Scrapy × Bright Data 連携実装ガイド 2026 - プロキシ設定からゾーン選択・大規模並行クロールまで
Scrapy に Bright Data を組み込む実装を、settings.py のプロキシ設定・DownloaderMiddleware・ゾーン選択・IP ローテーション・Web Unlocker 併用まで、動くコード片とコスト設計込みで解説します。

本記事にはプロモーション(アフィリエイトリンク)が含まれます。
Scrapy は強力なクローリングフレームワークですが、単体で大規模に走らせると IP BAN・CAPTCHA・レート制限という壁に必ずぶつかります。本記事では、Scrapy プロジェクトに Bright Data を組み込み、これらの壁を解消する実装を解説します。settings.py のプロキシ設定から、独自 DownloaderMiddleware、Residential / Datacenter のゾーン選択、IP ローテーション、Web Unlocker 併用、そして大規模並行クロールの設計までを、最小限の動くコード片とコスト設計込みで順に追います。
Scrapy 単体の限界と Bright Data で解消できること
Scrapy は Twisted ベースの非同期クローラーで、数千 URL の並行取得を 1 プロセスで捌けます。しかし、取得元のサーバーから見ると「同一 IP から短時間に大量アクセスが来る」状態になりがちで、これが IP BAN の直接の引き金になります。
Scrapy をそのまま走らせると起きる 3 つの壁
- IP BAN: 同一 IP からの連続アクセスがレート制限に引っかかり、403 / 429 が返り始める
- CAPTCHA / アンチボット: Cloudflare、DataDome、PerimeterX といった防御層が介入し、HTML の代わりにチャレンジページが返る
- 地理ブロック: 地域別の価格・在庫を取りたいのに、アクセス元の国が固定されていて目的のコンテンツが出ない
これらは Scrapy の DOWNLOAD_DELAY や AUTOTHROTTLE だけでは根本解決できません。アクセス元の IP そのものを分散・制御する必要があります。
Bright Data が補うレイヤ
Bright Data は 4 億超 (195 か国) の Residential プロキシを中心に、Datacenter Proxy、Web Unlocker、Scraping Browser、SERP API といったデータ収集レイヤを一気通貫で提供します。Scrapy がアプリケーション層 (どの URL をどう辿るか) を担当し、Bright Data がインフラ層 (どの IP からどう見せるか) を担当する、という役割分担になります。
| Scrapy 単体の壁 | Bright Data の解消手段 |
|---|---|
| IP BAN / 403・429 | Residential / Datacenter プロキシで IP を分散・ローテーション |
| CAPTCHA / アンチボット | Web Unlocker が CAPTCHA・Cloudflare 等を自動突破 |
| JavaScript レンダリング不足 | Scraping Browser (CDP 接続) で実ブラウザ描画 |
| 地理ブロック | country-jp 等のゾーンパラメータで地域固定 IP を取得 |
Scrapy と他フレームワークの統合パターンを横断的に見たい場合は、Bright Data × Playwright 統合ガイド 2026で JavaScript 必須サイト向けの構成も整理しているので、対象サイトの性質に応じて使い分けてください。
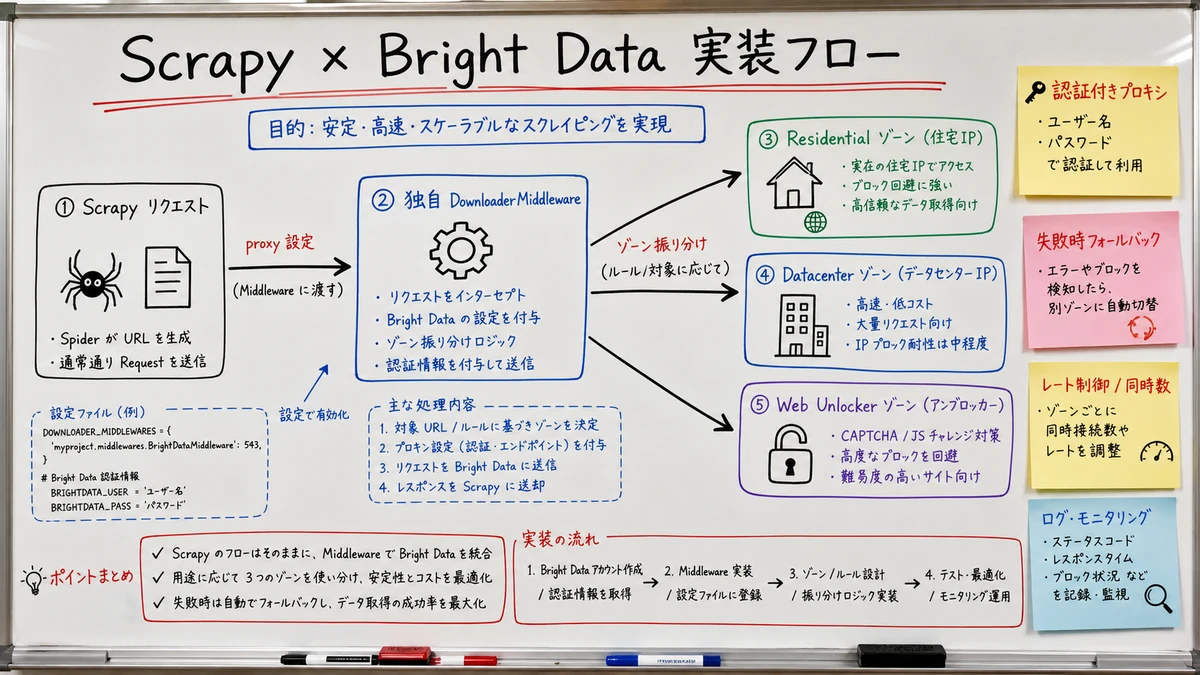
settings.py と DownloaderMiddleware でプロキシを組み込む
