacks for your team. Our hotel price tracking service Tra-bell runs on top of Bright Data scraping infrastructure, where avoiding double-retries and tuning per-Zone circuit breakers has kept monthly bandwidth costs predictable for years.
If you are stuck choosing between "more retries to lift success rate" and "fewer retries to control spend", the answer is usually neither — it is tuning concurrency and breaker thresholds. The cost angle of this tradeoff is covered in the Bright Data Cost Optimization Guide 2026.
Wrap-Up
Designing retries on Bright Data comes down to four moves: (1) separate Bright Data layer rate limits from target-site rate limits, (2) use exponential backoff with full jitter and let Retry-After preempt your math, (3) wrap each domain with a circuit breaker to stop runaways, (4) attach a dead-letter queue so failures stay auditable. With Web Unlocker or Scraping Browser, cap application-layer retries at 1 to 2 to avoid double-retrying. Retry logic is as much about controlling failure-mode bandwidth as it is about raising success rates — measure both during PoC before locking the parameters into production.
Information current as of 2026-05-24. Please check the official sites for the latest updates.
This article contains affiliate links.
Footnotes
-
Bright Data official documentation — https://docs.brightdata.com/ ↩
-
MDN HTTP 429 Too Many Requests — https://developer.mozilla.org/docs/Web/HTTP/Status/429 ↩
-
AWS Architecture Blog "Exponential Backoff And Jitter" — https://aws.amazon.com/blogs/architecture/exponential-backoff-and-jitter/ ↩
-
RFC 9110 Retry-After header — https://datatracker.ietf.org/doc/html/rfc9110#name-retry-after ↩
Frequently asked questions
Related articles

Bright Data CAPTCHA Handling Playbook 2026: Recipes by Challenge Type

AWS Lambda x Bright Data: Serverless Scraping Pipeline 2026