最初のステップは、Scrapy のリクエストすべてを Bright Data のプロキシ経由に通すことです。最小構成なら settings.py の追記だけで動きますが、運用を見据えるなら独自の DownloaderMiddleware に寄せます。
最小構成: settings.py の認証付きプロキシ
Bright Data の認証付きプロキシ URL を環境変数で受け取り、HttpProxyMiddleware に流す方式が最も手早い構成です。
# settings.py
import os
# brd-customer-<id>-zone-<zone> 形式のユーザー名 + Zone パスワード
BRIGHTDATA_USER = os.environ["BRD_USER"] # 例: brd-customer-xxx-zone-residential_jp
BRIGHTDATA_PASS = os.environ["BRD_PASS"]
BRIGHTDATA_HOST = "brd.superproxy.io:33335"
# 全リクエストを Bright Data 経由に
HTTPPROXY_ENABLED = True
CONCURRENT_REQUESTS = 16
DOWNLOAD_DELAY = 0.5
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_TARGET_CONCURRENCY = 4
RETRY_ENABLED = True
RETRY_TIMES = 3
ROBOTSTXT_OBEY = True
スパイダー側では request.meta['proxy'] に認証情報込みの URL を渡します。
proxy = f"http://{BRIGHTDATA_USER}:{BRIGHTDATA_PASS}@{BRIGHTDATA_HOST}"
yield scrapy.Request(url, meta={"proxy": proxy}, callback=self.parse)
この構成は PoC や検知の緩いサイトなら充分です。ただし、ゾーン切り替えやセッション制御を request ごとに変えたくなった時点で限界が来ます。
運用構成: custom DownloaderMiddleware
ゾーン選択・国指定・スティッキーセッションを一元管理するなら、独自ミドルウェアに集約します。
# middlewares.py
import os
import uuid
from scrapy.exceptions import NotConfigured
class BrightDataProxyMiddleware:
def __init__(self, user, password, host):
self.user = user
self.password = password
self.host = host
@classmethod
def from_crawler(cls, crawler):
user = crawler.settings.get("BRIGHTDATA_USER")
password = crawler.settings.get("BRIGHTDATA_PASS")
host = crawler.settings.get("BRIGHTDATA_HOST")
if not user or not password:
raise NotConfigured
return cls(user, password, host)
def process_request(self, request, spider):
# request.meta で国・セッションを上書きできるようにする
country = request.meta.get("brd_country", "jp")
session = request.meta.get("brd_session", uuid.uuid4().hex[:10])
username = f"{self.user}-country-{country}-session-{session}"
request.meta["proxy"] = f"http://{username}:{self.password}@{self.host}"
request.headers.setdefault(
"User-Agent",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36",
)
return None
settings.py 側で標準のプロキシミドルウェアを無効化し、自作のものを差し込みます。
DOWNLOADER_MIDDLEWARES = {
"yourproject.middlewares.BrightDataProxyMiddleware": 543,
"scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware": None,
}
要点は次の 3 つです。
request.meta["brd_country"]で対象ドメインごとに国を切り替えられるsession-<id>を固定すると同一 IP が保持され、ログインやページネーションに使える- User-Agent をミドルウェア側で補完しておくと、スパイダーの記述が軽くなる
ゾーン選択と IP ローテーションの設計
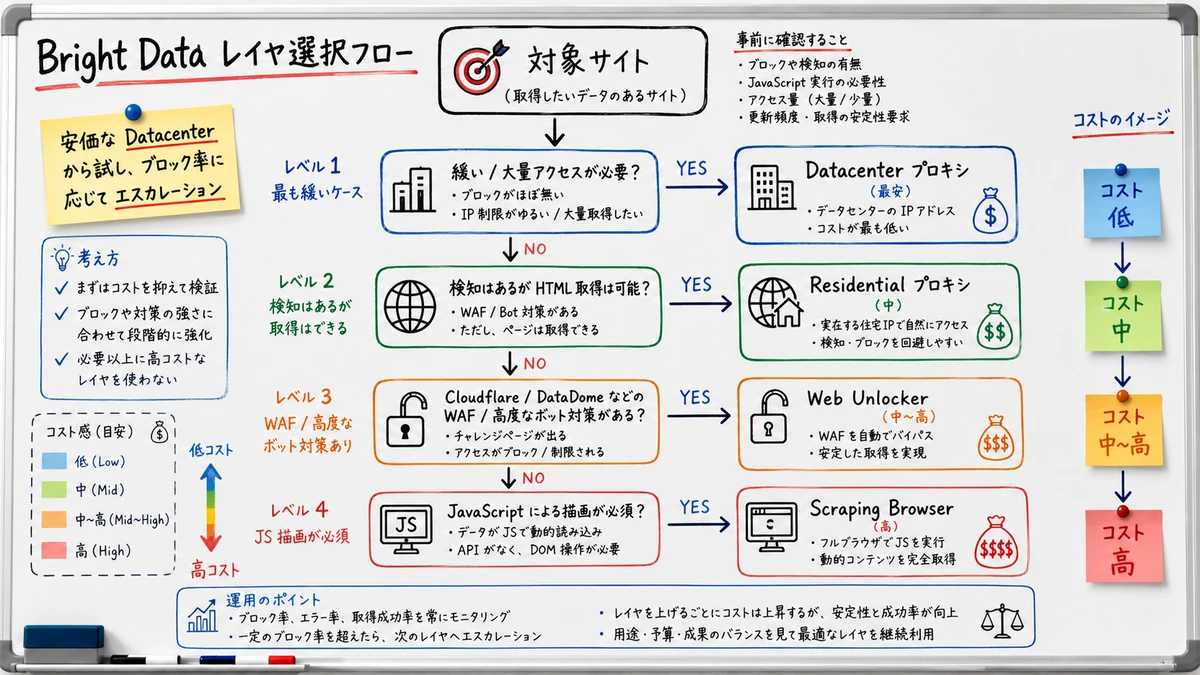
Bright Data 連携で最もコストと成功率を左右するのが、ゾーン (Zone) の選び方とローテーション戦略です。ここを雑に組むと、料金が膨らむかブロック率が上がるかのどちらかに振れます。
Residential か Datacenter か
ゾーンは大きく Residential (一般家庭の IP) と Datacenter (データセンター IP) に分かれます。
| 観点 | Residential | Datacenter |
|---|---|---|
| 料金 (2026 年時点) | $4/GB 〜 (約 640 円) | $0.4〜0.6/GB (約 64〜96 円) |
| 検知耐性 | 高い | 低め |
| 速度 | 中 | 速い |
| 向く対象 | 大手 EC・SNS・検知厳格サイト | 公開 API・緩い静的サイト・大量取得 |
実運用では「まず Datacenter で試し、403 / 429 やチャレンジが増えたら Residential に昇格させる」のが王道です。料金差が数倍 (おおむね 6〜7 倍) あるため、最初から全部 Residential にすると無駄が大きくなります。Datacenter ゾーンの並列度・帯域・コストの三軸設計はBright Data Datacenter Proxy 大量並列設計ガイド 2026で詳しく扱っています。
Scrapy 側でゾーンを振り分ける
ゾーンの切り替えは、ミドルウェアが参照するユーザー名の zone 部分を差し替えるだけで実現できます。スパイダーごとに別ゾーンを使う設計が分かりやすいです。
class PriceSpider(scrapy.Spider):
name = "price"
custom_settings = {
# 検知が厳しい EC は Residential ゾーン
"BRIGHTDATA_USER": "brd-customer-xxx-zone-residential_jp",
}
class ApiSpider(scrapy.Spider):
name = "public_api"
custom_settings = {
# 公開 API は安価な Datacenter ゾーン
"BRIGHTDATA_USER": "brd-customer-xxx-zone-datacenter_jp",
}
IP ローテーションの 2 パターン
- リクエストごとローテーション:
session-<id>を毎回新しく生成する。ページネーションや独立した一覧取得に向く - スティッキーセッション: 同じ
session-<id>を維持する。ログイン後の操作、カート、複数ステップのフローに必須
Bright Data 側のゾーン設定でセッションの最大保持時間が決まり、アイドル時間で IP がローテートされる仕様 (製品・設定により数分程度) のため、長時間フローでは IP 切り替えを前提に再ログインのリトライを組み込みます。
Scrapy にプロキシのローテーションとリトライを組み込むと、単体では落ちる規模のクロールでも安定して回せるようになる、という現場の声です (原文は英語の実装共有ポスト)。
Web Unlocker / Scraping Browser を併用する
プロキシだけでは突破できないサイトに当たったら、Bright Data の上位レイヤを Scrapy に併用します。対象ドメイン単位で「通常プロキシ → Web Unlocker → Scraping Browser」と段階的にエスカレーションするのが、コストと成功率のバランスが取りやすい設計です。
Web Unlocker (アンチボット自動突破)
Bright Data Web Unlocker は、CAPTCHA・Cloudflare・DataDome 等を自動突破する API です。Scrapy からは、対象ドメインだけ Web Unlocker のプロキシエンドポイント経由に切り替えるのが最も手間の少ない方法です。
def process_request(self, request, spider):
if request.meta.get("use_unlocker"):
# Web Unlocker ゾーンのエンドポイントに切り替え
user = "brd-customer-xxx-zone-web_unlocker"
request.meta["proxy"] = f"http://{user}:{self.password}@{self.host}"
return None
Web Unlocker は成功したリクエストに対してのみ課金 ($1.5/1,000 リクエスト〜、月額ティアで $1 まで) されるため、難関サイトに絞って使うとコスト効率が良くなります。CAPTCHA の種類別対処や成功率の上げ方はBright Data Web Unlocker 実践活用ガイド 2026に詳しくまとめています。
Scraping Browser (JavaScript レンダリング)
JavaScript で描画される SPA や、ブラウザ挙動が必須のサイトは、Scraping Browser を使います。Scrapy 単体では JS を実行できないため、scrapy-playwright 経由で Bright Data の Scraping Browser に CDP 接続する構成が定番です。
# settings.py
DOWNLOAD_HANDLERS = {
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
PLAYWRIGHT_CDP_URL = "wss://USER:PASS@brd.superproxy.io:9222"
これで、フィンガープリント制御・CAPTCHA 自動解決をすべて Bright Data 側に任せたまま、Scrapy のスパイダー記述・パイプライン・アイテム定義をそのまま使えます。Scraping Browser のコスト設計はBright Data Scraping Browser 実践活用ガイド 2026で整理しています。
3 レイヤの使い分け早見表
| 対象サイトの性質 | 推奨レイヤ | コスト感 |
|---|---|---|
| 構造が緩く大量取得したい | Datacenter プロキシ | 最安 |
| 検知あり・HTML で取れる | Residential プロキシ | 中 |
| Cloudflare / DataDome で守られている | Web Unlocker | 中〜高 |
| JavaScript レンダリング必須 | Scraping Browser | 高 |
リトライ・エラーハンドリングと大規模並行クロール
Bright Data を挟んでも、スクレイピングは失敗が前提の処理です。失敗をどう拾い、どうリトライし、どこまで並列化するかが、本番運用の安定性を決めます。
ステータスコード別のリトライ設計
Scrapy 標準の RetryMiddleware に加えて、プロキシ起因のエラーを賢く扱う設計にします。
- 403 / 429 (ブロック・レート制限):
session-<id>をローテートして別 IP で再試行する - 407 (プロキシ認証エラー): ユーザー名フォーマットか Zone パスワードの誤り。リトライせず即時に検知して止める
- 5xx / タイムアウト: 指数バックオフ + ジッターで 3〜5 回まで再試行する
# settings.py
RETRY_HTTP_CODES = [403, 429, 500, 502, 503, 504, 522, 524]
RETRY_TIMES = 4
リトライのたびにセッション ID をローテートする実装にしておくと、ブロックされた IP を避けて再試行できます。指数バックオフ・ジッター・サーキットブレーカーの実装パターンはBright Data のリトライ戦略とレート制限設計ガイド 2026で具体的に解説しています。
大規模並行クロールのチューニング
数十万 URL 規模になると、Scrapy 側の並列度と Bright Data 側の帯域・同時接続数の両方を見る必要があります。
CONCURRENT_REQUESTSとCONCURRENT_REQUESTS_PER_DOMAINで並列度を制御するAUTOTHROTTLE_ENABLEDでサーバー負荷に応じた自動調整を効かせる- 画像・CSS を取らない設計 (Scrapy は HTML 中心にしやすい) で GB を節約する
- 失敗 URL を SQS / Redis などのキューに永続化し、別バッチで再投入する
大規模クロールでは、プロキシ品質とリトライ設計がそのまま成功率に直結する、という指摘です (原文は英語のスクレイピング運用に関するポスト)。
スクレイピング基盤として完成させる
Scrapy × Bright Data の構成は、PoC を素早く立ち上げるには充分です。ただし本番運用では、ゾーンごとのコスト監視、失敗 URL の再投入キュー、取得データの正規化と Snowflake / BigQuery への投入まで含めて、データ収集パイプラインとして完成させる必要があります。
弊社では、Bright Data の Residential プロキシと Web Unlocker を使ったホテル価格追跡サービス Tra-bell を自社で運用しています。Scrapy / Playwright での並行クロール、ゾーン設計、失敗ハンドリング、Snowflake へのデータ投入まで含めた基盤を、PoC から本番運用への移行段階で伴走するノウハウがあります。既存 Scrapy プロジェクトの Bright Data 化 (プロキシ導入・Web Unlocker / Scraping Browser 移行) もご相談可能です。
まとめ
Bright Data を Scrapy に組み込むと、IP BAN・CAPTCHA・地理ブロックという Scrapy 単体の壁を、インフラ層で一気に解消できます。実装は「settings.py の認証付きプロキシ → 独自 DownloaderMiddleware → ゾーン選択 → IP ローテーション → Web Unlocker / Scraping Browser 併用 → リトライ設計」の順で段階的に育てるのが定石です。
まずは安価な Datacenter ゾーンで PoC を回し、ブロック率に応じて Residential や Web Unlocker へ昇格させる運用が、コストと成功率のバランスを取りやすい現実解です。本記事のコード片はそのまま改変して使えるので、手元の Scrapy プロジェクトで試してみてください。
※情報は 2026-06-01 時点の内容です。最新情報は公式サイトをご確認ください。
※本記事には PR を含みます。
よくある質問
関連記事

Bright Data × Playwright 統合ガイド 2026 - プロキシ設定からスクレイピング実装まで

Bright Data Web Unlocker 実践活用ガイド 2026 - CAPTCHA突破とコスト設計